








Abstract
1. Introduction

1.1 CNNs及其局限性
图像修复在于去除低质量图片上的噪音以重建高质量的图片,而修复图像需要强大的图像先验。CNNs在学习广尺度数据的泛化先验上有着良好的性能,故近年出现了很多基于CNNs的方法,和传统修复方法相较,人们更偏爱于前者。“卷积”是CNN基本操作,它能够提供局部连接和平移等方差,这使得其带来在效率和泛化能力上提升的同时,也导致了两个问题:
-
卷积操作的感受野有限,这使得它不能建立大范围的像素关系。
-
卷积过滤的权重在理论推导时是静态的,因此不能随着输入内容的变化而变化。
为了解决这个问题,动态、强大的自注意力机制(SA)是一个很好的选择,它能够通过给输入像素赋予不同权重再求和来计算对应输出。
1.2 自注意力机制(SA:self-attention)
自注意力机制是Transformer的核心组件,它的实现和CNN不同。例如,多头注意力对并行化和高效表征学习进行了优化。Transformer在自然语言处理、高层视觉等任务上有着state-of-the-art的性能。
尽管SA在捕获广域像素交互上性能较好,但是它的复杂度会随着空间分辨率的提高呈平方式增长,故直接将其用于高分辨率图像处理(通常是图像修复)上是不可行的。最近有将transformer调整应用于图像修复上的工作【13,43,79】.为了减小计算负荷,这些方法要么将SA用于每个像素周围8x8的小空间窗口,要么将输入图像分割成无重叠的48x48的块,再在单个块上计算SA。但是这对SA空间内容的限制和捕获真正的广域像素关系是相违背的,特别是对于高分辨率图像来说。
1.3 主要模块和创新点(包含第三部分的)
本论文提出了能对整体连接关系建模且适用于大尺度图像的高效transformer模型
- 我们提出了一种encoder-decoder Transformer,用于在高分辨率图像上进行多尺度局部-全局表征学习,而不将它们分解为局部窗口,从而利用了大范围内的图像上下文。
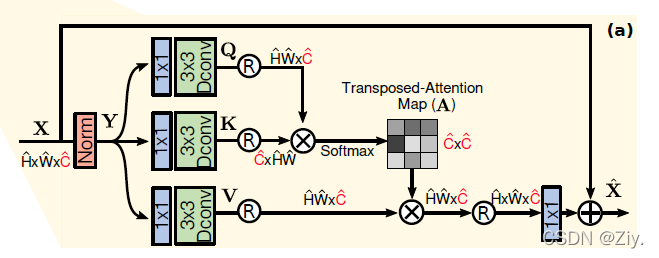
1.3.1 多反卷积头转置注意力(MDTA,multi-Dconv head transposed attention)模块:
-
介绍:
MDTA替代了普通的multi-head SA(transformer模块计算量的主要来源),MDTA有着线性的复杂度。它跨特征维度使用SA,而不是在空间维度使用SA。例如MDTA不是显式地对 成对像素的交互 建模,而是计算跨特征通道的交叉协方差,从(键和查询投影的)输入特征中获得注意力特征图。
MDTA块一个重要的特点是在计算特征协方差之前混合局部上下文。通过 使用1x1卷积进行跨通道上下文的像素级整合、使用高效的depth-wise卷积进行局部上下文的通道级聚合。这一策略主要有两个优点:
(1) 它强调了空间局部上下文,并在pipeline中引入了卷积运算的互补优势
(2) 它确保了在计算基于协方差的注意力特征图时,像素之间上下文化的全局关系是隐式建模的该模块能够聚合局部和非局部像素交互,并足够有效地处理高分辨率图像。
-
公式
(1)用一个归一化张量层结合局部上下文来 Y Y Y生成 Q ( q u e r y ) , K ( k e y ) , V ( v a l u e ) Q(query),K(key),V(value) Q(query),K(key),V(value)映射:使用 1x1卷积( W p ( ⋅ ) W^{(\centerdot)}_p Wp(⋅)) 整合像素间跨通道上下文,再用 3x3的depth-wise卷积( W d ( ⋅ ) W^{(\centerdot)}_d Wd(⋅)) 对通道级空间上下文进行编码,生成:
1x1卷积( W p ( ⋅ ) W^{(\centerdot)}_p Wp(⋅))、 3x3的depth-wise卷积( W d ( ⋅ ) W^{(\centerdot)}_d Wd(⋅))
在网络中,我们使用bias-free卷积层
(2) 对Q,K进行reshape,得出它们的dot-product interaction生成转置注意力特征图 A A A(transposed-attention map)

(3) 整体流程

α
\alpha
α为可学习的尺度参数,用于在输入softmax之前控制 K,Q点积的量级。
和常规的多头注意力机制类似,我们将通道数分为head,并且并行地学习分离的注意力特征图。
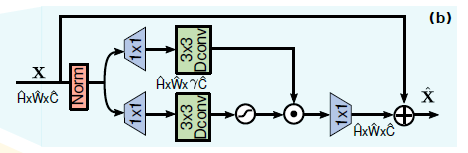
1.3.2 前馈网络栅格- 反卷积前馈网络(GDFN:Gated-Dconv FeedForward Network)
-
介绍:
前馈网络(FN:feed-forward network)是transformer的另一个组成模块,用于转换特征,由两个全连接层夹着一个非线性激活函数(ReLu)组成。 常规FN先用两个1x1卷积,一个用于扩展特征通道( γ = 4 \gamma = 4 γ=4),另一个用于将通道数减少到原始输入维度。GDFN基于类似于MDTA模块的局部内容混合,同样强调空间上下文。GDFN中的门控机制控制哪些互补特征应该向前流动,并让网络层次中的后续层专门关注更精细的图像属性,从而产生高质量的输出。使用depth-wise卷积对空间上相邻的像素信息编码,有利于修复时学习局部图像结构。
也就是说,与MDTA相比,GDFN 专注于用上下文信息丰富特性。由于本文提出的GDFN与常规的FN[17]相比执行的操作更多,因此我们降低了扩展比 γ \gamma γ,使其具有相似的参数和计算量。
GDFN执行受控的特征转换,即抑制信息量较小的特征,只允许有用的信息通过网络层次进一步传递。
-
公式
本文用门控机制(gating mechanism)重新定义了常规FN的第一个线性转换层,门控层被设计为两个线性投影层的元素积(element-wise product),其中一个用GELU非线性[26]激活。给定输入张量 X X X,GDFN公式定义为:


⨀ \bigodot ⨀表示元素积乘法(element-wise multiplication), ϕ \phi ϕ表示 GELU 非线性函数,LN即层归一化(layer normalization), X ^ \hat X X^为输出 -
整体流程
2. Background
Image Restoration
- 基于U-Net的encoder-decoder结构:主要用于图像恢复,因为其层级多尺度表征并且计算高效。
- Skip connection:图像恢复,特别关注残差信号的学习
- Spatial and channel attention:整合入模型中,有选择性地学习相关信息
Vision Transform(VIT)
最初用于自然语言处理,最近在CV多个领域表现性能良好
VIT将图片分解为一系列的块(局部窗口)并学习它们的相互关系,然而,在transformer中,SA的计算复杂度会随着图像块的数量呈平方增长,因此无法应用于高分辨率图像。
一个潜在的补救方法是使用Swin Transformer设计在局部图像区域内应用自我注意机制。然而,这种设计选择限制了在局部区域内的上下文聚合,违背了使用自注意而不是卷积的主要动机,因此不适合用于图像恢复任务。
3. Method
为了缓解计算瓶颈,我们引入了多头SA层( multi-head SA layer)的关键设计,以及一个比单尺度网络计算需求更小的多尺度分层模块(multi-scale hierarchical module)
整体框架
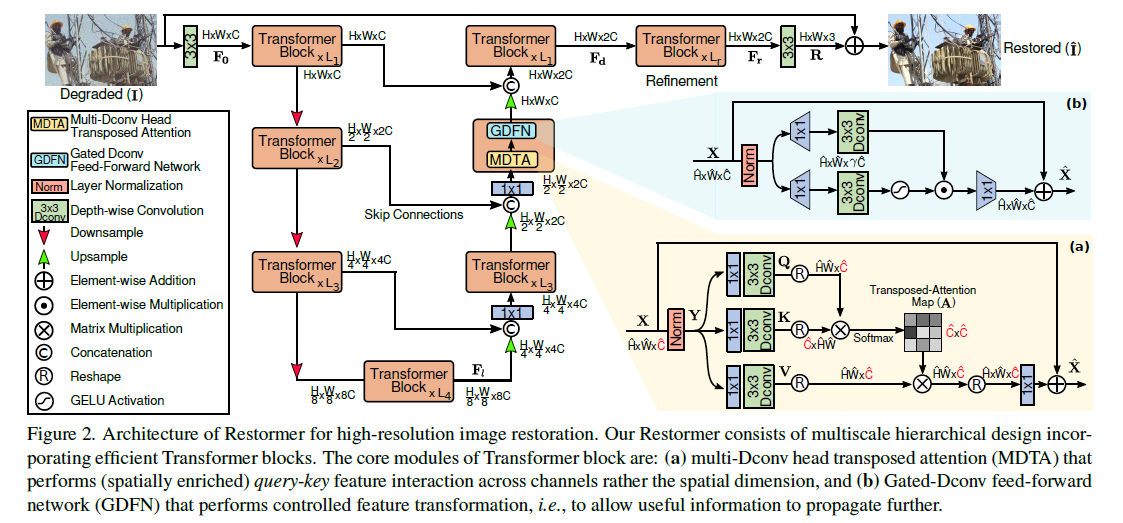
-
输入图像 I ∈ R H ∗ W ∗ 3 I \in R^{H*W*3} I∈RH∗W∗3,先卷积得到低级特征嵌入 F 0 ∈ R H ∗ W ∗ C , C 为 通 道 数 F_0 \in R^{H*W*C} , C为通道数 F0∈RH∗W∗C,C为通道数。再将浅层特征传到4层对称encoder-decoder,转换成深层特征 F d ∈ R H ∗ W ∗ 2 C F_d \in R^{H*W*2C} Fd∈RH∗W∗2C。每层encoder-decoder都包含多个Transformer块,块数量从高到低层递增来保证其效率。
-
从高分辨率输入开始,编码器分层地减少空间大小,同时扩大通道容量。Decoder将低分辨率潜在特征
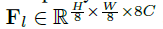 当作输入并逐步恢复高分辨率表征。
当作输入并逐步恢复高分辨率表征。 -
对于特征下采样和上采样,我们采用不打乱像素(pixel-unshuffle)和打乱像素(pixel-unshuffle)操作。为了有利于图像恢复过程,编码器特性(encoder)通过跳过连接(skip connection)连接到解码器特性(decoder)。连接后进行1x1卷积来对除最顶层外所有层的通道数减半。在level-1,我们让Transformer块将编码器的低级图像特征与解码器的高级特征聚合在一起。这种方法有利于在恢复后的图像中保持精细的结构和纹理细节。
-
然后,在高空间分辨率的细化阶段进一步丰富深度特征Fd,这样设计能够提高图片质量。
-
最后在精细处理后的特征上进行一次卷积来生成残差图像 R ∈ R H ∗ W ∗ 3 R \in R^{H*W*3} R∈RH∗W∗3,将其与输入 I I I相加得恢复图像
主要组件
-
multi-Dconv head transposed attention(MDTA) 整体框架中的(a)
-
gated-Dconv feed-forward network (GDFN). 整体框架中的(b)
-
details on the progressive training scheme for effectively learning image statistics:
基于cnn的恢复模型通常训练在固定大小的图像块上。然而,在裁剪的图像块上训练Transformer模型可能不能对全局图像信息进行编码,因此在测试时在全分辨率图像上提供suboptimal performance。为此,我们进行渐进式学习,在早期阶段用较小的图像块对网络进行训练,在后期训练阶段用逐渐增大的图像块对网络进行训练。
通过渐进学习在混合大小的块上训练的模型在测试时有性能上的提升,而图像可以具有不同的分辨率(图像恢复的常见情况)。渐进式学习策略的行为方式与课程学习过程类似,即网络从一个较简单的任务开始,逐渐过渡到一个较复杂的任务(需要保留精细的图像结构/纹理)。由于对large patches训练需要花费更长的时间,所以随着块增大,我们减小了batch size,以便在每个优化步骤中保持与训练固定大小块相同的时间。
4. Experiment and Analysis
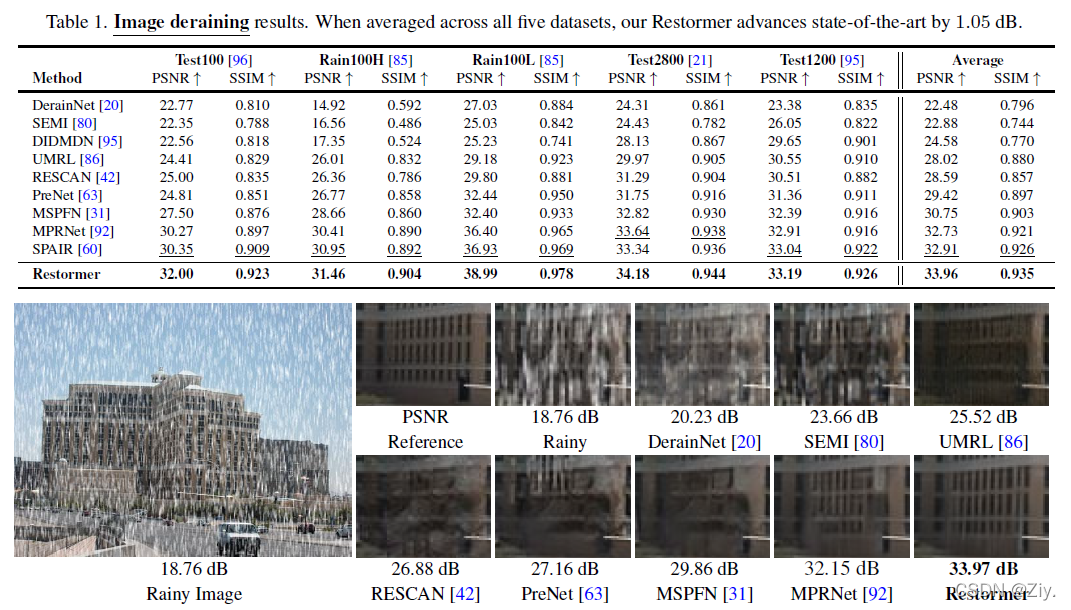
4.1 去雨完胜
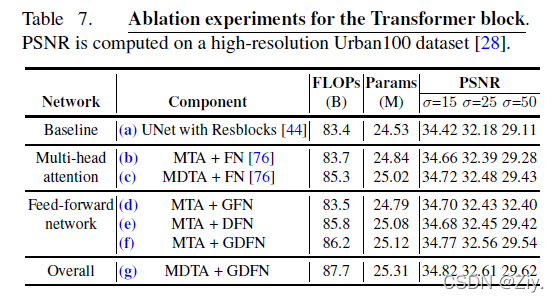
4.5 消融实验


















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









