







输入 ——卷积——非线性——卷积——非线性——输出
forward
def forward(self,x):
x = F.relu(self.conv1(x)) # conv 第一次卷积 1是一维 relu第一次非线性
return F.relu(self.conv2(x))
nn.Module的使用
import torch
from torch import nn
class Didi(nn.Module):
def __init__(self):
super().__init__() # Module的一个初始化
def forward(self,input):
output = input + 1
return output
didi = Didi()
x = torch.tensor(1.0) # 将1.0这个数转换成rensor数据类型
output = didi(x)
print(output)卷积操作
| 1 | 2 | 0 | 3 | 1 |
| 0 | 1 | 2 | 3 | 1 |
| 1 | 2 | 1 | 0 | 0 |
| 5 | 2 | 3 | 1 | 1 |
| 2 | 1 | 0 | 1 | 1 |
| 1 | 2 | 1 |
| 0 | 1 | 0 |
| 2 | 1 | 0 |
| 1 | 2 | 0 | 3 | 1 | ||
| 0 | 1 | 2 | 3 | 1 | ||
| 1 | 2 | 1 | 0 | 0 | ||
| 5 | 2 | 3 | 1 | 1 | ||
| 2 | 1 | 0 | 1 | 1 | ||
红色部分对应相乘并相加,根据步长向右、下移动,新的对应相乘并相加,得到一个新的矩阵。padding里空的部分默认值为0
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1,], #有几个[]就是几维
[0,1,2,3,1,],
[1,2,1,0,0,],
[5,2,3,1,1,],
[2,1,0,1,1,]])
kernel = torch.tensor([[1,2,1,],
[0,1,0,],
[2,1,0,]])
input = torch.reshape(input,(1,1,5,5)) # 是平面,通道数是1,batch size大小是1,数据纬度是5*5
kernel = torch.reshape(kernel,(1,1,3,3,)) # reshape()里要求输入四个参数 转变数据形式
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1) # stride 代表步长,卷积核一次移动几个长度
print(output)
output2 = F.conv2d(input,kernel,stride=2)
print(output2)
output3 = F.conv2d(input,kernel,stride=1,padding=1)
# padding 在上下左右扩容,并认为扩容的地方数为0
print(output3)输出
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
tensor([[[[10, 12],
[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
Process finished with exit code 0
卷积层
输入图像只有一层 In_channel = 1 彩色图像 In_channel= 3
一个卷积核 Out_channel = 1
两个卷积核 Out_channel = 2 得到两个输出(卷积核不一定一样大)
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=dataset,download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Didi(nn.Module):
def __init__(self):
super(Didi,self).__init__() #父类的初始化
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x = self.conv1(x)
return x
didi = Didi()
print(didi)
writer = SummaryWriter("111")
step = 0
for data in dataloader:
imgs,targers = data
output = didi(imgs)
print(imgs.shape)
print(output.shape)
writer.add_images("input",imgs,step)
output = torch.reshape(output, (-1, 3, 30, 30))
# torch.Size([64, 6, 30, 30])因为有6个通道,彩色图像只有三个通道,所以要变成三个通道
# —1 根据后面的值进行计算(不知道值的时候使用)
writer.add_images("output", output, step)
step = step + 1
writer.close()池化层
最大池化
| 1 | 2 | 0 | 3 | 1 |
| 0 | 1 | 2 | 3 | 1 |
| 1 | 2 | 1 | 0 | 0 |
| 5 | 2 | 3 | 1 | 1 |
| 2 | 1 | 0 | 1 | 1 |
| 2 | 3 |
| 5 | 1 |
ceil_mode = True
| 2 |
ceil_mode = False
stride 默认跟池化核层数一样为3
选取最大的数作为输出
ceil_mode 为False 走三步后多余的数不进行操作
为True 走三不后多余但不足的数选最大的作为输出
import torch
import torchvision.transforms
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1,]],dtype=torch.float32) # 变成浮点数,1变成1.0
input = torch.reshape(input,(-1,1,5,5,))
print(input.shape)
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
# stride 默认为跟数值kernel_size一样
# ceil_mode = True 保留不符合规则的数据
def forward(self,input):
output = self.maxpool1(input)
return output
didi = Didi()
output = didi(input)
print(output)#最大池化的目的是保留输入的一个特征同时把数据量减小 就像是视频的清晰度,清晰度不高也能满足人看视频的需求
对图片的池化就类似于马赛克
import torch
import torchvision.transforms
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train = False , download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
didi = Didi()
writer = SummaryWriter("maxpool")
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = didi(imgs) # 池化不会改变图片维数
writer.add_images("output",output,step)
step = step + 1
writer.close()非线性激活
ReLU
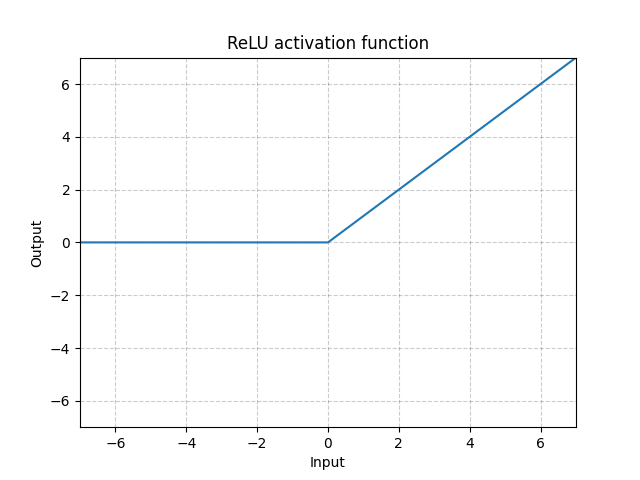
Input = -1 Input = -1
ReLU(input,inplace = True) Output = ReLU(input,inplace = False)
Input = 0 Input = -1 Output = 0
inplace代表是否替换input
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.relu1 = ReLU()
def forward(self,input):
output = self.relu1(input)
return output
didi = Didi()
output = didi(input)
print(output)SIGMOID
Sigmoid(x)=σ(x)=1/(1+exp(−x))
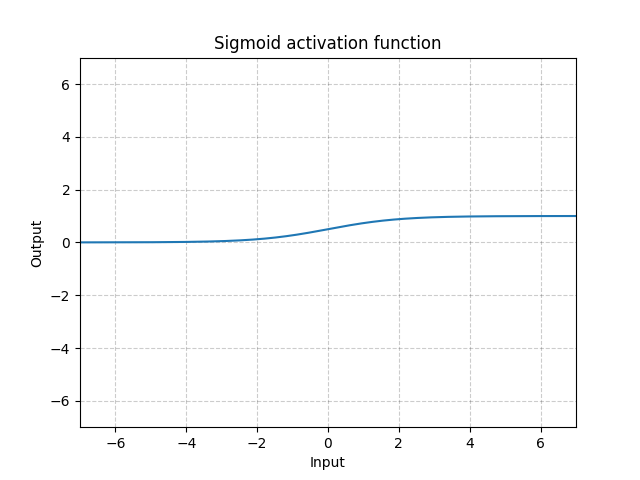
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
dataset = torchvision.datasets.CIFAR10("./dataset",train = False , download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self,input):
output = self.sigmoid1(input)
return output
didi = Didi()
step = 0
writer = SummaryWriter("sigmoid")
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = didi(imgs)
writer.add_images("output",output,step)
step = step + 1
writer.close()线性层
vgg16
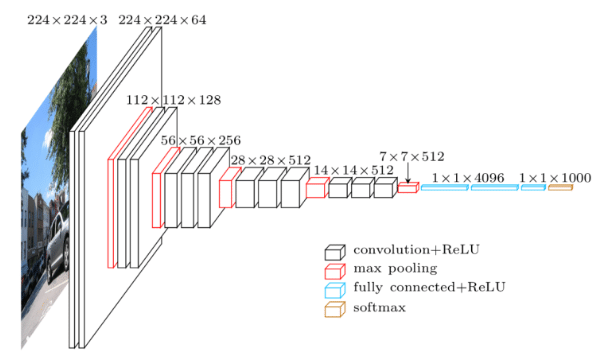
7*7*512转换成1*1*4096在转换成1*1*1000
| 1 | …… | 25 |
线性层
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
didi = Didi()
for data in dataloader:
imgs,targets = data
print(imgs.shape)
output = torch.flatten(imgs)
# 展平,相当于output = torch.reshape(imgs,(1,1,1,-1))
print(output.shape)
output = didi(output)
print(output.shape)输出
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
Sequential 的使用
cifar10 model structure
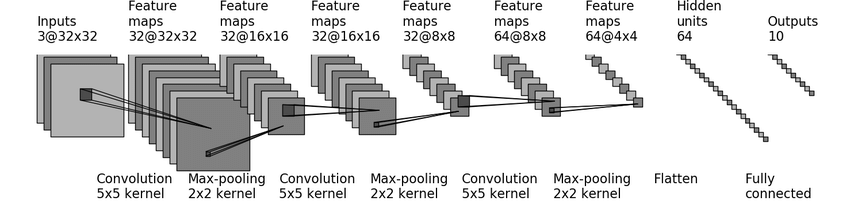

= 32
dilation 默认是1 因为不是空洞卷积
kernel_size = 5
= 32
因为padding没有很大所以推出stride = 1 paddiing = 2
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.conv1 = Conv2d(3,32,5,padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32,32,5,padding=2 )
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten() # 展平
self.linear1 = Linear(1024,64)
self.linear2 = Linear(64,10)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
didi = Didi()
print(didi)
input = torch.ones((64,3,32,32)) # 检查网络正确性
output = didi(input)
print(output.shape)利用Sequential
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Didi(nn.Module):
def __init__(self):
super(Didi, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x
didi = Didi()
print(didi)
input = torch.ones((64,3,32,32)) # 检查网络正确性
output = didi(input)
print(output.shape)
writer = SummaryWriter("123")
writer.add_graph(didi,input)
writer.close()














 5928
5928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









