



前言
最近小朋友开始学习跑酷,这段动画是我用他上课时候的一段练习视频制作的。利用sd和EbSynth进行配合将它加工成动画质感,当然除了二次元之外,它还可以进行很多不同风格的转绘。
传统的转绘流程是将视频里的所有画面进行逐帧转绘,再拼接起来,这样做的结果就是绘制速度很慢,而且画面的闪烁会很严重,因为AI绘制的画面会非常的不稳定。而在EbSynth当中,我们的流程就有了一些的改变,首先是使用插件将视频拆帧和抠出蒙版,然后提取出图片中动作幅度变化比较大的几幅作为关键帧并进行风格转绘,最后再利用EbSynth绘制出中间的过渡帧,最后再将输出的所有画面组合成完整的视频就可以了。

理解了这个原理,接下来我就将通过这篇文章来全面地介绍EbSynth插件从安装到使用的整个流程。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~

#****01
安装流程
首先,我们先下载这个流程的核心程序EbSynth,它的网址为:https://ebsynth.com/。点击Download下载压缩包。
下载完成之后,将压缩包解压到一个文件夹里即可,这个软件我们要到最后几步才能用到,先留在这里。
接下来是安装EbSynth在WebUI中的一个扩展插件Ebsynth Utility,我们的整个流程都将围绕这个插件来进行,下载地址为:https://github.com/s9roll7/ebsynth_utility。也可以到SD的扩展列表中去下载,下载完成之后,安装重启即可,这里就不多赘述了。
安装成功后就可以看到这个界面了。
接下来装第三个东西——FFmpeg,它是一款轻量级的用于视频编解码的工具。下载地址为:http://ffmpeg.org/download.html。
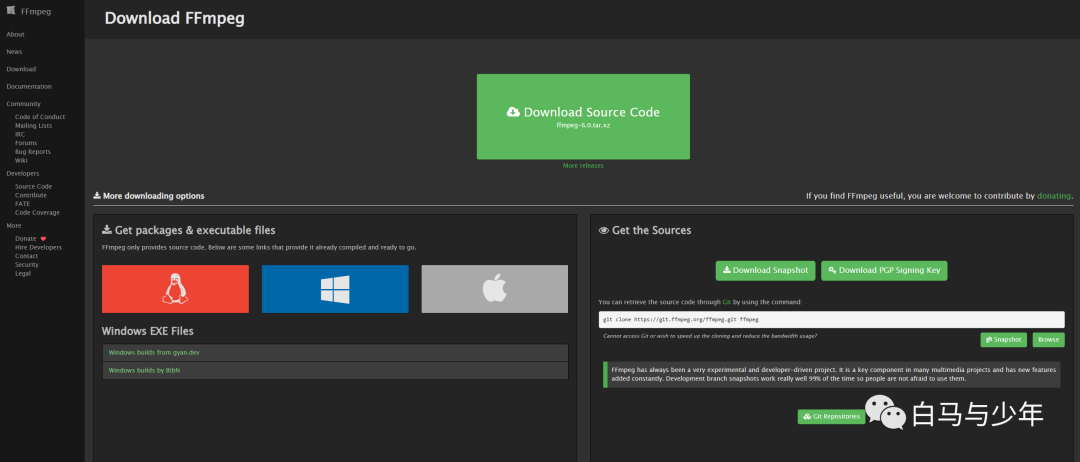
点击win的图标下面的Windows builds from gyan.dev。
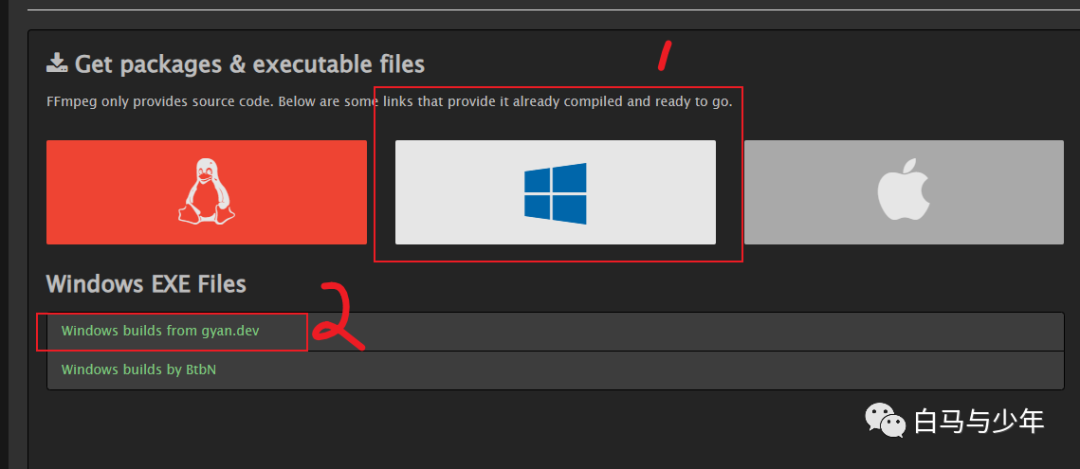
然后点击ffmpeg-git-full.7z进行下载。
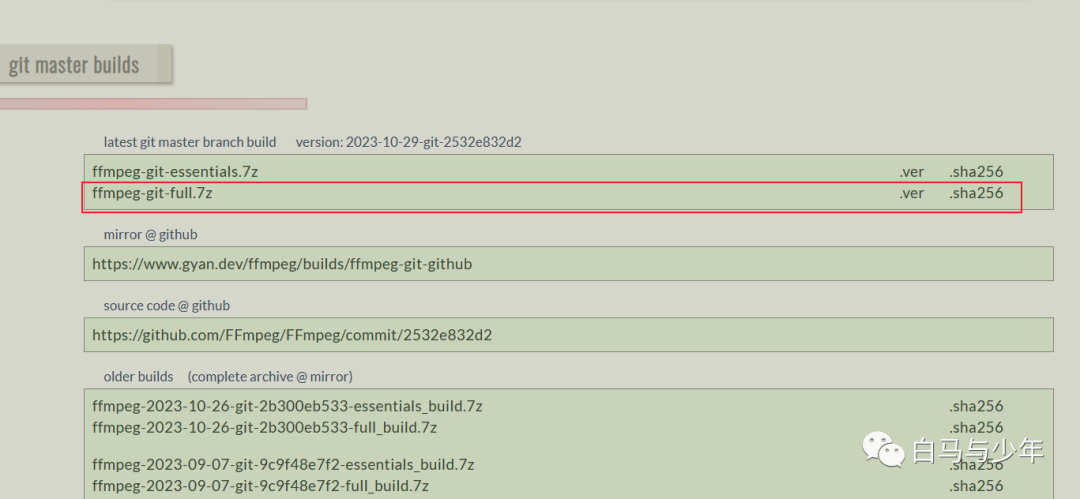
将下载的压缩包解压到一个文件夹中备用。
接下来,我们来到win的开始菜单中搜索“环境变量”。
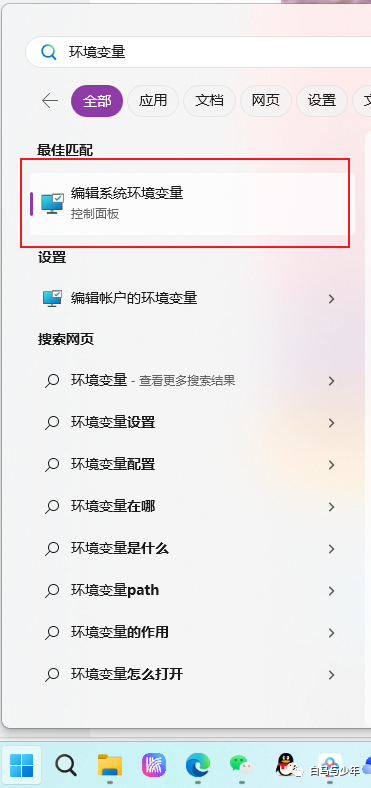
点击“环境变量”。
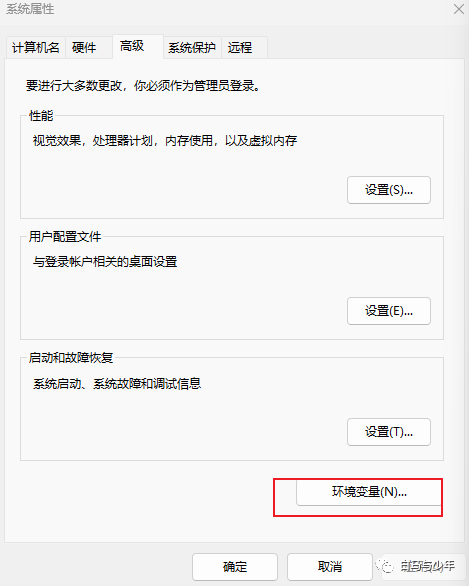
在“系统变量”中选择“Path”,点击“编辑”。
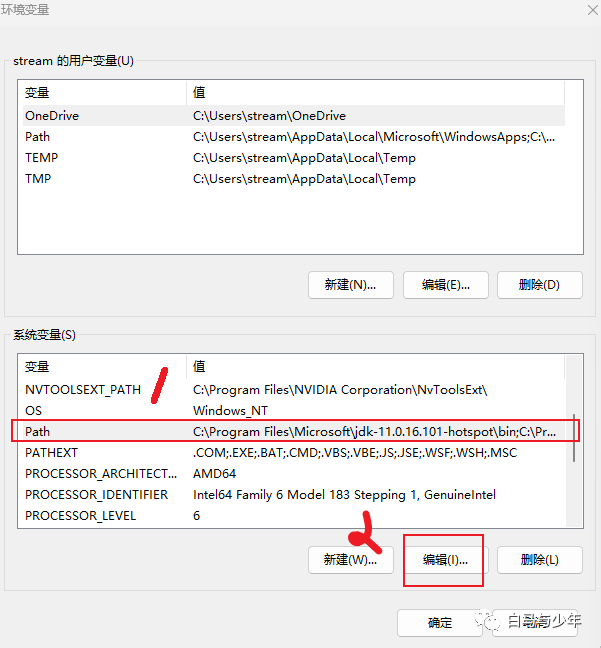
依次点击“新建”——“浏览”
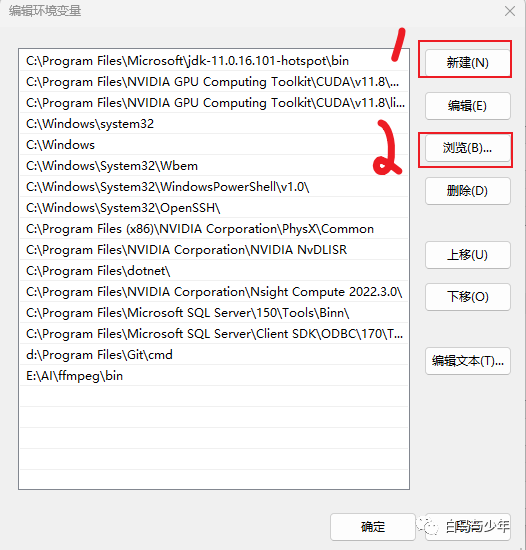
找到我们刚才下载的“ffmpeg”里的“bin”文件夹。
这样就添加好了。然后把刚才所有的窗口全部点确定。
重启电脑,在开始菜单中搜索“cmd”,打开命令提示符。
输入“ffmpeg -version”
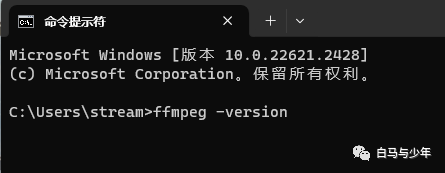
看到一下版本信息,就表示我们已经安装好了。
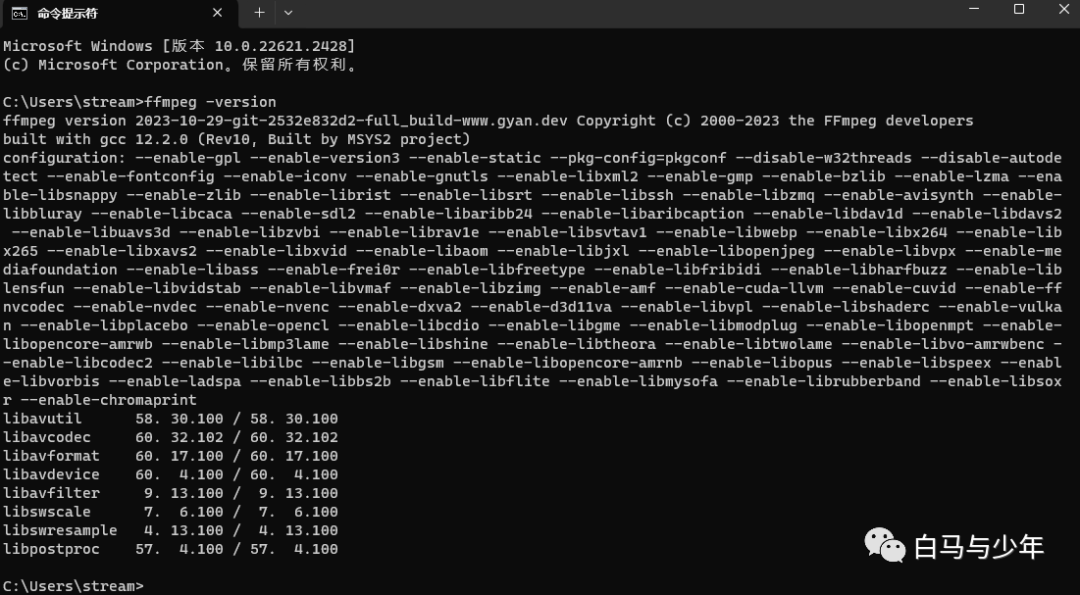
最后,需要在我们的电脑上安装一个transparent background,它的主要作用是来帮助我们提取蒙版的。网址为:https://pypi.org/project/transparent-background/#files。
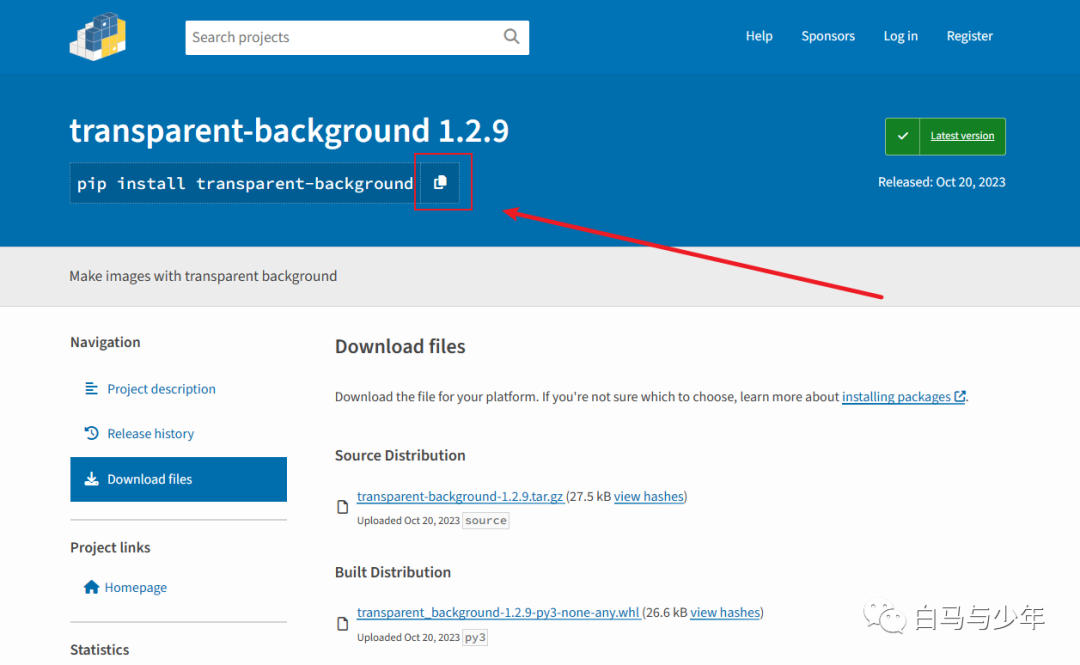
我们复制这段代码,粘贴到cmd当中,回车。
等待安装完成就可以了。
如果这一步安装出现问题的,大概是因为秋叶整合包中的python是单独的,我们可以打开秋叶整合包中的python文件夹,然后选中文件夹地址栏,全选为蓝色,删除后,输入CMD,然后出现以下:
E:\Stable Diffusion V4\sd-webui-aki-v4.4\python>
然后再输入python.exe -m pip install transparent-background,也就是:
E:\Stable Diffusion V4\sd-webui-aki-v4.4\python>-m pip install transparent-background
然后就可以成功安装了。
#****02
**视频分帧与蒙版添加
**
首先,我们先选取一段视频,不要太长,我这里找了一个表演飞天的舞者,长度20秒。尺寸720x1280。

接下来新建一个“feitian”的文件夹,注意路径上不要有中文,文件夹的名字也不要有特殊符号。
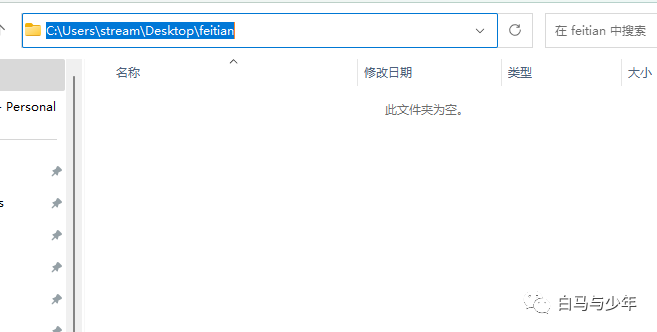
填写好项目文件夹地址,并放入视频。
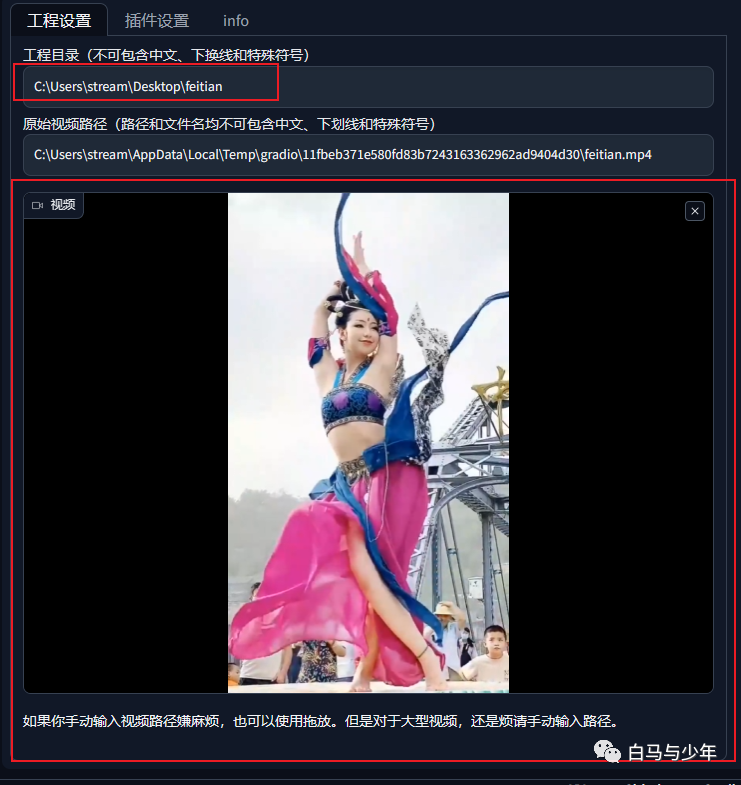
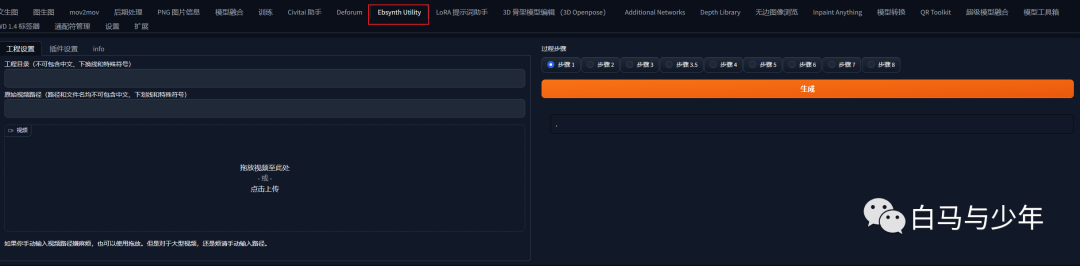
接下来,我们来到“插件设置”,步骤一主要是进行拆帧和抠像。如果你希望将人物抠出来的话,可以将两个“蒙版阈值”分别设置为0.04和0.4,如果你只是拆帧,后面人物和背景一起转绘,则可以不设置。
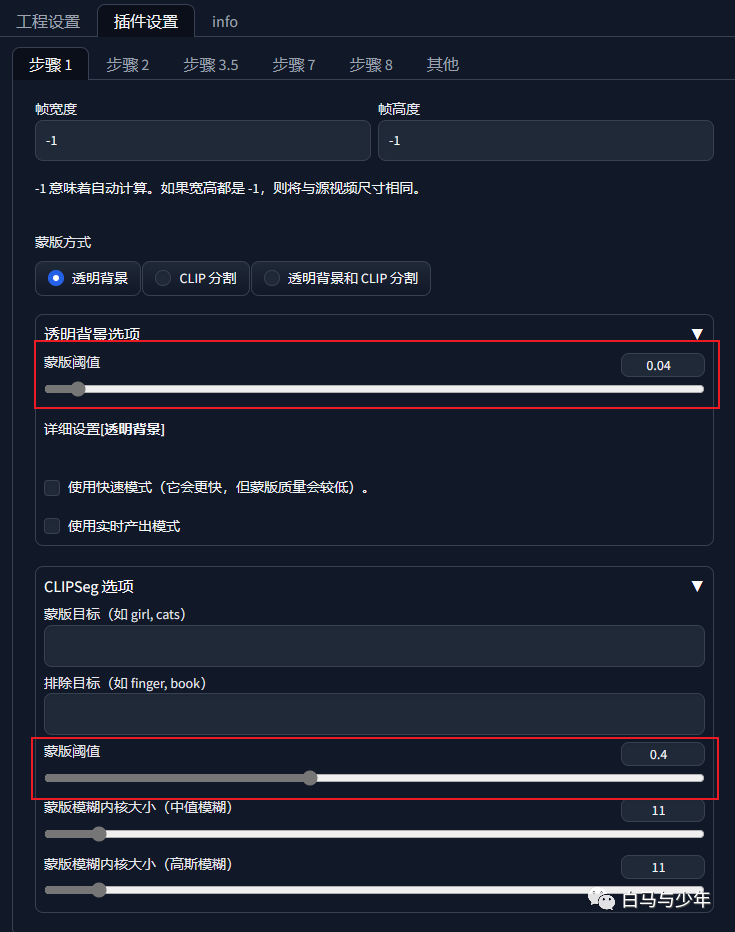
点击生成,后台就会开始运算了。
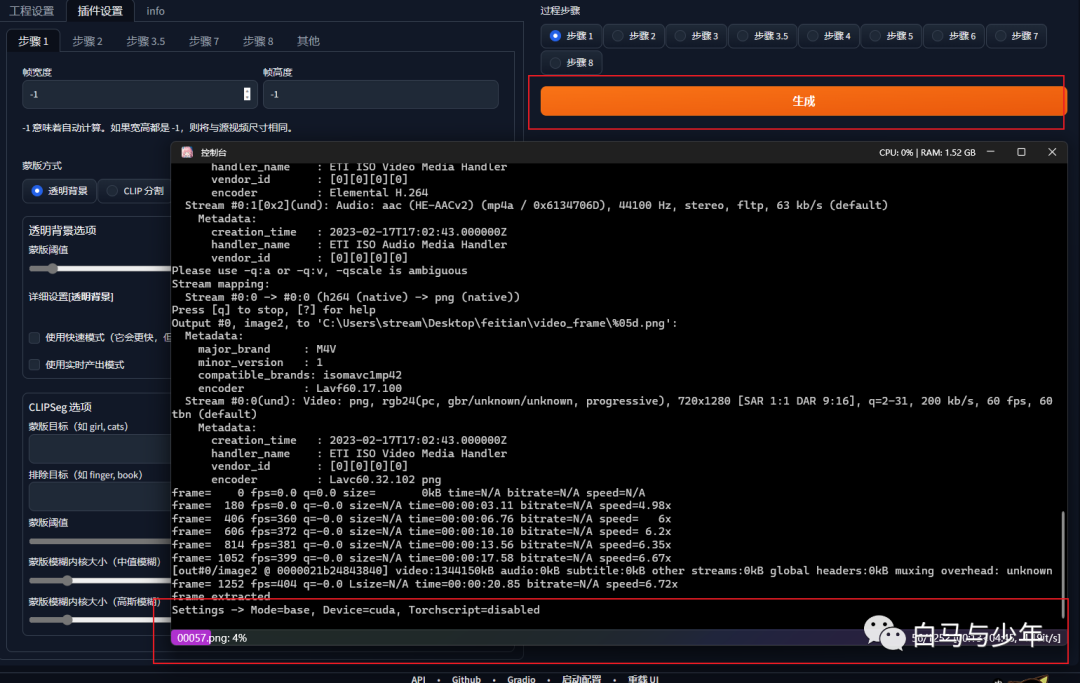
生成完毕之后,我们的“feitian”文件夹里就会出现两个新的文件夹。
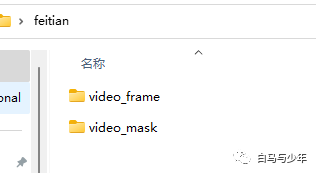
它们分别是逐帧拆分的图片。
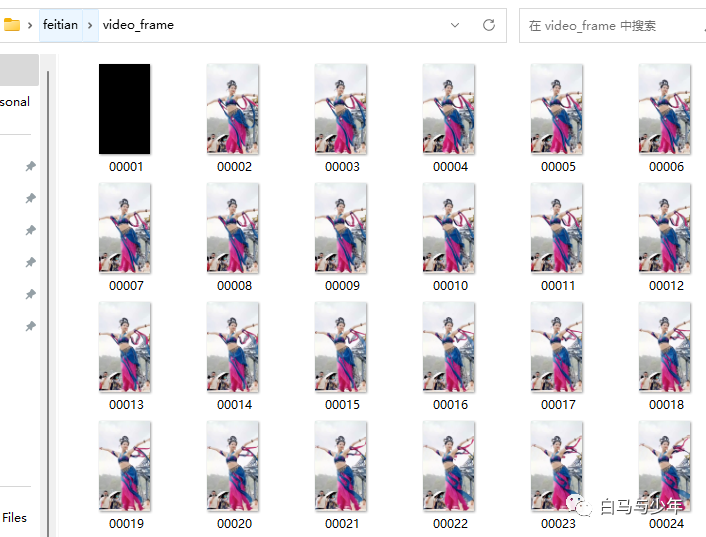
和对每一帧的抠像蒙版。

#****03
提取关键帧
第二步就是从这些众多的图片中,提取出变化较大的图片作为关键帧,可以通过设置关键帧的间隔来控制。间隔越小,关键帧越多,视频越流畅,但是渲染时间更长。
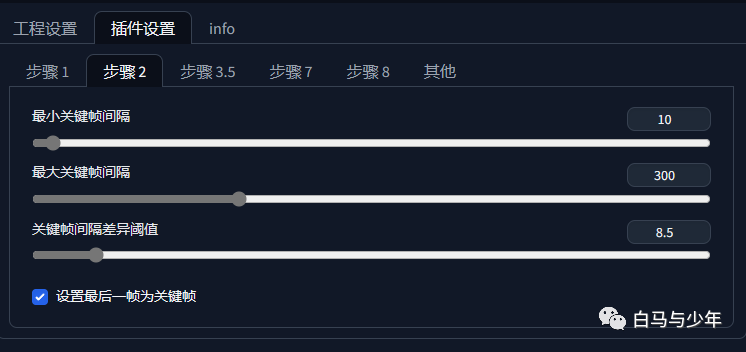
点击生成,文件夹中又会多一个提取出来的关键帧文件夹。
#****04
图片转绘
来到图生图当中,选取其中一帧图片,选择合适的模型和参数,进行二次元的转绘,还可以加入controlnet进行控制。
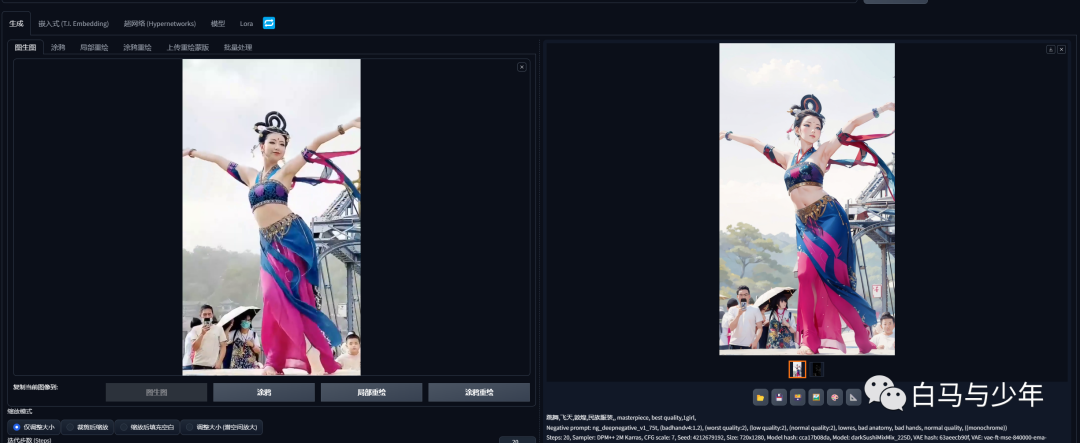
对比一下原图和转绘后的效果。


如果对这个结果很满意,就可以将种子保存下来。

接下来打开“ebsynth utility”脚本,填好工程目录,其它参数可以保持不变,如果需要连背景一起重绘的话,可以关掉蒙版模式。
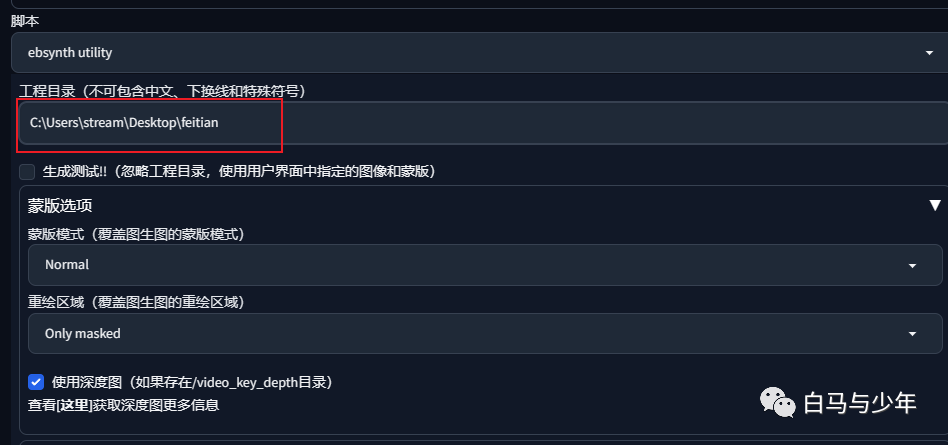
点击生成,就会开始对我们所有的关键帧进行图生图重绘。
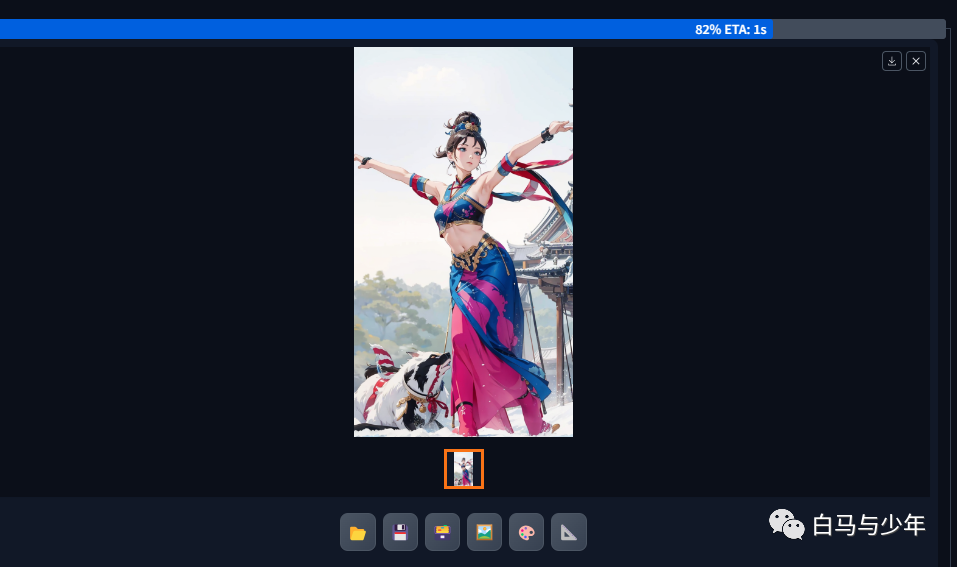
生成完毕之后,我们就又多了一个文件夹,里面就是所有关键帧的转绘。
#****05
图像放大
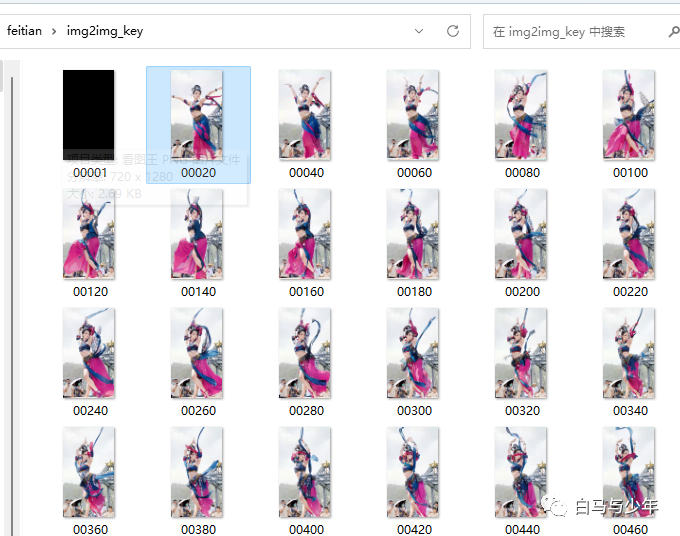
进入到“后期处理”当中,对刚才生成的图片进行批量处理。填入输入目录和输出目录,图片尺寸和原视频一样,放大算法选对应二次元的。
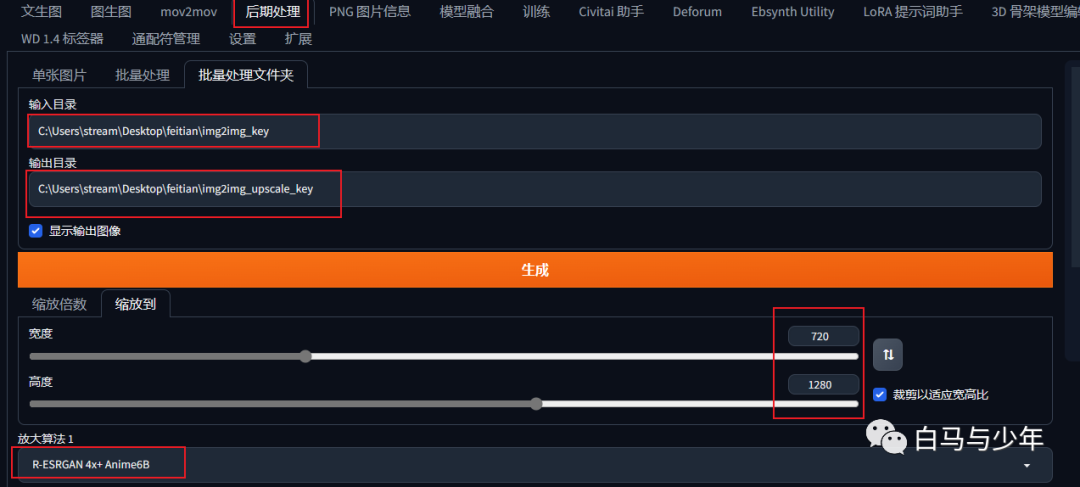
经过这一步处理,虽然图像大小没变,但是图片会清晰很多。

#****06
绘制过渡帧
直接点击生成就好了。
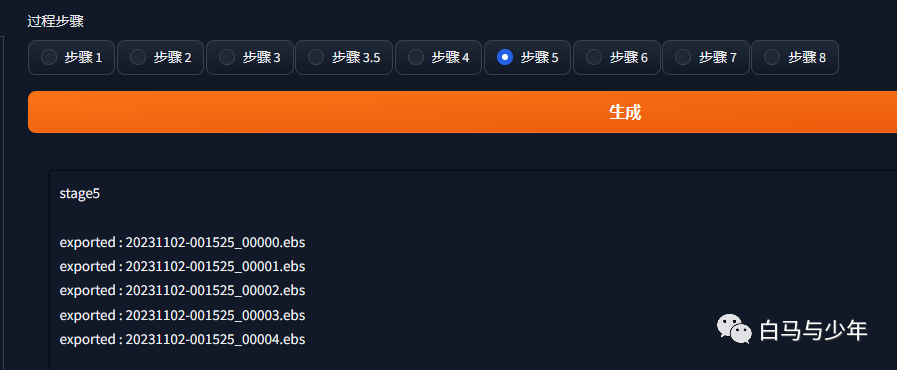
文件夹里面就会生成关于关键帧的ebs文件,这个数量是根据视频的长度定的,短的可能只有一个。
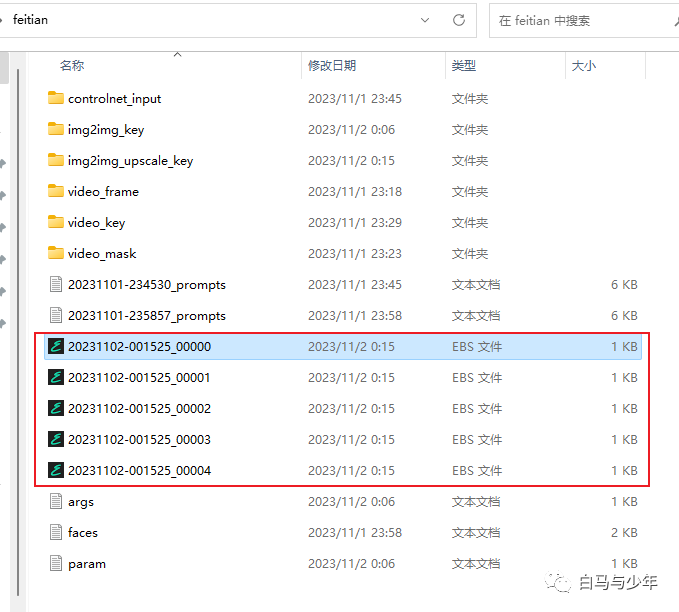
这个时候就要打开我们一开始下载的那个ebsynth的文件了,这里主要是利用它的算法,给我们的每帧之间添加过渡帧。
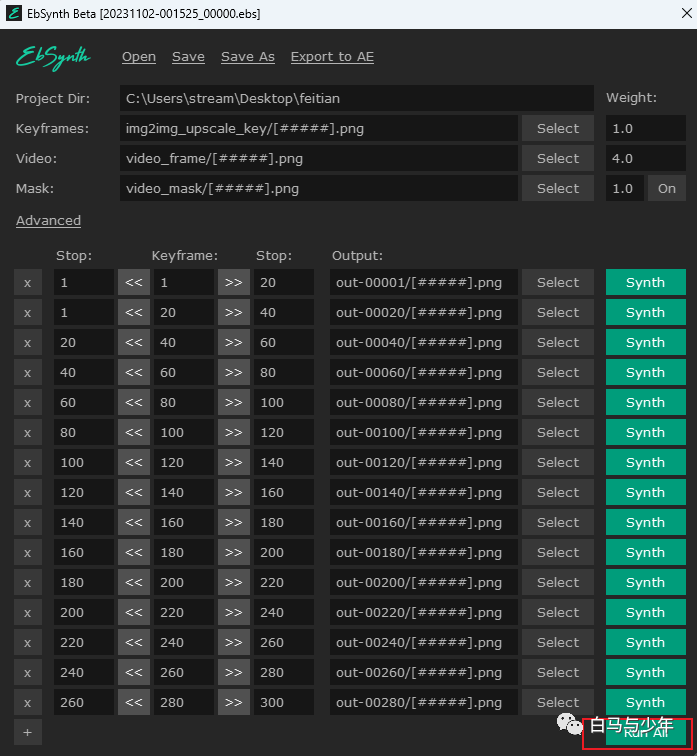
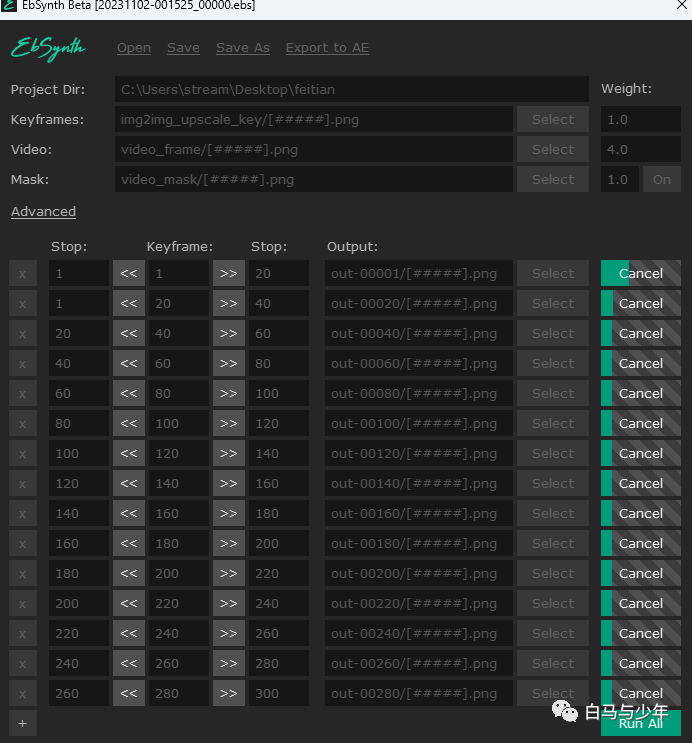
点击下面的“run all”,软件就会自动开始绘制了。我们要把刚才的5个ebs文件全部运行完。
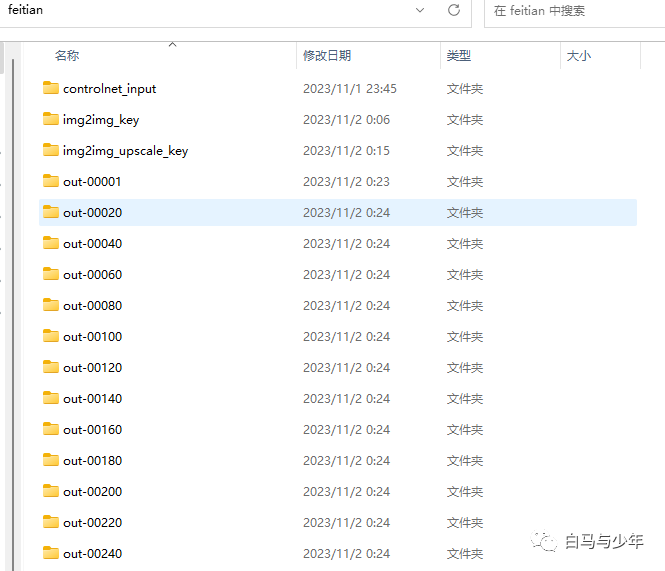
新生成的过渡帧都会形成这样的文件夹,里面就是AI脑补出来的画面。
#****07
视频合成
选择输出格式,点击生成,等待即可。
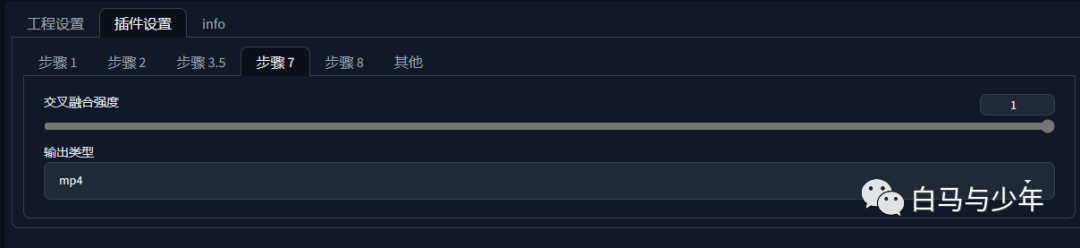
会生成两个格式,一个是没声音的,一个是有声音的。
来看看最终的效果吧。

以上,就是使用EbSynth进行AI视频制作的安装方法和使用全流程。它的优势就是使用EbSynth绘制过渡帧,从而减少了视频的闪烁,搞懂整个原理我们就能去灵活运用了。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









