






本文中的剪枝采用的是通道剪枝,为离线剪枝的一种,也就是可以直接对已经训练好的模型进行剪枝后再微调训练,不用稀疏训练【也就是不用边训练边剪枝】。
剪枝参考的paper:Pruning Filters for Efficient ConvNets。
相关剪枝原理部分可以参考我另一篇文章:YOLOv4剪枝【附代码】_爱吃肉的鹏的博客-CSDN博客_yolo剪枝
本文主要实现:
1.可训练自己的数据集
2.对单独某一个卷积的剪枝,
3.对某些层的剪枝。
PS:最终的效果本文并不保证,需要根据自己剪枝方案进行评估,剪的地方不同以及剪枝率的不同都会有影响,本文只是把功能进行了实现。这里需要说一下的是,我在实际测试的时候,发现YOLOR其实并没多好,而且参数量也挺大的,所以大家选这个算法要慎重。
目录
本文暂时不讲YOLOR的理论部分【有些细节我也还在研究】。
clone代码至本地后可以先测试一下:
git clone https://github.com/YINYIPENG-EN/Pruning_for_YOLOR_pytorchcd Pruning_for_YOLOR_pytorch
python detect.py --source inference/images/horses.jpg --cfg cfg/yolor_csp.cfg --weights yolor_csp.pt --conf 0.25 --img-size 640 --device 0
训练部分代码讲解:
YOLOR的训练代码和其他YOLO系列差不多。这一部分将会分块说明训练代码中各个模块的功能【如果不想看这一部分可以略去】
训练参数说明:
首先看一下参数部分,这里只说一些经常用到的。
--weights 是权重路径
--cfg 网络结构配置路径
--data 数据集yaml配置路径
--hyp 训练期间超参数的配置路径
--epochs 训练总的epochs
--batch-size batch size大小
--img-size 输入网络的图像大小
--nosave 如果开启该功能,只保存最后一轮的训练结构,关闭该功能则每epoch都保存
--notest 开启后只对最后一轮进行测试,关闭该功能则轮都测试
--device 设备id,如果只有一个GPU,设置为0
--adam 采用adam优化器训练,默认为SGD
--pt 剪枝后的微调训练
--period 测试mAP的周期,默认为每两轮测试一此mAP
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolor_csp.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='cfg/yolor_csp.cfg', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.640.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--workers', type=int, default=4, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--pt', action='store_true', default=False, help='pruned model train')
parser.add_argument('--period', type=int, default=2, help='test period')
opt = parser.parse_args()训练阶段:
训练阶段的代码会调用train()函数,主要是hyp【超参数】,opt【传入参数】,device【设备】。
# Train
logger.info(opt)
if not opt.evolve:
tb_writer = None # init loggers
if opt.global_rank in [-1, 0]: # tensorboard的写入
logger.info(f'Start Tensorboard with "tensorboard --logdir {opt.project}", view at http://localhost:6006/')
tb_writer = SummaryWriter(opt.save_dir) # Tensorboard
train(hyp, opt, device, tb_writer, wandb) # 训练过程相关路径代码:
# Directories
wdir = save_dir / 'weights' # 保存路径
wdir.mkdir(parents=True, exist_ok=True) # make dir
last = wdir / 'last.pt' # 最后一次权重
best = wdir / 'best.pt' # 最好的权重
results_file = save_dir / 'results.txt' # 结果txt路径(记录训练过程)保存训练过程参数的yaml文件
# 保存训练过程中的参数文件,方便中断训练,yaml格式
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.dump(vars(opt), f, sort_keys=False)相关配置
相关配置包括了是否开启绘图功能、yaml文件的读取,获取训练集、验证集,类的数量。
# 相关配置
plots = not opt.evolve # create plots
cuda = device.type != 'cpu'
init_seeds(2 + rank) # 初始化随机种子
with open(opt.data) as f: # 读取数据集的yaml文件
data_dict = yaml.load(f, Loader=yaml.FullLoader) # data dict
with torch_distributed_zero_first(rank): # 分布式的初始化
check_dataset(data_dict) # check 检查数据集
train_path = data_dict['train'] # 读取训练集
test_path = data_dict['val'] # 读取验证集
# nc:类的数量,names:类名
nc, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names']) # number classes, names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # checkModel的定义
包含了预权重的加载以及model的定义,其中opt.pt的含义是是否采用剪枝微调训练。
# Model的相关定义
pretrained = weights.endswith('.pt') # 读取预训练权重
if pretrained:
if opt.pt:
ckpt = torch.load(weights)
model = ckpt['model']
model.to(device)
else:
with torch_distributed_zero_first(rank):
attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Darknet(opt.cfg).to(device) # 创建网络
state_dict = {k: v for k, v in ckpt['model'].items() if model.state_dict()[k].numel() == v.numel()}
model.load_state_dict(state_dict, strict=False) # 加载预权重
print('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # report
else:
model = Darknet(opt.cfg).to(device) # createoptimizer相关配置代码
这里包括了常用的优化器以及超参数配置代码,代码默认采用的SGD【Adam发现有时候在剪枝训练的有问题,还没搞清楚什么问题】。
# Optimizer相关配置
nbs = 64 # nominal batch size
accumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decay
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in dict(model.named_parameters()).items():
if '.bias' in k:
pg2.append(v) # biases
elif 'Conv2d.weight' in k:
pg1.append(v) # apply weight_decay
elif 'm.weight' in k:
pg1.append(v) # apply weight_decay
elif 'w.weight' in k:
pg1.append(v) # apply weight_decay
else:
pg0.append(v) # all else
if opt.adam: # 采用adam优化器
optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else: # SGD优化器
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
# https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html#OneCycleLR
lf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - hyp['lrf']) + hyp['lrf'] # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
# plot_lr_scheduler(optimizer, scheduler, epochs)optimizer 预权重加载:
start_epoch, best_fitness = 0, 0.0
# 精确率p,召回率R,AP50,AP,F值,存储预权重模型参数
best_fitness_p, best_fitness_r, best_fitness_ap50, best_fitness_ap, best_fitness_f = 0.0, 0.0, 0.0, 0.0, 0.0
if pretrained: # 如果加载预权重的相关配置
# Optimizer 加载预权重中的参数继续训练
# if opt.pt:
# ckpt['optimizer'] = None
if ckpt['optimizer'] is not None:
optimizer_dict = optimizer.state_dict()
pred_optimizer = ckpt['optimizer'] # 获得优化器参数
pred_optimizer = {k: v for k, v in pred_optimizer.items() if np.shape(optimizer_dict[k]) == np.shape(pred_optimizer[k])}
#optimizer.load_state_dict(ckpt['optimizer'])
optimizer.load_state_dict(optimizer_dict)
best_fitness = ckpt['best_fitness']
best_fitness_p = ckpt['best_fitness_p']
best_fitness_r = ckpt['best_fitness_r']
best_fitness_ap50 = ckpt['best_fitness_ap50']
best_fitness_ap = ckpt['best_fitness_ap']
best_fitness_f = ckpt['best_fitness_f']
# Results
if ckpt.get('training_results') is not None:
with open(results_file, 'w') as file:
file.write(ckpt['training_results']) # write results.txt
# Epochs
start_epoch = ckpt['epoch'] + 1
if opt.resume: # 继续中断后的训练
assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)
if epochs < start_epoch:
logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %
(weights, ckpt['epoch'], epochs))
epochs += ckpt['epoch'] # finetune additional epochs
if opt.pt:
del ckpt
else:
del ckpt, state_dict训练集的加载
# Trainloader 训练集的加载
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect,
rank=rank, world_size=opt.world_size, workers=opt.workers)
"""
dataset中的label形式:【类,box】
"""
mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label class
nb = len(dataloader) # number of batches
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, opt.data, nc - 1)验证集的加载
# Process 0
if rank in [-1, 0]:
ema.updates = start_epoch * nb // accumulate # set EMA updates
# 测试集的加载
testloader = create_dataloader(test_path, imgsz_test, batch_size*2, gs, opt,
hyp=hyp, cache=opt.cache_images and not opt.notest, rect=True,
rank=-1, world_size=opt.world_size, workers=opt.workers)[0] # testloader绘制labels
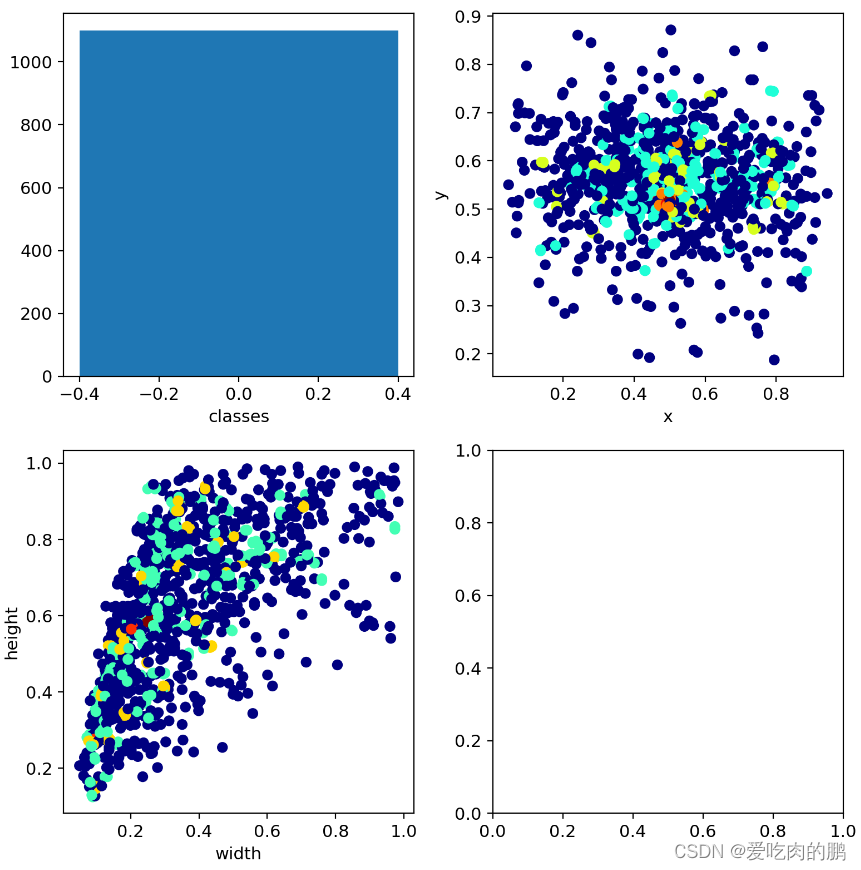
该功能是通过plot_labels函数进行实现的。该功能将会绘制3个子图:
1.柱状图:横坐标为classes,纵坐标为数据集中各个类的数量;
2.散点图:将所有boxes的center_x,center_y进行绘制,可以看target的中心点分布情况【这里是进行了归一化的】,横坐标是center_x,纵坐标是center_y;
3.散点图:绘制数据集所有boxes的w,h,横坐标为width,纵坐标为height;
if plots: # 是否开启绘制功能
"""
该函数会绘制3个子图:
1.柱状图:横坐标为classes,纵坐标为数据集中各个类的数量
2.散点图:将所有boxes的center_x,center_y进行绘制,可以看target的中心点分布情况【这里是进行了归一化的】,横坐标是center_x,纵坐标是center_y
3.散点图:绘制数据集所有boxes的w,h,横坐标为width,纵坐标为height
"""
plot_labels(labels, save_dir=save_dir) # 绘制标签效果图如下:
第一幅图反应了当前训练数据集中总的目标数【我这里只有一个类】。第二个图是我所有图像中中心点坐标的分布情况,横坐标是center_x,纵坐标是center_y。第三幅图是图像的height和width分布。第四图就是一个空白图而已。
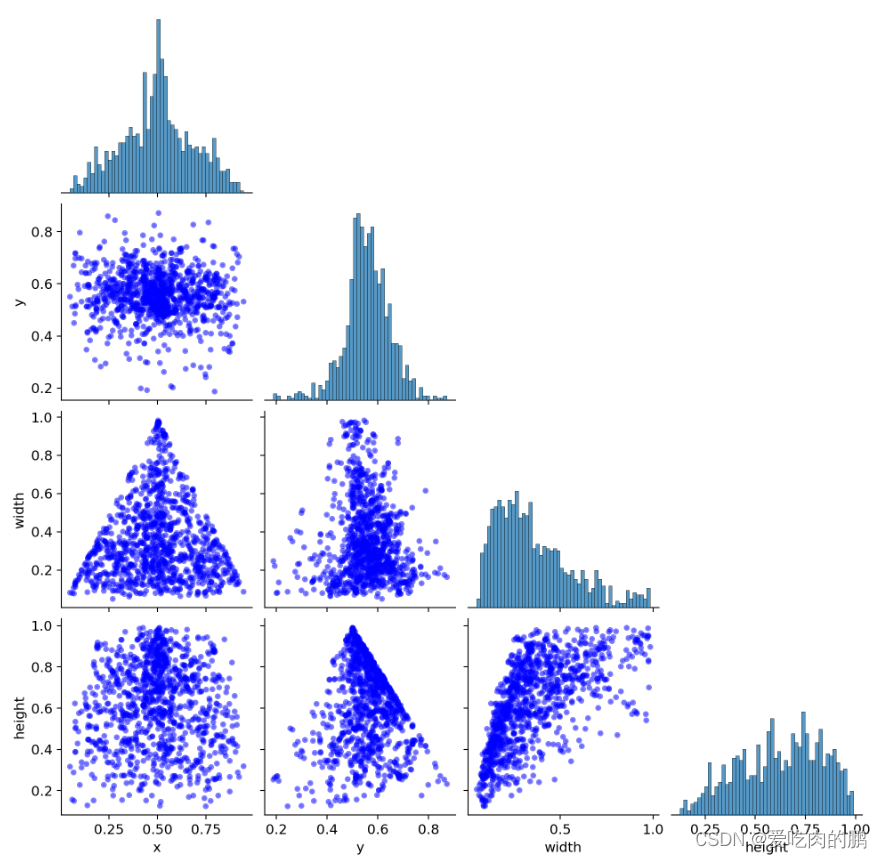
同时还会再绘制一个label_correlogram.png的图像,这副图绘制的是label中各个属性的相关性。
主对角线的柱状图是各自属性的相关性,其他的则是不同属性间的相关分布。有关代码如下:
import seaborn as sns
import pandas as pd
x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
sns.pairplot(x, corner=True, diag_kind='hist', kind='scatter', markers='o',
plot_kws=dict(s=3, edgecolor=None, color='b', linewidth=3, alpha=0.5),
diag_kws=dict(bins=50))
plt.savefig(Path(save_dir) / 'labels_correlogram.png', dpi=200)
plt.close()
"""
此时b的形式为:box1:center_x, center_y, w, h
box2:center_x, center_y, w, h.....
使用pd.DataFrame,生成数据表:
_________________________________________
| x | y | width | height |
| center_x |center_y | w | h |......
sns.pairplot主要展现的是变量两两之间的关系(线性或非线性,有无较为明显的相关关系)
diag_kind:控制对角线上的图的类型,可选"hist"与"kde"
kind:用于控制非对角线上的图的类型,可选"scatter"与"reg",参数设置为 "reg" 会为非对角线上的散点图拟合出一条回归直线,更直观地显示变量之间的关系。
markers:控制散点的样式
plot_kws:用于控制非对角线上的图的样式
diag_kws:用于控制对角线上图的样式
绘制出来的图祝对角线是各自属性的直方图,非对角线是不同属性间的相关性
"""
训练
从下面的代码开始就是正式的训练代码。包含了损失函数的计算,前向传播和反向传播,以及各个权重的保存,这里的权重会保存best.pt(权衡了mAP@.5,mAP@0.5~.95),last.pt,以及精确率P最高的权重,召回率R最高的权重等,可能大家会注意到保存的权重很大,这是因为里面还保存了优化器中的权重所以会保存的大一些。
# 从下面开始就是正式训练
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional)
if opt.image_weights:
# Generate indices
if rank in [-1, 0]:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Broadcast if DDP
if rank != -1:
indices = (torch.tensor(dataset.indices) if rank == 0 else torch.zeros(dataset.n)).int()
dist.broadcast(indices, 0)
if rank != 0:
dataset.indices = indices.cpu().numpy()
# 存储mean loss
mloss = torch.zeros(4, device=device) # mean losses
if rank != -1:
dataloader.sampler.set_epoch(epoch)
pbar = enumerate(dataloader)
logger.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'targets', 'img_size'))
if rank in [-1, 0]:
pbar = tqdm(pbar, total=nb) # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# model.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / total_batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale,多尺度缩放训练
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward 前向传播
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
# 求loss
loss, loss_items = compute_loss(pred, targets.to(device), model) # loss scaled by batch_size
if rank != -1:
loss *= opt.world_size # gradient averaged between devices in DDP mode
# Backward 反向传播
scaler.scale(loss).backward()
# Optimize 优化器的更新
if ni % accumulate == 0:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
# Print功能
"""
打印:epoch,总epochs, cuda占用情况mem,平均loss,当前batch中target数量,图像shape
Plot功能:保存3张训练过程数据集可视化图,就是在数据集上绘制box和类
"""
if rank in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # 更新 mean losses
# 打印内存
mem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0) # (GB)
s = ('%10s' * 2 + '%10.4g' * 6) % (
'%g/%g' % (epoch, epochs - 1), mem, *mloss, targets.shape[0], imgs.shape[-1])
pbar.set_description(s)
# Plot
if plots and ni < 3:
f = save_dir / f'train_batch{ni}.jpg' # filename
plot_images(images=imgs, targets=targets, paths=paths, fname=f)
# if tb_writer:
# tb_writer.add_image(f, result, dataformats='HWC', global_step=epoch)
# tb_writer.add_graph(model, imgs) # add model to tensorboard
elif plots and ni == 3 and wandb:
wandb.log({"Mosaics": [wandb.Image(str(x), caption=x.name) for x in save_dir.glob('train*.jpg')]})
# end batch ------------------------------------------------------------------------------------------------
# end epoch ----------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for tensorboard
scheduler.step()
# DDP process 0 or single-GPU
if rank in [-1, 0]:
# mAP
if ema:
ema.update_attr(model)
final_epoch = epoch + 1 == epochs
if not opt.notest or final_epoch: # Calculate mAP
if epoch >= opt.period: # 大于3轮的时候才测试
results, maps, times = test.test(opt.data,
batch_size=batch_size*2,
imgsz=imgsz_test,
model=ema.ema.module if hasattr(ema.ema, 'module') else ema.ema,
single_cls=opt.single_cls,
dataloader=testloader,
save_dir=save_dir,
plots=plots and final_epoch,
log_imgs=opt.log_imgs if wandb else 0)
# Write
with open(results_file, 'a') as f:
f.write(s + '%10.4g' * 7 % results + '\n') # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
if len(opt.name) and opt.bucket:
os.system('gsutil cp %s gs://%s/results/results%s.txt' % (results_file, opt.bucket, opt.name))
# Log
tags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', # train loss
'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
'val/box_loss', 'val/obj_loss', 'val/cls_loss', # val loss
'x/lr0', 'x/lr1', 'x/lr2'] # params
for x, tag in zip(list(mloss[:-1]) + list(results) + lr, tags):
if tb_writer:
tb_writer.add_scalar(tag, x, epoch) # tensorboard
if wandb:
wandb.log({tag: x}) # W&B
# Update best mAP
"""
fitness:给mAP@0.5和mAP@0.5~.95分别分配0.1,0.9的权重后求和
fitness_p:给p分配100%的权重,其他权重为0
fitness_r:给R分配100%权重,其他为0
fitness_ap50:仅对mAP@0.5分配100%权重
fitness_ap:仅对mAP@0.5~.95分配100%权重
"""
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
fi_p = fitness_p(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
fi_r = fitness_r(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
fi_ap50 = fitness_ap50(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
fi_ap = fitness_ap(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
if (fi_p > 0.0) or (fi_r > 0.0): # 当P 或 R大于0的时候,计算F值
fi_f = fitness_f(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
else:
fi_f = 0.0
if fi > best_fitness: # 记录最好的best_fitness
best_fitness = fi
if fi_p > best_fitness_p: # 记录最好的P
best_fitness_p = fi_p
if fi_r > best_fitness_r: # 记录最好的R
best_fitness_r = fi_r
if fi_ap50 > best_fitness_ap50: # 记录最好的mAP@0.5
best_fitness_ap50 = fi_ap50
if fi_ap > best_fitness_ap: # 记录最好的mAP@0.5~.95
best_fitness_ap = fi_ap
if fi_f > best_fitness_f: # 记录最好的F值
best_fitness_f = fi_f
# Save model
"""
model的保存会将epoch,上述的各个best以及训练结果,模型权重(不含结构图),优化器参数进行保存,因此推理中需要调用['model']keys
"""
save = (not opt.nosave) or (final_epoch and not opt.evolve)
if save:
with open(results_file, 'r') as f: # create checkpoint
if opt.pt:
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'best_fitness_p': best_fitness_p,
'best_fitness_r': best_fitness_r,
'best_fitness_ap50': best_fitness_ap50,
'best_fitness_ap': best_fitness_ap,
'best_fitness_f': best_fitness_f,
'training_results': f.read(),
'model': ema.ema.module if hasattr(ema,'module') else ema.ema,
'optimizer': None if final_epoch else optimizer.state_dict(),
'wandb_id': wandb_run.id if wandb else None}
else:
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'best_fitness_p': best_fitness_p,
'best_fitness_r': best_fitness_r,
'best_fitness_ap50': best_fitness_ap50,
'best_fitness_ap': best_fitness_ap,
'best_fitness_f': best_fitness_f,
'training_results': f.read(),
'model': ema.ema.module.state_dict() if hasattr(ema, 'module') else ema.ema.state_dict(),
'optimizer': None if final_epoch else optimizer.state_dict(),
'wandb_id': wandb_run.id if wandb else None}
# Save last, best and delete
torch.save(ckpt, last) # 保存last.pt
if best_fitness == fi: # 保存best.pt (这个权重保存的是map0.5和map0.5~.95综合加权后的)
torch.save(ckpt, best)
if (best_fitness == fi) and (epoch >= 200): # 大于200epoch后每个epoch保存一次
torch.save(ckpt, wdir / 'best_{:03d}.pt'.format(epoch))
if best_fitness == fi:
torch.save(ckpt, wdir / 'best_overall.pt') # 保存best_overall.pt
if best_fitness_p == fi_p: # 保存p值最好的权重
torch.save(ckpt, wdir / 'best_p.pt')
if best_fitness_r == fi_r: # 保存R最好的权重
torch.save(ckpt, wdir / 'best_r.pt')
if best_fitness_ap50 == fi_ap50: # 保存mAP0.5最好的权重
torch.save(ckpt, wdir / 'best_ap50.pt')
if best_fitness_ap == fi_ap: # 保存mAP@.5~.95最好的权重
torch.save(ckpt, wdir / 'best_ap.pt')
if best_fitness_f == fi_f: # 保存F值最好的权重
torch.save(ckpt, wdir / 'best_f.pt')
if epoch == 0: # 保存第一轮的权重
torch.save(ckpt, wdir / 'epoch_{:03d}.pt'.format(epoch))
if ((epoch+1) % 25) == 0: # 每25个epoch保存一轮
torch.save(ckpt, wdir / 'epoch_{:03d}.pt'.format(epoch))
if epoch >= (epochs-5):
torch.save(ckpt, wdir / 'last_{:03d}.pt'.format(epoch))
elif epoch >= 420:
torch.save(ckpt, wdir / 'last_{:03d}.pt'.format(epoch))
del ckpt
# end epoch ----------------------------------------------------------------------------------------------------
# end training
if rank in [-1, 0]:
# Strip optimizers
n = opt.name if opt.name.isnumeric() else ''
fresults, flast, fbest = save_dir / f'results{n}.txt', wdir / f'last{n}.pt', wdir / f'best{n}.pt'
for f1, f2 in zip([wdir / 'last.pt', wdir / 'best.pt', results_file], [flast, fbest, fresults]):
if f1.exists():
os.rename(f1, f2) # rename
if str(f2).endswith('.pt'): # is *.pt
strip_optimizer(f2) # strip optimizer
os.system('gsutil cp %s gs://%s/weights' % (f2, opt.bucket)) if opt.bucket else None # upload
# Finish
if plots:
plot_results(save_dir=save_dir) # save as results.png
训练自己的数据集
在工程下面中的dataset文件下放入自己的数据集。目录形式如下:
dataset
|-- Annotations
|-- ImageSets
|-- images
|-- labels
Annotations是存放xml标签文件的,images是存放图像的,ImageSets存放四个txt文件【后面运行代码的时候会自动生成】,labels是将xml转txt文件。
1.运行makeTXT.py。这将会在ImageSets文件夹下生成 trainval.txt,test.txt,train.txt,val.txt四个文件【如果你打开这些txt文件,里面仅有图像的名字】。
2.打开voc_label.py,并修改代码 classes=[""]填入自己的类名,比如你的是训练猫和狗,那么就是classes=["dog","cat"],然后运行该程序。此时会在labels文件下生成对应每个图像的txt文件,形式如下:【最前面的0是类对应的索引,我这里只有一个类,后面的四个数为box的参数,均归一化以后的,分别表示box的左上和右下坐标,等训练的时候会处理成center_x,center_y,w, h】
0 0.4723557692307693 0.5408653846153847 0.34375 0.8990384615384616 0 0.8834134615384616 0.5793269230769231 0.21875 0.8221153846153847
3.在data文件夹下新建一个mydata.yaml文件。内容如下【你也可以把coco.yaml复制过来】。
你只需要修改nc以及names即可,nc是类的数量,names是类的名字。
train: ./dataset/train.txt val: ./dataset/val.txt test: ./dataset/test.txt # number of classes nc: 1 # class names names: ['target']
4.以yolor_csp为例。打开cfg下的yolor_csp.cfg,搜索两个内容,搜索classes【有三个地方】,将classes修改为自己的类别数量 。再继续搜索255【6个地方】,这个255指的是coco数据集,为3 * (5 + 80),如果是你自己的类,你需要自己计算一下,3*(5+你自己类的数量)。比如我这里是1个类,就是改成18.
5.在data/下新建一个myclasses.names文件,写入自己的类【这个是为了后面检测的时候读取类名】
6.终端输入参数,开始训练。
python train.py --weights yolor_csp.pt --cfg cfg/yolor_csp.cfg --data data/mydata.yaml --batch-size 8 --device 0训练的权重会存储在当前工程下runs/train/exp的weights中。每次运行train.py的时候会在runs/train/下生成exp,exp1,exp2...为的防止权重的覆盖。
检测推理
终端输入参数,开始检测。
python detect.py --source 【你的图像路径】 --cfg cfg/yolor_csp.cfg --weights 【你训练好的权重路径】 --conf 0.2 --img-size 640 --device 0剪枝
在利用剪枝功能前,需要安装一下剪枝的库。需要安装0.2.7版本,0.2.8有些人说有问题。
pip install torch_pruning==0.2.7
1.保存完整的权重文件
剪枝之前先要保存一下网络的权重和网络结构【非剪枝训练的权重仅含有权值,也就是通过torch.save(model.state_dict())形式保存的】。
修改tools/save_whole_model.py中的--weights,改为自己的训练后的权权重路径,修改--save_whole_model 为True,运行代码后会生成一个whole_model.pt,如果还想得到onnx模型,可以将--onnx设置为True。
2.网络剪枝
剪枝之前需要自己熟悉网络结构,也可以通过tools/printmodel.py 打印网络结构。
这里的剪枝操作支持两种类型:
1.单独卷积的剪枝
在Conv_pruning这个函数中,修改三个地方:
通过keys指筛选层:
if k == 'module_list.22.Conv2d.weight': # 筛选出该层 (根据自己需求)
amount是剪枝率,可以按续修改。
pruning_idxs = strategy(v, amount=0.4) # or manually selected pruning_idxs=[2, 6, 9, ...]
修改DG.get_pruning_plan model参数,改为需要剪枝的层
# 放入要剪枝的层 pruning_plan = DG.get_pruning_plan(model.module_list[22].Conv2d, tp.prune_conv, idxs=pruning_idxs)
我这里是仅对第22个卷积进行剪枝。看到如下参数有变化就是剪枝成功了,如果参数没变就说明你剪的不对【可以看到你参数变化不大,因为你仅仅对一个层剪枝了而已,当然变化不大】
-------------
[ <DEP: prune_conv => prune_conv on module_list.22.Conv2d (Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False))>, Index=[1, 5, 8, 10, 11, 12, 13, 14, 15, 18, 20, 21, 22, 23, 25, 28, 32, 38, 40, 44, 52, 54, 55, 57, 58, 59, 61, 63, 64, 66, 72, 73, 77, 82, 84, 86, 88, 96, 97, 98, 99, 101, 102, 103, 109, 113, 114, 120, 123, 126, 127], NumPruned=6528]
[ <DEP: prune_conv => prune_batchnorm on module_list.22.BatchNorm2d (BatchNorm2d(128, eps=0.0001, momentum=0.03, affine=True, track_running_stats=True))>, Index=[1, 5, 8, 10, 11, 12, 13, 14, 15, 18, 20, 21, 22, 23, 25, 28, 32, 38, 40, 44, 52, 54, 55, 57, 58, 59, 61, 63, 64, 66, 72, 73, 77, 82, 84, 86, 88, 96, 97, 98, 99, 101, 102, 103, 109, 113, 114, 120, 123, 126, 127], NumPruned=102]
[ <DEP: prune_batchnorm => _prune_elementwise_op on _ElementWiseOp()>, Index=[1, 5, 8, 10, 11, 12, 13, 14, 15, 18, 20, 21, 22, 23, 25, 28, 32, 38, 40, 44, 52, 54, 55, 57, 58, 59, 61, 63, 64, 66, 72, 73, 77, 82, 84, 86, 88, 96, 97, 98, 99, 101, 102, 103, 109, 113, 114, 120, 123, 126, 127], NumPruned=0]
[ <DEP: _prune_elementwise_op => _prune_elementwise_op on _ElementWiseOp()>, Index=[1, 5, 8, 10, 11, 12, 13, 14, 15, 18, 20, 21, 22, 23, 25, 28, 32, 38, 40, 44, 52, 54, 55, 57, 58, 59, 61, 63, 64, 66, 72, 73, 77, 82, 84, 86, 88, 96, 97, 98, 99, 101, 102, 103, 109, 113, 114, 120, 123, 126, 127], NumPruned=0]
[ <DEP: _prune_elementwise_op => prune_related_conv on module_list.23.Conv2d (Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))>, Index=[1, 5, 8, 10, 11, 12, 13, 14, 15, 18, 20, 21, 22, 23, 25, 28, 32, 38, 40, 44, 52, 54, 55, 57, 58, 59, 61, 63, 64, 66, 72, 73, 77, 82, 84, 86, 88, 96, 97, 98, 99, 101, 102, 103, 109, 113, 114, 120, 123, 126, 127], NumPruned=58752]
65382 parameters will be pruned
-------------
2022-09-19 11:01:55.563 | INFO | __main__:Conv_pruning:42 - Params: 52497868 => 52432486
2022-09-19 11:01:56.361 | INFO | __main__:Conv_pruning:55 - 剪枝完成剪枝完在model_data/下会保存一个 Conv_pruning.pt权重。这个就是剪枝后的权重。
2.卷积层(某个模块)的剪枝
通过运行layer_pruning()函数。修改两个地方:
included_layers是需要剪枝的层,比如我这里是对前60层进行剪枝。
included_layers = [layer.Conv2d for layer in model.module_list[:61] if
type(layer) is torch.nn.Sequential and layer.Conv2d]修改amount剪枝率。
pruning_plan = DG.get_pruning_plan(m, tp.prune_conv, idxs=strategy(m.weight, amount=0.9))看到如下参数的变化说明剪枝成功了。 将会在model_data/下生成一个layer_pruning.pt。
2022-09-19 11:12:40.519 | INFO | __main__:layer_pruning:81 -
-------------
[ <DEP: prune_conv => prune_conv on module_list.60.Conv2d (Conv2d(26, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))>, Index=[], NumPruned=0]
0 parameters will be pruned
-------------2022-09-19 11:12:40.522 | INFO | __main__:layer_pruning:87 - Params: 52497868 => 43633847
2022-09-19 11:12:41.709 | INFO | __main__:layer_pruning:102 - 剪枝完成
3.剪枝后的微调训练
与上面的训练一样,只不过weights需要改为自己的剪枝后的权重路径,同时再加一个--pt参数,如下:
参数--pt:指剪枝后的训练
这里默认的epochs还是300,自己可以修改。
python train.py --weights model_data/layer_pruning.pt --cfg cfg/yolor_csp.cfg --data data/mydata.yaml --batch-size 8 --device 0 --pt4.剪枝后的推理检测
--weights 为剪枝后的权重,在加一个--pd表示剪枝后的检测。
python detect.py --source 【你的图像路径】 --cfg cfg/yolor_csp.cfg --weights 【剪枝的权重路径】 --conf 0.2 --img-size 640 --device 0 --pdgithub代码:
https://github.com/YINYIPENG-EN/Pruning_for_YOLOR_pytorch
权重百度云:
链接:https://pan.baidu.com/s/1uQflOXCQtffkD5kHAAF94A
提取码:yypn
所遇问题:
1.剪枝训练期间在测mAP的时候报错:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!解决办法:在models/modes.py中的第416行和417行,强行修改 :
io[..., :2] = (io[..., :2] * 2. - 0.5 + self.grid) io[..., 2:4] = (io[..., 2:4] * 2) ** 2 * self.anchor_wh改为:
io[..., :2] = (io[..., :2] * 2. - 0.5 + self.grid.cuda()) io[..., 2:4] = (io[..., 2:4] * 2) ** 2 * self.anchor_wh.cuda()
在训练完需要推理测试的时候需要把上面的再改回去(不是不能检测,只是会特别的不准)















 2751
2751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











