






为什么一条简单的商品评论,AI就能判断用户是喜欢还是厌恶?社交媒体上的海量文本数据,如何快速洞察用户情绪倾向?情感分析(Sentiment Analysis)作为自然语言处理(NLP)的核心任务之一,正在电商、舆情监控、智能客服等领域发挥巨大作用。
本文将针对初学者,带你用深度学习技术构建情感分析模型(实现正负面情绪的分析),涵盖数据预处理、模型搭建、训练流程,并提供完整的PyTorch代码实现。
功能说明:
1.文本训练:√
主干网络:
LSTM:√
其他网络:待更新
2.预测:√
环境说明
pytorch:1.7.0
jieba:0.42.1
pandas:1.1.4
代码:
GitHub - YINYIPENG-EN/Sentiment_Analysis: 基本深度学习的情感分析
1.准备数据集
本文仅仅是应用一个非常简单的示例进行说明,以最小化实现方法让大家快速上手~
制作数据集并放置在项目的data/文件下。结构如下:
data
|-- negative.txt
|-- positive.txt
negative.txt用于存储负面(或是消极的情绪),positive.txt是正面(积极的情绪)。部分内容如下,我这里的数据集非常的简单,数据量也比较少,大家可自己扩充数据集。
negative.txt 产品质量差,使用一周就坏了,非常失望 服务态度恶劣,等待时间过长,不会再来 内容空洞无物,完全浪费时间和金钱 界面设计混乱,操作复杂难用,体验极差 物流太慢,包装破损,商品有瑕疵 宣传与实际不符,功能缺失,虚假广告 客服响应慢,问题无法解决,令人沮丧 味道一般,价格偏高,性价比低..........................
positive.txt
学习内容非常实用,老师讲解清晰易懂,收获很大 性价比超高,功能齐全,物超所值 画面精美,音乐动人,情感表达真挚 操作简单方便,界面友好,适合所有年龄段 送货速度快,包装完好,质量上乘 解决方案专业有效,问题迅速解决,非常满意 食材新鲜,味道正宗,绝对五星好评
2.训练
在终端输入以下命令开启训练:
python emotion_train.py训练参数说明,可根据自己需求调整:
# 参数设置 MAX_LENGTH = 20 # 序列最大长度 EMBEDDING_DIM = 128 HIDDEN_DIM = 256 NUM_LAYERS = 1 DROPOUT = 0.3 BATCH_SIZE = 8 EPOCHS = 40 LEARNING_RATE = 0.001 VOCAB_SIZE = 1000 # 词汇表大小 output_dir = 'zhangsan_logs' # 权重保存位置 backbone = 'LSTM' # 主干网络,暂仅支持LSTM
训练过后会将得到的权重、loss曲线和混淆矩阵保存下来,如下所示:(注:我这里其实已经过拟合了,数据量比较少,仅100条,只是为了省时间给大家做一个实现而已)
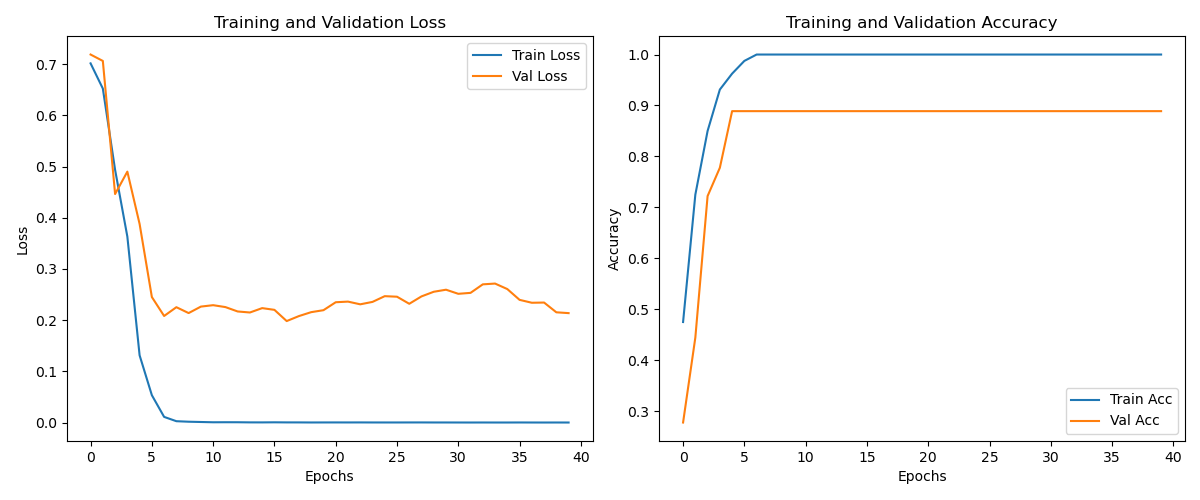
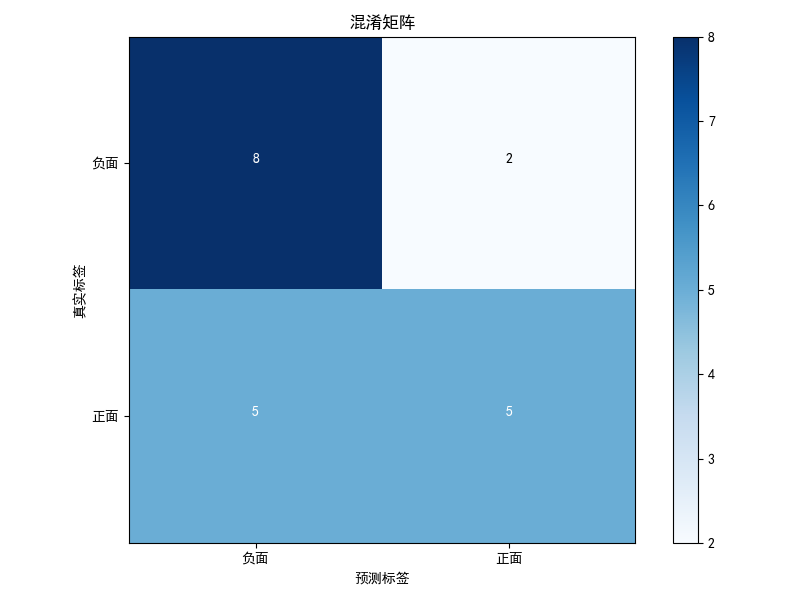
3.预测
我们可以将训练后的权重哪里进行实际预测。例如,根据输入,模型会自动判断是正面的还是负面的,我这里的用例如下:
"这个产品真的很好用,物超所值",
"服务太差,再也不会购买了",
"质量很好,比想象中好",
"非常满意,超出了我的预期"运行代码开启预测:
python predict.py预测结果:
文本: 这个产品真的很好用,物超所值
情感: 正面
置信度: 负面 0.0197, 正面 0.9803
--------------------------------------------------
文本: 服务太差,再也不会购买了
情感: 负面
置信度: 负面 0.8860, 正面 0.1140
--------------------------------------------------
文本: 质量很好,比想象中好
情感: 正面
置信度: 负面 0.0970, 正面 0.9030
--------------------------------------------------
文本: 非常满意,超出了我的预期
情感: 正面
置信度: 负面 0.0656, 正面 0.9344
--------------------------------------------------
Process finished with exit code 0
(注:训练代码部分有偿提供)


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











