










一、文章概况
文章题目:《Explicit Bias Discovery in Visual Question Answering Models》
文章一作Varun Manjunatha来自adobe,后面两位作者Nirat Saini和Larry S. Davis来自马里兰,Larry S. Davis是Varun Manjunatha读博期间的导师。下面是作者的个人主页:
文章引用格式:V. Manjunatha, N. Saini, L. S. Davis. "Explicit Bias Discovery in Visual Question Answering Models." In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
项目地址:作者使用的模型参考于https://github.com/Cyanogenoid/pytorch-vqa
二、文章导读
先放上文章的摘要部分:
Researchers have observed that Visual Question Answering (VQA ) models tend to answer questions by learning statistical biases in the data. For example, their answer to the question “What is the color of the grass?” is usually “Green”, whereas a question like “What is the title of the book?” cannot be answered by inferring statistical biases. It is of interest to the community to explicitly discover such biases, both for understanding the behavior of such models, and towards debugging them. Our work address this problem. In a database, we store the words of the question, answer and visual words corresponding to regions of interest in attention maps. By running simple rule mining algorithms on this database, we discover human-interpretable rules which give us unique insight into the behavior of such models. Our results also show examples of unusual behaviors learned by models in attempting VQA tasks.
VQA数据集中的问题偏见是很常见的情况,发现偏见并理解他们的在模型中的行为是非常有必要的。这篇文章就是为了解决这个问题。在数据集上运行一些简单的挖掘算法,作者发现了人为可解释的规则。
这篇文章的摘要写的挺模糊的,详细内容还是要跟着继续往下看。
三、文章详细介绍
目前已经公开的VQA数据集有很多,这些经常使用的数据集却存在一些问题,看下图:

左边一列的第一张图问“现在时间”,这里指的是教堂钟表上的时间,第二张图问的是第一本书上面的书的名字,这两个问题是本身不完整的问题,第三张图问草是什么颜色,这是一个语言偏见问题。右边一列统计了一些常出现问题和答案,比如只要问题中出现了"what, time, day",而图片是一片漆黑的景象,那么答案一定是"bight",大部分情况下,这样的答案是正确的,但是答案却是通过统计得出的。
因此这篇文章主要是探究和列举VQA模型中学习到的一些偏见。发现偏见用的是经典的Apriori算法。另外作者还发现,只用语言是可以回答大多数问题的,并且答案看起来貌似合理,但是图像可以给出更精确的答案,这是因为语言模型只能产生简单的答案。
最后,这篇文章并不想改善最好的效果(state of the art),作者用的模型主要来自于[3]。
[3] V. Kazemi and A. Elqursh. Show, ask, attend, and answer: A strong baseline for visual question answering. 2017.
这篇文章作者的主要贡献:
To concretely summarize, our main contribution is to provide a method that can capture macroscopic rules that a VQA model ostensibly utilizes to answer questions. (提供一个VQA可以使用的宏观规则来回答问题)
1. 相关工作
机器学习中的不良偏见(On undesirable biases in machine learning models):机器学习常用来计算信用得分,保险率等,很重要的一点是因为机器学习对于性别、种族等没有偏见(bias)。
深度网络的debug(On debugging deep networks):一些语义工作表明机器学习并不能够理解和解释模型。
VQA的debug(On debugging VQA):一些基于VQAv1数据集的研究表明,VQA模型对新图像是无效的,他们只能够阅读问题,却不能够根据不同的图像改变答案。但是目前的模型都没有发现这些偏见。
2. 方法
作者将偏见发现(bias discovery)任务作为一个规则挖掘问题(rule mining problem)。发现的VQA中的偏见和挖掘规则之间的连接如下:每一个Q-I-A或者QI-A元组都能够数据集中的一个事件。规则挖掘操作的组成有3部分:
• First, a frequent itemset miner picks out a set of all itemsets which occur at least s times in the dataset where s is the support. Because our dataset has over 200,000 questions (the entire VQA validation set), and the number of items exceeds 40,000 (all question words+all answer words+all visual words), we choose GMiner due to its speed and efficient GPU implementation. (频繁事件的挖掘器选取所有至少出现s次的事件集,算法采用GMiner。)
• Next, a rule miner Apriori forms all valid association rules A → C, such that the rule has a support >s and a confidence >c, where the confidence is defined as |A∪C| / |A| . Here, the itemset A is called antecedent and the itemset C is called consequent. We choose c=0.2 unless specified otherwise. (规则挖掘器Apriori构成所有的联合规则,由A映射C。)
• Finally, a post-processing step removes obviously spurious rules by considering the causal nature of the VQA problem (i.e., only considering rules that obey: Image/Question → Answer). (后处理步骤考虑VQA中问题的因果关系,移出明显错误的规则。)
这里先给出模型,后面会仔细介绍:
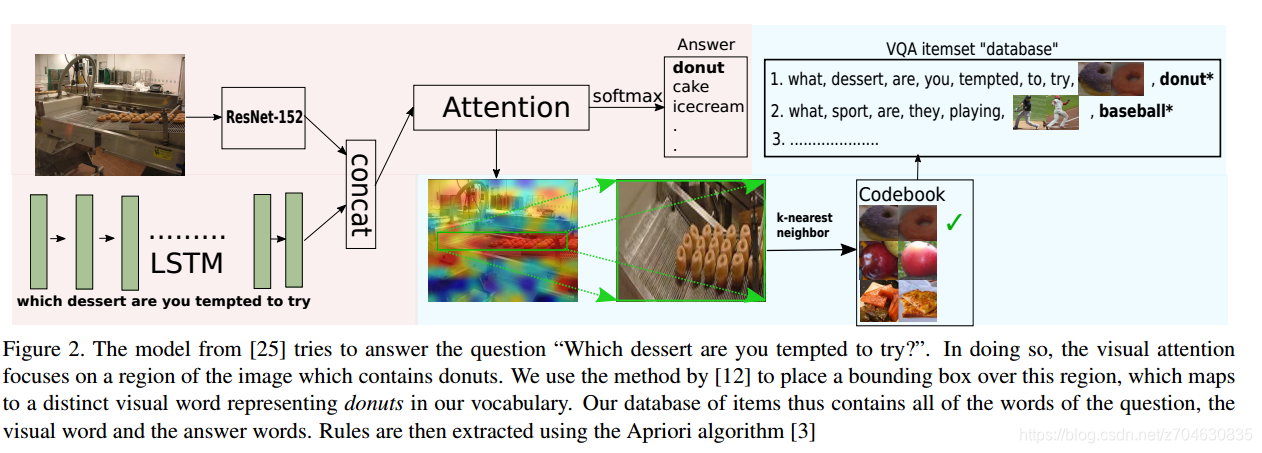
(1)基准模型(Baseline Model):
作者用的模型来自文献[3],选择这个模型的原因有两个:一是简单易行;二是它是不用外部数据的4%以内的最好的模型,参考链接https://github.com/Cyanogenoid/pytorch-vqa。这个模型的简短介绍如下:“VQA问题可以看成一个多分类问题,通过输入的图片和问题,来找到置信答案最高的类别(有3000类),用Resnet-152来提取图像特征,用LSTM来提取问题特征,然后将提取的两个特征连接起来,在通过attention map送入到两层dense layers中进行softmax,最后输出答案”
(2)视觉码本生成(Visual Codebook Generation):
这里作者使用了“聚类法特征提取”(feature extraction followed by clustering)来生成视觉码本(codebook)。首先,用搜索框(bounding-box)标注MSCOCO和COCO-Stuff共计30万个patch,然后将每一个patch变成224*224,再用ResNet-152提取图像特征,然后使用k-means聚类,聚成1250类,下图是一个聚类的结果:

这些聚类结果不仅有客观目标比如zebras, giraffes, elephants, cars, buses, trains, people,也有动作描述类的如“people eating”, “cats standing on toilets”, “people in front of chain link fences”。
(3)从注意力到搜索框(From attention map to bounding box):
我们假定网络是聚焦在图像中的一部分。搜索框能够覆盖足够多的图像中的显著区域,裁剪并映射patch到相应的视觉码本中。有很多能够裁剪attention map的方法,这里作者使用了:在一张attention-map G内,给定一个百分比 ,来找满足下式的最小搜索框bounding box B:
,来找满足下式的最小搜索框bounding box B:
![]()
因为我们用了ResNet-152来提取视觉特征,所以最后的attention map大小为14*14。如果我们给定一个m×n的格网,那么unique bounding box的数量为num_bboxes = (m×n×(m+1)×(n+1)) / 4,如果m=n=14,那么num_bboxes=11025,因为这个值比较小,所以bounding box就遍历这11025种情况,在=0.3的情况下选择能够最小包围attention的box。这个工作的示意图如下:

(4)流程总结(Pipeline Summarized):
整个流程pipeline就是前面fig 2上面的。输入图像和问题,对第二特征图(应该是指的patch)使用上节提到的方法来找bounding-box,然后在这个box上用ResNet-152,从词汇表中根据k近邻法来提取视觉单词,最后再用Apriori算法来获取规则。
3. 实验
(1)VQA中的语言偏见统计(Language only statistical biases in VQA):
前面说过,大部分的偏见都是由于语言造成的,为了说明这个问题,我们只使用语言模型而不使用图像。在VQAv2模型上大概正确率有43%,在VQAv1数据集上的正确率有48%,然而,从VQAv2上随机选择200个问题回答,却有88%的正确率(貌似合理的答案plausibly correct),下面是一些例子:

因此,可以认为模型其实只是将问题中的一些列关键词直接映射到答案中的关键词而已。这就说明了数据其实是存在偏见的。
(2)VQA中的视觉+语言偏见统计(Vision+Language statistical biases in VQA):
前面的图表也已经表示出了,包含先行词的问题和包含先行词视觉的图像大部分情况下都是可以正确预测答案的。我们来看一下不同类型的问题情况:
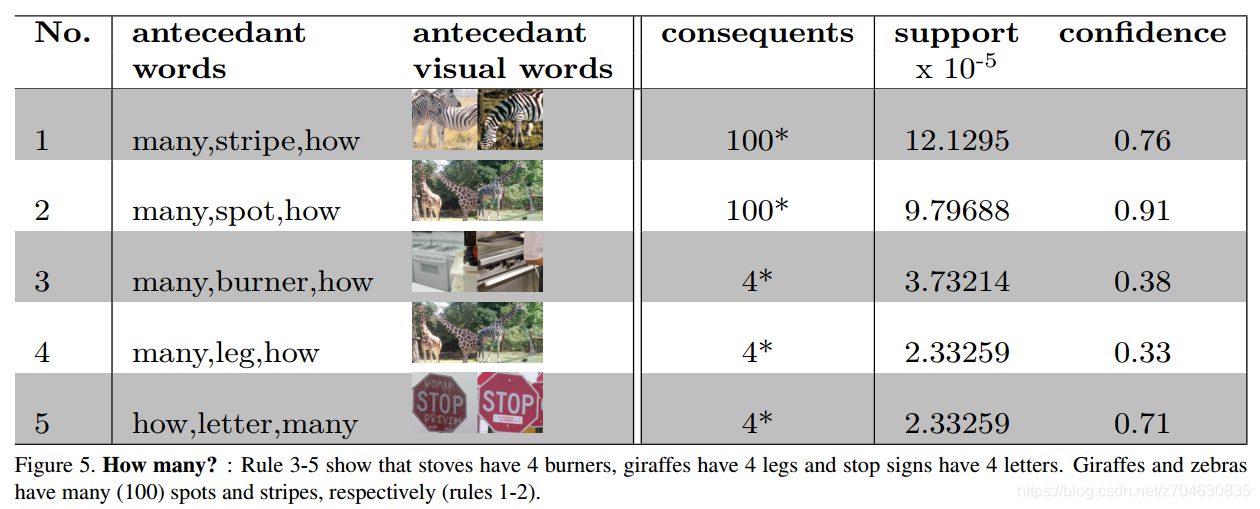
How many?:一些例子表明VQA模型似乎学习到了斑马有条纹,长颈鹿有斑点,stop路标有4个字母等,如下所示,但是实际上很多是根据答案的分布特征得来的:
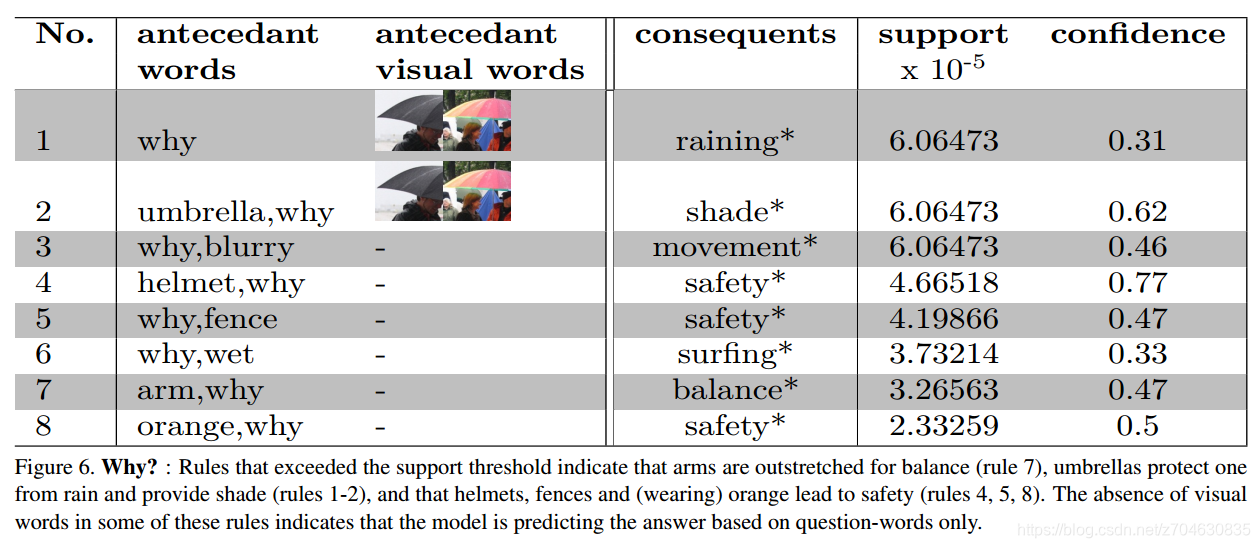
Why?:一些证据表明模型虽然能够学习“why”,但是同理,也只是学习到了关键词的映射,实际上并不具有推理能力:
What is he/she doing?:作者发现这个问题和性别之间存在偏见,如果问的是女性,那么大概率回答texting(写作):

4. 限制
尽管作者的这篇文章研究的比较简单,但是还是存在一些缺陷的:提取的自然规则受限于使用生成词汇的处理过程(the exact nature of the rules is limited by the process used to generate the visual vocabulary)。比如下面的图,图片出现摩托答案尽管答案不是Harley Davidson,出现了牙刷和剪刀答案就回答Colgate:

还有类似的例子:



















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











