









一、背景
文章题目:《Hyperbolic Visual Embedding Learning for Zero-Shot Recognition》
文献引用格式:Shaoteng Liu, Jingjing Chen, Liangming Pan, Chong-Wah Ngo, Tat-Seng Chua and Yu-Gang Jiang. "Hyperbolic Visual Embedding Learning for Zero-Shot Recognition." In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
项目地址:https://github.com/ShaoTengLiu/Hyperbolic_ZSL
二、文章摘要
This paper proposes a Hyperbolic Visual Embedding Learning Network for zero-shot recognition. The network learns image embeddings in hyperbolic space, which is capable of preserving the hierarchical structure of semantic classes in low dimensions. Comparing with existing zeroshot learning approaches, the network is more robust because the embedding feature in hyperbolic space better represents class hierarchy and thereby avoid misleading resulted from unrelated siblings. Our network outperforms exiting baselines under hierarchical evaluation with an extremely challenging setting, i.e., learning only from 1,000 categories to recognize 20,841 unseen categories. While under flat evaluation, it has competitive performance as state-of-the-art methods but with five times lower embedding dimensions. Our code is publicly available.
本文提出了双曲视觉嵌入学习网络,用于zero-shot识别。网络在双曲空间内学习图像嵌入,这样能够在低维中能够获得语义类别的分层结构。与其他zero-shot方法相比,该方法更加鲁棒,因为嵌入特征到双曲空间能够更好表示类别层级,进而避免误分类。该模型的表现更好,可以学习1000种类别,对20841张没有见过的图片进行分类。
三、文章介绍
现实中的图像识别往往需要面对数以万计的目标类别,但是收集大量数据费时费力,因此产生了0样本学习,即能够识别一个在训练过程中没有见过的新类别。然而,0样本学习是一个非常困难的事,在ImageNet上,zero-shot在top-5上的精度还不到10%,远低于显示世界的应用。
一方面,WordNet中定义的类别既有泛化的也有精细的,比如狗,和它的子类都千差万别,但是我们注意到,即使小类别无法预测,但是大类别如果能正确预测,用户对其接受程度是远远大于小类别预测错误。比如下图所示:

如果模型训练中,没有见过的红松鼠,尽管预测为树松鼠,其可接收程度也要远远大于预测为袋鼠。因此作者认为,一个鲁棒的模型,可以先从正确预测大类做起。
现有的工作都没有对zero-shot的鲁棒性进行研究,都是直接学习从视觉空间到语义空间的映射。语义空间常常用一个语义向量来表示,可以利用GloVe或者Word2Vec模型。而对于类别之间的分层关系,并未在语义空间中编码。对于分层类别的研究,也有少量的工作,但是这些很难处理类别数量增加的情况。
本文发现利用双曲空间能够很好的解决这些问题,并得到一个更为鲁棒的模型。双曲空间是黎曼几何中流形空间(manifold space)的一种,这与欧式空间不同。双曲空间非常适用于建模分层数据,比如表示一棵树,我们只需要在双曲空间中用二维嵌入的分支因子(branching factor)就可以了。另外,在双曲空间中,一个类别与它的父辈特别接近,但是与它的同辈(siblings)非常远。
因此本文提出ZSL框架,在双曲空间中学习分层感知的图像嵌入特征。整个模型结构如下所示:

本文的主要贡献在于:
• We propose the Hyperbolic Visual Embedding Learning Network that learns hierarchical-aware image embeddings in hyperbolic space for ZSL. As far as we know, this is the first attempt to introduce NonEuclidean Space for zero-shot learning problem.提出了双曲视觉嵌入学习模型。这是首次将非欧式空间引入到zero-shot中。
• We conduct both empirical and analytic studies to demonstrate that introducing hyperbolic space into ZSL problem results in a model that produces more robust predictions. 引入双曲空间到zero-shot中的结果表明会产生更鲁棒的预测。
1. 相关工作
早期的zero-shot主要是数据驱动属性和用户定义的属性。近期的zero-shot工作主要是基于深度学习来做的,主要可以分成两类,一种是基于语义嵌入(semantic embeddings)的,即直接将视觉空间映射到语义空间;第二种是直接在不同类别之间进行关系建模。近期的另一些工作表明,如果同时使用隐含知识和确定知识,能够使模型在识别上表现更好。
2. 预备
主要介绍双曲空间的一些概念,这里不多介绍。
3. 方法
如上图所示,提出方法主要包含两个模块(1) Hyperbolic Label Embedding Learning和(2)Poincare´ Image Feature Embedding learning
(1)Hyperbolic Label Embedding Learning
对于文本标签,这里主要i研究了两种:Poincare hierarchy embedding model 和Poincare Glove。
Poincare embedding:作者将WordNet Noun hierarchy嵌入到Poincare ball中,其中包含82115个同义词和743241个上位关系。
Poincare GloVe:GloVe在欧式空间进行词嵌入,用于学习类别之间的语义关系。因此作者在Poincare ball中训练Glove,这里的一个难点在于,对于双曲空间的内积(inner-product),是没有明确定义的。于是,作者把Glove的loss函数中的内积替换为了Poincare距离,该距离的定义如下:
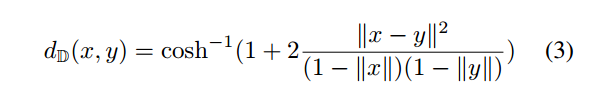
于是GloVe的loss函数变为:
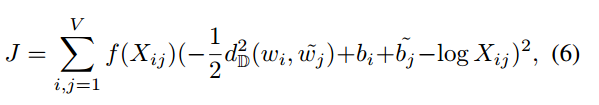
Feature Fusion:将Poincare嵌入和Poincare Glove嵌入进行链接,构成最后Poincare ball中的类别嵌入,最后的这个嵌入包含了类别的结构和语义信息。这里将两个嵌入链接后,有可能会超出Poincare ball的半径,因此又用一个指数映射,确保其嵌入链接仍在Poincare ball内,指数映射关系的计算公式为:
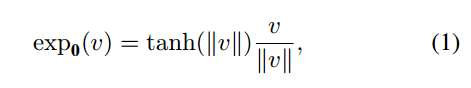
(2)Hyperbolic Image Embedding Learning
对于图像,这里使用ResNet来提取特征,最后提取的结果是欧式空间的2048维向量,为了将这个向量转换到双曲空间,这里使用了双曲特征转换网络(hyperbolic visual feature transform network)。网络主要包含两部分,指数映射(exponential map)将图像特征从欧式空间映射到双曲空间,M¨obius转换网络(M¨obius transformation network)用来对齐图像和标签。
Exponential Map指数映射:和上面公式(1)的映射计算一样。
M¨obius Transformation:这里是为了对齐提取的图像特征和前面的标签嵌入。M¨obius transformer使用两个在双曲空间下的反馈型神经网络。我们将任意一个欧式空间的函数转换到双曲空间下,可以表示为:
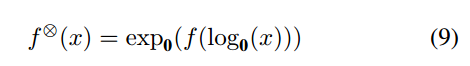
f右上角的那个符号表示:
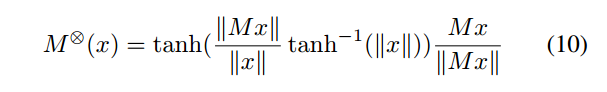
基于公式(10),可以在双曲空间下构建两层前馈性网络。
Model Training:模型训练使用的是Rank loss,Poincare Glove嵌入的优化器使用的是RADAGRAD,Poincare嵌入的优化器使用的是Riemannian stochastic gradient descent (RSGD)。
4. 实验
(1)数据集
数据集使用的是ImageNet,从中选择了已知的1000类数据,未知的数据来自于三个数据集,“2-hops”, “3-hops” and “All”。“2-hops”有1589个类别,“3-hops”有7860个类别,“All”有20841个类别。
(2)模型
参与比较的模型包括:
DeViSE
DeViSE*
ConSE
SYNC
GCNZ
DGP
(3)实验设置
模型的GPU是GTX 1080Ti GPU,语言用的pytorch。
(4)分层评估(Hierarchical Evaluation)
标准评估使用的是Top-k Hit Ratio (Hit@k),结果如下图所示:

下图是一些例子:

(5)性能比较
ZSL的性能比较结果如下:

GZSL的性能比较结果如下:

(6)消融实验
消融实验的结果如下图所示:

其中,PH Only表示模型只用Poincare Hierarchy嵌入, PG Only表示模型只用Poincare´ GloVe嵌入, PH + PG表示两个嵌入都用。
(7)维度分析
对三种不同的模型进行嵌入维度的分析,分析结果如下:

















 3905
3905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











