






首先你要拥有spark和scala的安装包
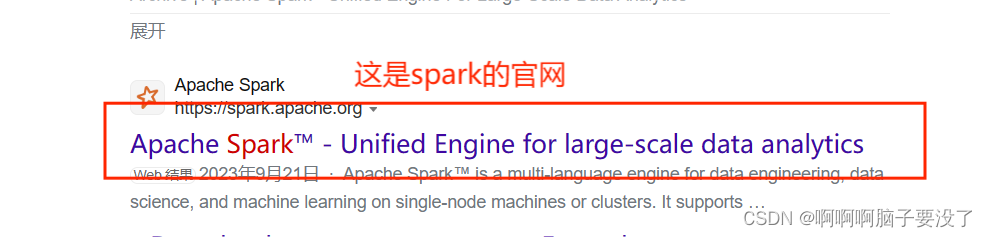
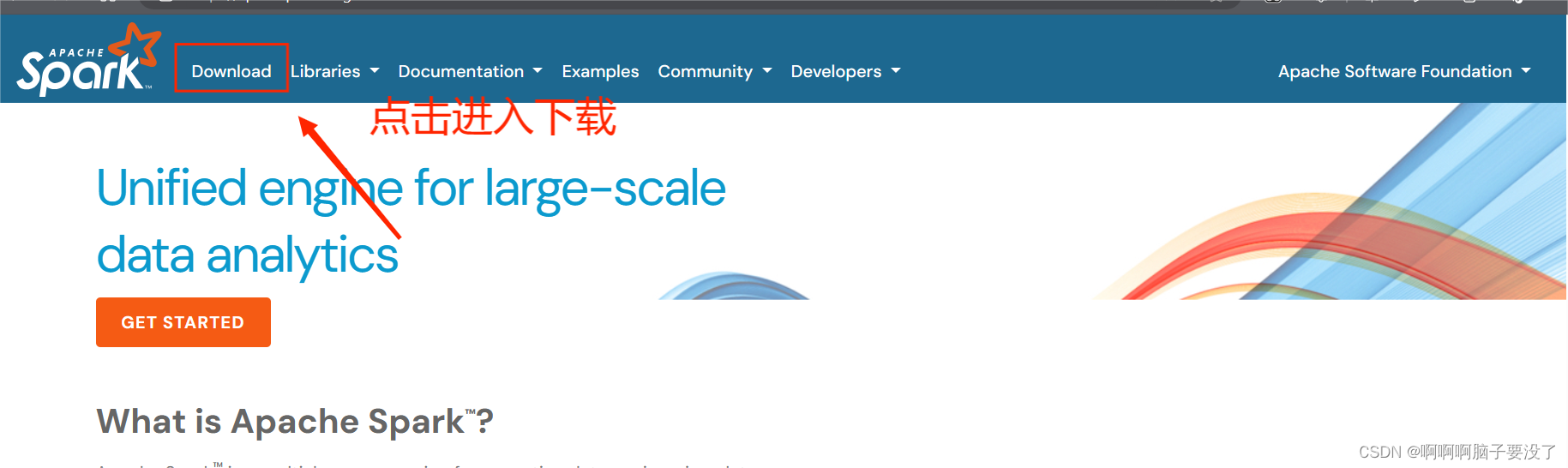
进入官网下载spark和Scala的安装包
spark

scala



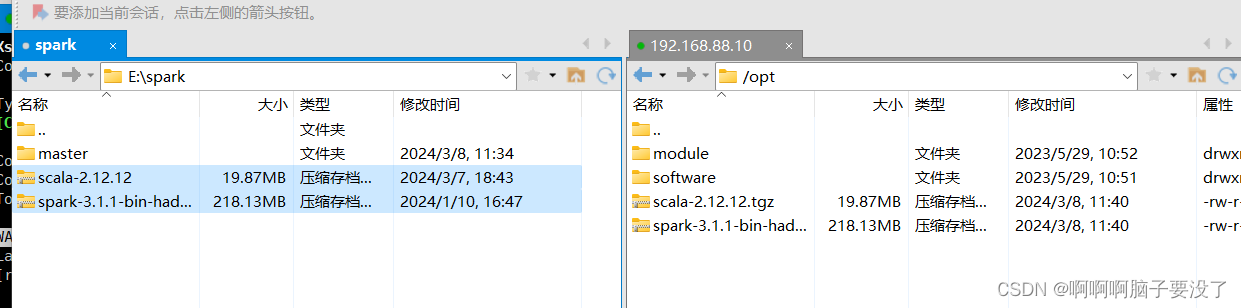
准备好后,将安装包导入虚拟机使用xshell或拖拽,建议导到opt目录下
进行scala的安装与配置
进入虚拟机或使用xshell进行配置(派大星选择用xshell)
使用xshell就要设置一下虚拟机的网络配置,改为NAT模式和子网IP改为192.168.88.0
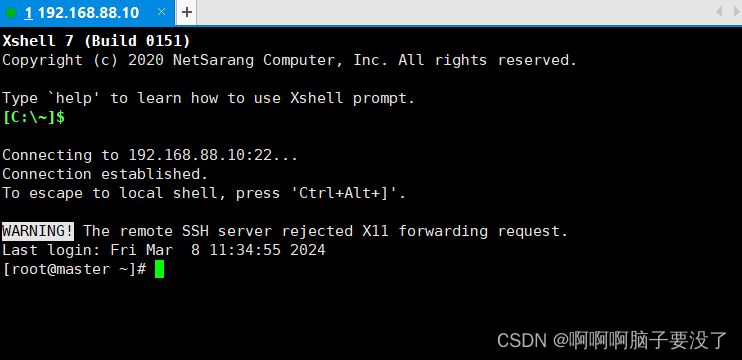
这是xshell连接成功的页面
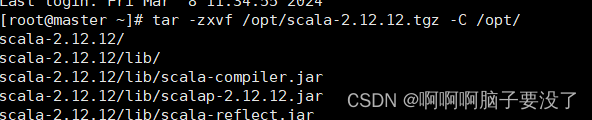
解压安装包代码如下
tar -zxvf /opt/scala-2.12.12.tgz -C /opt/
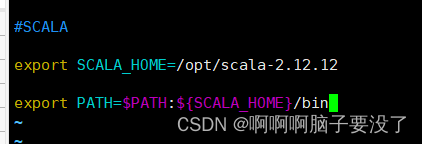
接着就要配置环境变量了
用vim命令进入etc下的profile
vim /opt/profile
![]()
进入后在最后加入这三行代码
#SCALA
export SCALA_HOME=/opt/scala-2.12.12
export PATH=$PATH:${SCALA_HOME}/bin
编写好后退出,用source使代码生效,在用scala -version查看是否成功,出现安装的版本号即为成功

进行spark安装与部署
解压安装包代码如下
tar -zxvf /opt/spark-3.1.1-bin-hadoop3.2.tgz -C /opt/

因为后缀太长,改一个简单的名字spark
cd /opt
mv spark -3.1.1 bin-hadoop3.2 spark
![]()
之后就与scala配置环境变量一样进入profile,在最后加入下面四行代码
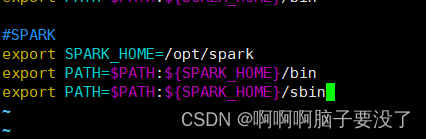
#SPARK
export SPARK_HOME=/opt/spark
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
使代码生效,进入conf,备份文件
cp spark-env.sh template spark-env.sh
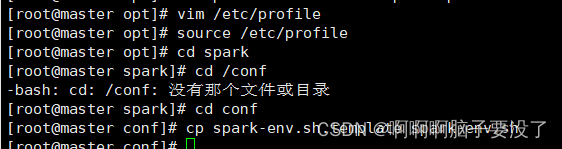
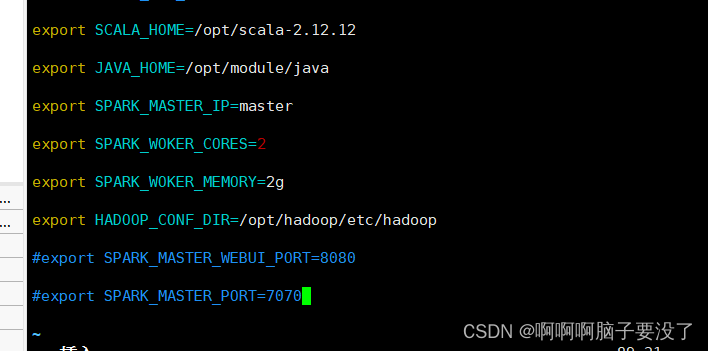
修改备份文件,在spark下的conf目录打开env,vim spark-env.sh
export SCALA_HOME=/opt/scala-2.12.12
export JAVA_HOME=/opt/module/java
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
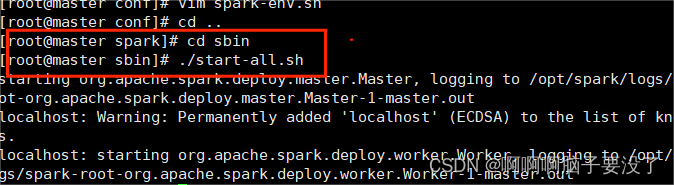
启动集群,spark下sbin目录下,./start-all.sh
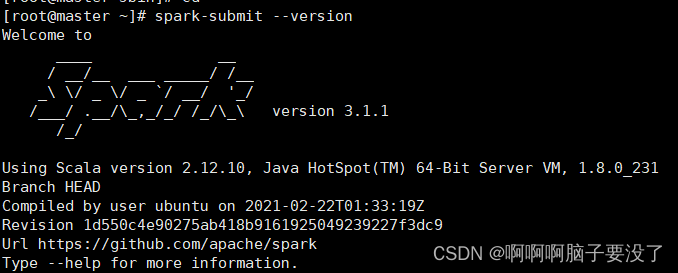
最后输入spark-submit --version查看是否成功,如图下即为成功















 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









