







0. 学习资料
B站博主 霹雳吧啦Wz
github: https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
B站: https://space.bilibili.com/18161609/video?tid=0&pn=2&keyword=&order=pubdate
1.可视化调试
可视化方法可分为:各通到相加可视化、
1.1 各通道相加可视化
def visualize_feature_map(img_batch,out_path,type,BI):
feature_map = torch.squeeze(img_batch)
feature_map = feature_map.detach().cpu().numpy()
feature_map_sum = feature_map[0, :, :]
feature_map_sum = np.expand_dims(feature_map_sum, axis=2)
for i in range(0, 2048): #各通道遍历
feature_map_split = feature_map[i,:, :]
feature_map_split = np.expand_dims(feature_map_split,axis=2)
if i != 0:
feature_map_sum +=feature_map_split # 各通到相加
feature_map_split = BI.transform(feature_map_split) #非线性差值,用于恢复图片尺寸。
plt.imshow(feature_map_split)
plt.savefig(out_path + str(i) + "_{}.jpg".format(type) )
plt.yticks()
plt.axis('off')
feature_map_sum = BI.transform(feature_map_sum)
plt.imshow(feature_map_sum)
plt.savefig(out_path + "sum_{}.jpg".format(type))
print("save sum_{}.jpg".format(type))
可视化效果如下:
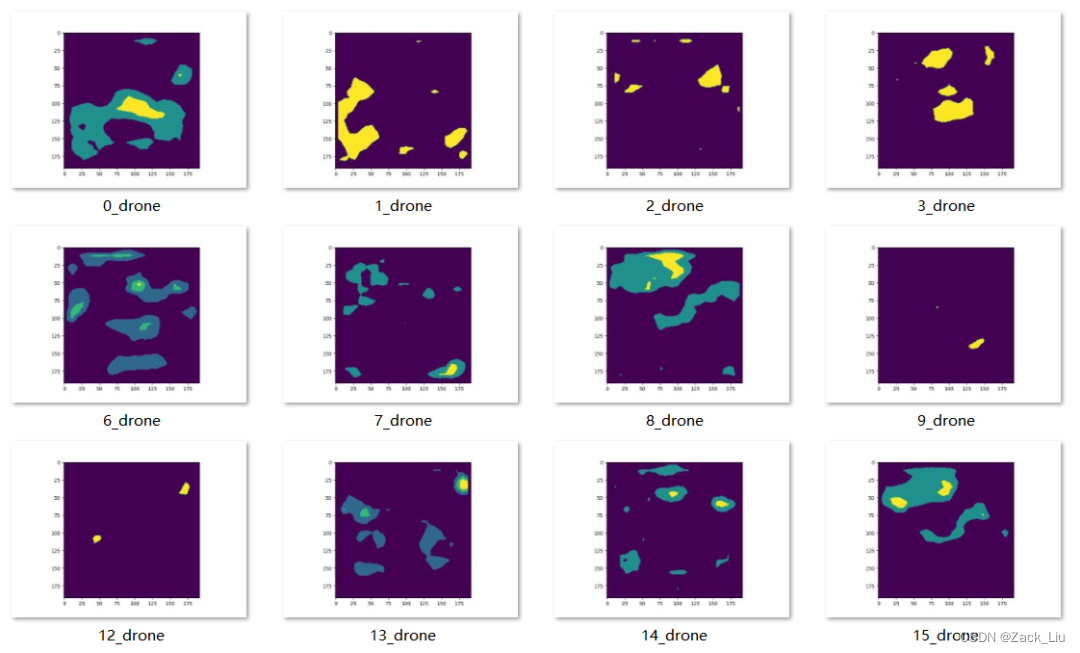
1.2 降维到3维或2维
现在主流的手段就是PCA和t-SNE。
1.3 CAM(class activation mapping) 类别激活映射图
开源方法库:
https://github.com/jacobgil/pytorch-grad-cam
https://github.com/jacobgil/keras-cam
视频讲解:
https://www.bilibili.com/video/BV1e3411j7x7/?spm_id_from=333.788.recommend_more_video.0&vd_source=e43c081338520d48e907ed94f3d8f6c8
1.4 生成网格化图片
import torch
import torchvision
from PIL import Image
# 假设有一个大小为 (B, C, H, W) 的四维张量 img_tensor
# 创建图像网格
grid = torchvision.utils.make_grid(img_tensor, nrow=4, padding=2, normalize=True)
2. 网络调试
2.1 num_workers
设置为cpu数量,或cpu数量的一半, 详情见:https://blog.csdn.net/qq_28057379/article/details/115427052
2.2 其他
经验链接:http://www.aisays.cn/post/1393.html
3. 训练策略
3.1 early stopping(早停)
EarlyStopping是用于提前停止训练的callbacks,callbacks用于指定在每个epoch开始和结束的时候进行哪种特定操作。简而言之,就是可以达到当测试集上的loss不再减小(即减小的程度小于某个阈值)的时候停止继续训练。
3.1.1 EarlyStopping的原理
1.将数据分为训练集和测试集
2.每个epoch结束后(或每N个epoch后): 在测试集上获取测试结果,随着epoch的增加,如果在测试集上发现测试误差上升,则停止训练;
3.将停止之后的权重作为网络的最终参数。
这儿就有一个疑惑,在平常模型训练时,会发现模型的loss值有时会出现降低再上升再下降的情况,难道只要再上升的时候就要停止嘛?上升之后再下降有可能会得到更低的loss值,那么如果只要上升就停止的话,就会得不偿失。现实肯定不是这样的!不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的测试集精度,当连续10次epoch(或者更多次)没达到最佳精度时,则可以认为精度不再提高了。
看图直观感受一下:
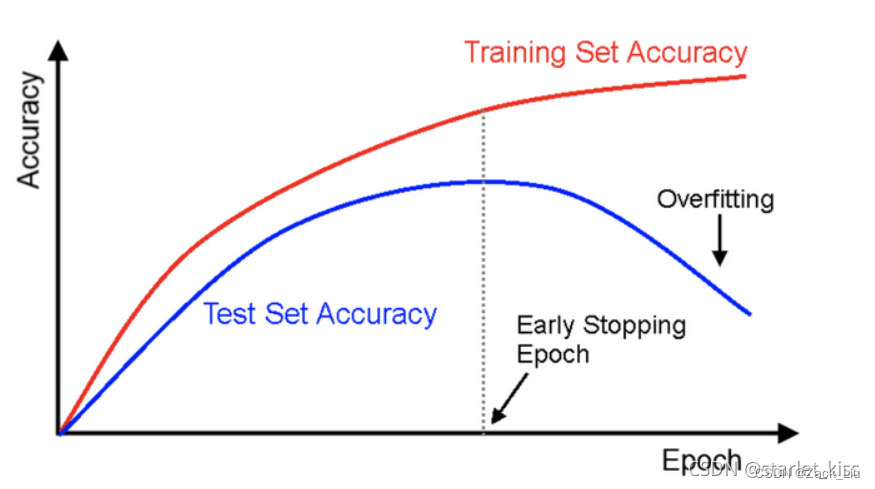
3.1.2 EarlyStopping的优缺点
优点:只运行一次梯度下降,我们就可以找出w的较小值,中间值和较大值。而无需尝试L2正则化超级参数lambda的很多值。
缺点:不能独立地处理以上两个问题,使得要考虑的东西变得复杂
3.1.3 代码实现
参考:https://blog.csdn.net/t18438605018/article/details/123646329
3.2 Fine Tune(微调)
3.2.1 概念
精细调整是指在预训练模型的基础上,通过对模型进行微调,使其适应特定任务或领域的一种方法。简而言之,就是利用预训练模型的知识,为我们的特定任务提供一个更好的初始点。
3.2.2 意义
1)提高模型性能
首先,精细调整可以有效地提高模型在特定任务上的性能。预训练模型通常在大规模数据集上进行训练,学到了很多通用的知识和特征。通过精细调整,我们可以将这些知识迁移到具体任务上,从而提高模型的性能。
2)降低训练成本
其次,精细调整可以降低训练成本。与从零开始训练模型相比,精细调整只需在预训练模型的基础上进行少量训练,大大减少了计算资源和时间的消耗。
3)适应特定领域
最后,精细调整可以使模型适应特定领域。预训练模型可能并不适用于所有任务,通过精细调整,我们可以针对特定领域的数据和任务进行优化,提高模型的实用性。
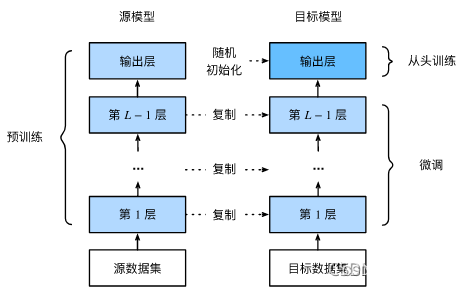
3.2.3 微调的四个步骤:
1)在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
2)创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层与源数据集的标签紧密相关,因此在目标模型中不予采用。
3)为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
4)在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
3.2.4 demo代码
参考:https://blog.csdn.net/jerry_liufeng/article/details/120028148
https://blog.csdn.net/sinat_36831051/article/details/84988174
3.3 Learning rate (学习率)调整
import torch.optim as optim
// optimizer: 神经网络所使用的优化器
// step_size: 多少轮循环后更新一次学习率
// gamma: 每次将 lr 更新为原来的 gamma 倍
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size, gamma, last_epoch = -1, verbose = False)
# 记得在训练开始进行激活
optimizer.zero_grad()
optimizer.step()
scheduler_lr.step()
4. 计算图
参考【深度学习入门与Pytorch|2.1 计算图的概念与理解】:https://zhuanlan.zhihu.com/p/412542969
5.常见问题&解决方式
5.1 loss下降
见:https://blog.csdn.net/BigDream123/article/details/115461480
5.2数据集常见问题
数据集噪声过大
数据集中存在异常值
数据集不均衡
数据集太少,容易造成过拟合。
数据预处理未进行数据归一化,导致loss不下降,或下降不充分。
5.2.1数据不均衡的危害和解决方式
一些开源数据集是高质量的,但是很多自建数据集都是不平衡的,少数的头部类占据了绝大部分样本,而大多数尾部类占据的样本却很少。
一般不同种类数据差距在10倍以上可以判定为数据不平衡问题
数据分布严重不平衡的情况下,模型将具有严重的倾向性,倾向于数据样本的多的类别,因为模型每次猜样本多对应的类别的对的次数多。
eg:
假如是基于一些特征判断病人是否患有该疾病,且该疾病是一个小概率获得的疾病,假设概率为0.0001, 那么表明有10000个来看病的人中只有一个人患有该疾病,其余9999个人都是正常病人。如果用这样的一批数据进行训练模型算法,即使该模型什么都不学,都判定为正常人,其准确率高达0.9999, 完全满足上线要求。但我们知道,这个模型是不科学的,是无用的模型。
5.2 loss充分下降
5.2.1 调整学习率
5.2.1.1 自动调整学习率
https://aistudio.baidu.com/projectdetail/3743075
https://zhuanlan.zhihu.com/p/350712244?utm_id=0
https://blog.csdn.net/Roaddd/article/details/113260677
https://blog.csdn.net/weixin_42392454/article/details/127766771
5.2.2 梯度裁剪防止梯度消失或梯度爆炸
https://blog.csdn.net/Mikeyboi/article/details/119522689
https://zhuanlan.zhihu.com/p/353871841
5.3 过拟合问题
过拟合(overfitting)是指机器学习模型在训练数据集上表现得很好,但是在新的、未见过的数据集上表现得很差的现象。
过拟合的原因一般是模型过于复杂,导致模型在训练数据上过于准确地拟合了噪声和细节,从而失去了泛化能力。
过拟合的表现包括模型在训练集上的损失(或错误率)很小,但在测试集或验证集上的损失很大,或者模型在训练集上的预测效果很好,但是在测试集或验证集上的预测效果很差。
解决过拟合的方法包括:
简化模型结构,如减少模型参数、降低网络层数等;
增加数据量,如采集更多的数据或使用数据增强技术;
添加正则化,如L1、L2正则化、dropout等;
早停法(early stopping),即在模型在验证集上表现开始下降时停止训练。
5.4 加快网络收敛 & 训练速度
5.4.1 batch nom
Batch Normalization主要是为了解决internal covariate shift的问题。
什么是internal covariate shift问题呢?简单的说就是后一层要去处理前一层给的数据,而由于前一层的参数变化,后一层的输入分布会跟着变化,后一层的训练也要跟着分布的变化而变化。在深度神经网络中,往往有多层神经元,而前一层参数的变化会造成后层的剧烈变化。
我们可以想象,后一层好不容易把前一层给的数据训练的差不多了,前一层的参数一调,后面的神经元又得从头学习。这个过程很浪费时间,特别是在早期训练过程中。
基本思想
所以我们的基本思想就是,能不能让每一层输入的分布不要剧烈变动?最好它是同分布的。
如何让他们同分布呢?我们可以很容易想到利用normalization、白化这些方法来进行处理,就像我们对数据进行预处理一样。
好的,那么我们先来回顾一下normalization的作用。我们为什么要对数据进行normalization处理?
一般来说,我们得到的数据都是Figure 1, 而我们的随机化参数一般都在零点附近,所以如果不做任何操作的话,我们要先一路摸到数据均值点附近,才能进行比较好的分类。如果这个数据离原点比较远,那么我们就要花费很多的时间来摸到数据均值点附近了,这个其实是没什么意义的。
好,那么我们现在把数据拉到原点附近,这样就可以比较快的训练了。如figure 2.
还有的时候,特别是处理图片数据时,数据样本之间的相关性很大,所以得到的数据样本分布比较狭长,如Figure 3。这也是不利于我们训练的。想象一下,你对W稍微一调整分界超平面就飞出了样本外,真是糟糕。所以这个时候我们还对它进行一个操作,使它的方差为1,让它的分布比较均匀,如Figure 4.
如果我们再对它进行白化操作,使它的方差最大,数据和数据之间分布尽可能大,那我们的效果会更好。
好,既然我们知道了normalization的神奇作用,那我们就可以利用它来对付我们的internal covariate shift问题了。那想法很简单,我们在每次要送到激活函数前,进行一下normalization就可以了。
真的吗?
我们来观察一下sigmoid函数和relu函数
想一想,如果我们在送到激活函数前,对它进行了normalization,会发生什么?
对了,对于sigmoid函数,我们的数据会集中在-1,1这样的区间里。恩,它的变化很剧烈,收敛很快。但我们发现中间是近似于线性的,也就是说,我们相当于在用一层又一层的线性函数去做了训练。天哪,我们在干什么,难道我们不知道多层的线性和单层的线性效果是一样的吗。我们削弱了模型的刻画能力。
我们再看看relu,对relu来说,有人说我们产出了一堆随机0,1的,这个…我再求证一下。论文里并没有提到这个。
那可如何是好?论文引入了scal and shift,简单的说,就是在normalization之后,再进行一些移动和放缩,让它避免之前提到的那个问题。而这个参数,则由模型训练得到。
事实上,我觉得还是有点不讲理的,好不容易把大家的分布都进行了一个归一化,整到了一起,又特别来一个移动和放缩操作来把大家的分布脱离归一化。这也是这篇论文的争议之一。
我目前是这样理解的:
事实上,我们的目的是让每一层拿到一个稳定的分布进行处理,但我们直接进行归一化操作是“粗暴的”。我们让所有层要处理的“稳定分布”指定为均值为0,方差为1的分布。加入这样一个可训练的参数后,我们就允许每一层拥有一个属于它自己的稳定分布,并且这个分布是有效的,没有让激活函数失去非线性。
不过只是我目前的理解。欢迎讨论,如果以后有新的理解会再补充在这里。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











