







深度学习比较典型的应用领域,包括人脸识别,物体识别,语音识别,以及自然语言处理(机器翻译),风格转换,图像生成六种。在深度学习中,现在效果最好的是在图片,视频,音频领域,也就是对应的人脸识别,物体识别,语音识别,深度学习针对图片,视频,音频领域数据类型应用效果最好,跟传统方法相比提升了30~50%。
分类:根据学习环境不同,神经网络的学习方式可分为监督学习和非监督学习。
1. 各种网络框架及其联系
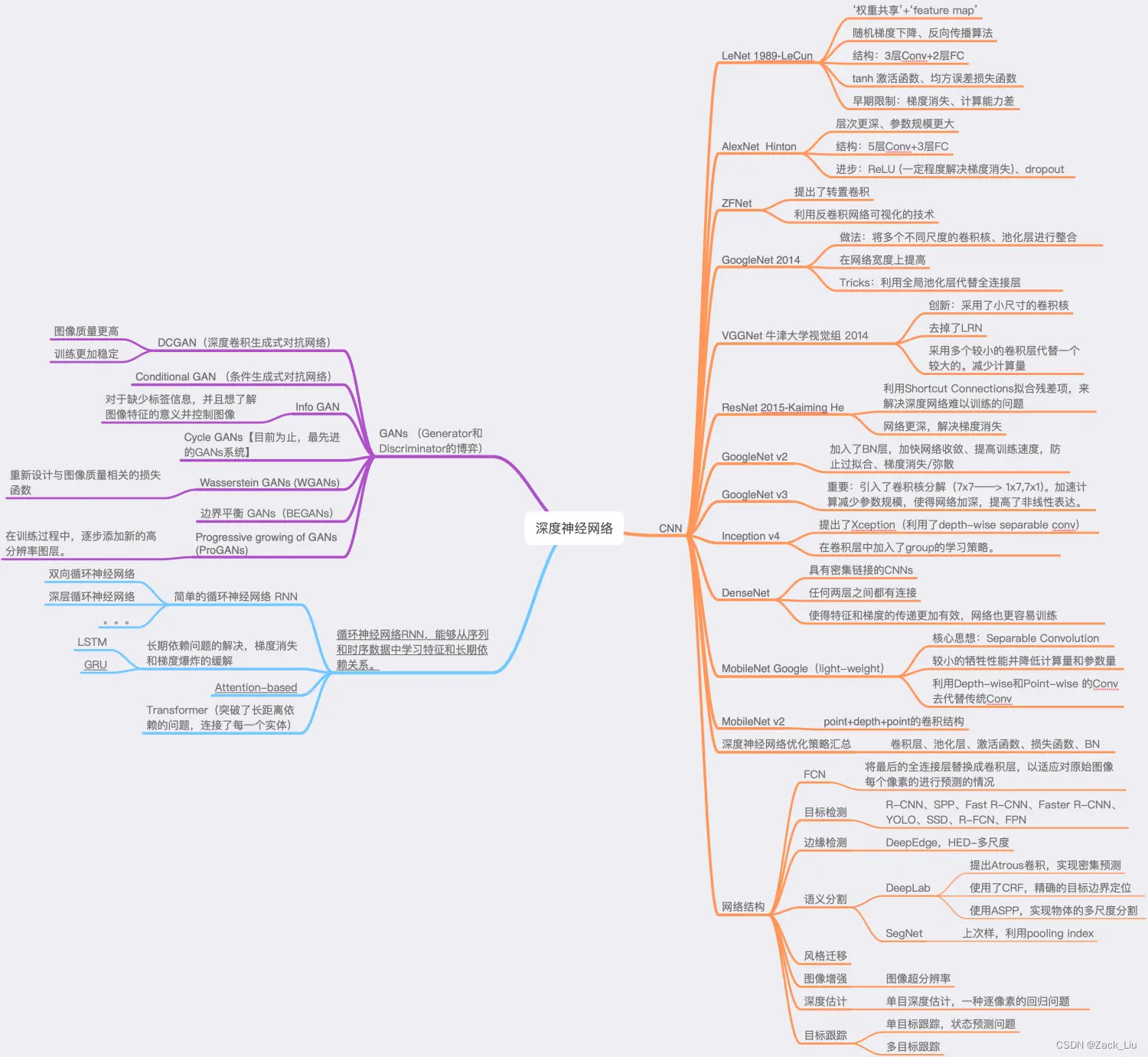
1.1 两阶段与一阶段区别
1.1.1 detectron算法框架套路:
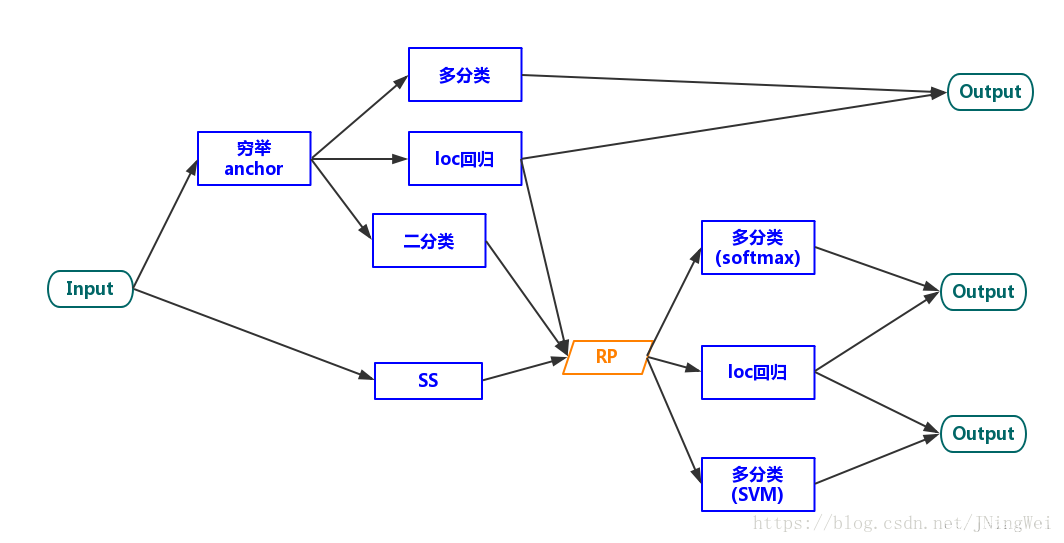
1.1.2 multi-stage
最早期的检测算法 (主要为R-CNN、SPPNet) 都属于multi-stage系。这个时候的Selective Search、Feature extraction、location regressor、cls SVM是分成多个stage来各自单独train的。故谓之曰“multi-stage”:
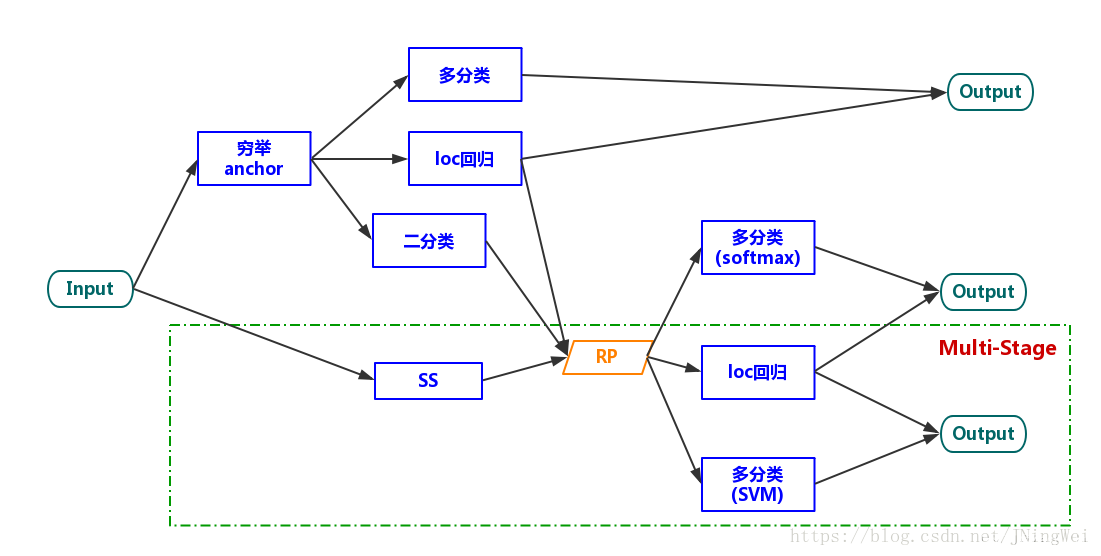
1.1.3 two-stage 算法
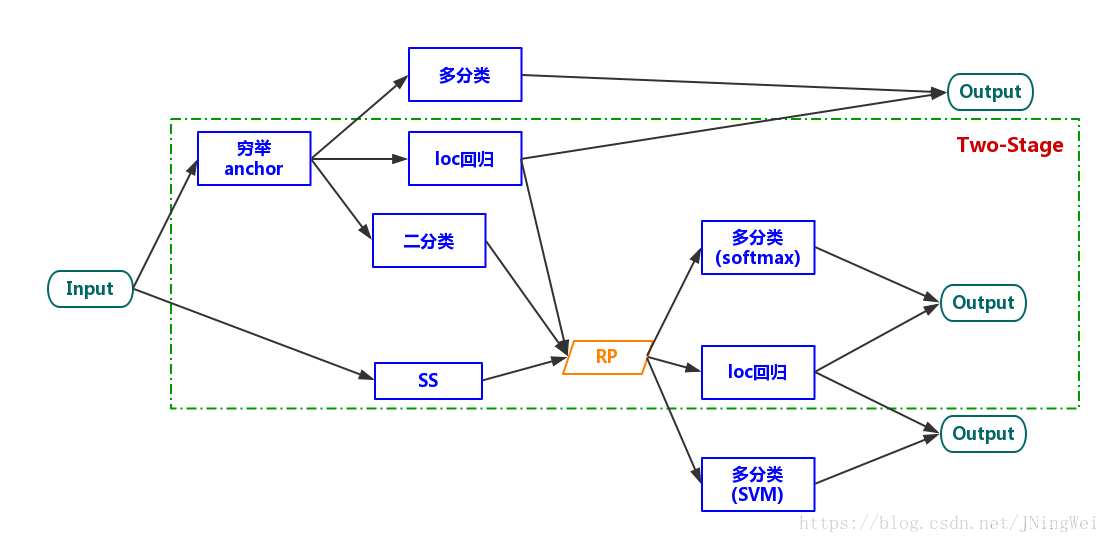
到了Fast R-CNN的时候,Feature extraction、location regressor、cls SVM都被整合到了一个network里面,可以实现这三个task一起train了。由于生成RP的task还需要另外train,故谓之曰“two-stage”:
到了Faster R-CNN中,虽然RPN的出现使得四个task可以一起被train,但由于要生成RP,依然被归类为“two-stage”。
1.1.4 one-stage 算法
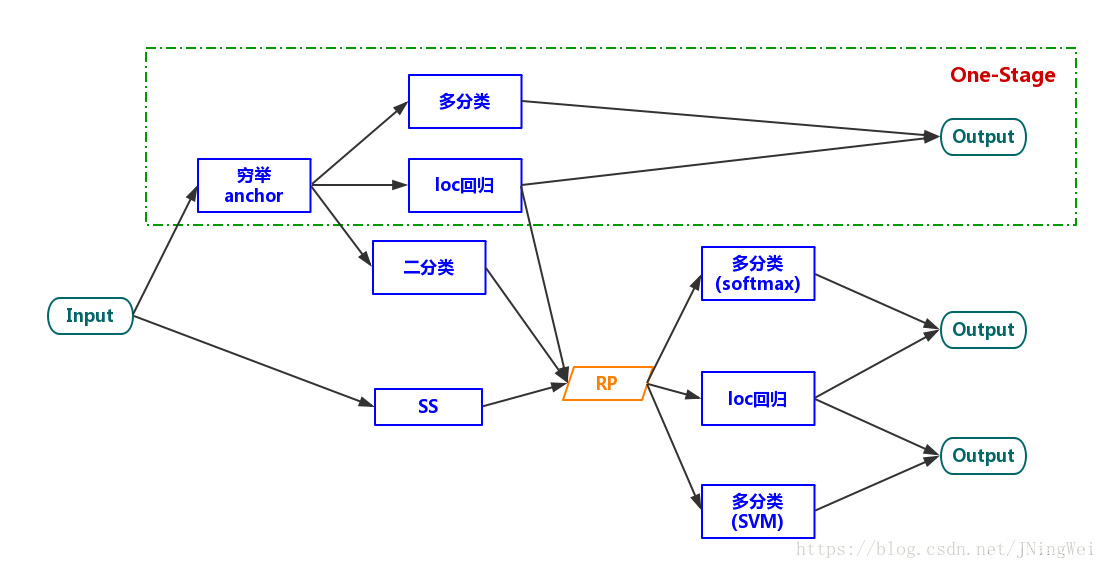
在YOLOv1中,“生成RP”这一任务被直接丢弃了。因此,整个算法只剩下了一个stage,故谓之曰“one-stage”:
2. 常用算法
2.1 SS(选择性搜索算法,Selective Search)
链接:https://blog.csdn.net/weixin_43694096/article/details/121610856
code:
%matplotlib inline
from keras.preprocessing import image
import skimage.data
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import selectivesearch
import numpy as np
import cv2
# 加载图片数据
#img = skimage.data.checkerboard()
img_path =r'D:\CV\datasets\mypic\2.png'
img = image.load_img(img_path, target_size=(480, 600))#(h,w)
img = image.img_to_array(img)
img=img.astype('uint8')
img_lbl, regions = selectivesearch.selective_search(img, scale=500, sigma=0.9, min_size=20)
#计算一共分割了多少个原始候选区域
temp = set()
for i in range(img_lbl.shape[0]):
for j in range(img_lbl.shape[1]):
temp.add(img_lbl[i,j,3])
print(len(temp))
print(len(regions))#计算利用Selective Search算法得到了多少个候选区域
#创建一个集合 元素list(左上角x,左上角y,宽,高)
candidates = set()
for r in regions:
if r['rect'] in candidates:#排除重复的候选区
continue
if r['size'] < 500:#排除小于 2000 pixels的候选区域(并不是bounding box中的区域大小)
continue
x, y, w, h = r['rect']
if w / h > 2 or h / w > 2: #排除扭曲的候选区域边框 即只保留近似正方形的
continue
candidates.add(r['rect'])
for x, y, w, h in candidates:
#print(x, y, w, h)
cv2.rectangle(img, (x, y), ( x+w,y+h), (0, 0, 255), 1)
plt.figure(figsize=(12,10))
plt.imshow(img)
plt.axis('off')
plt.savefig('ss.png')
plt.show()
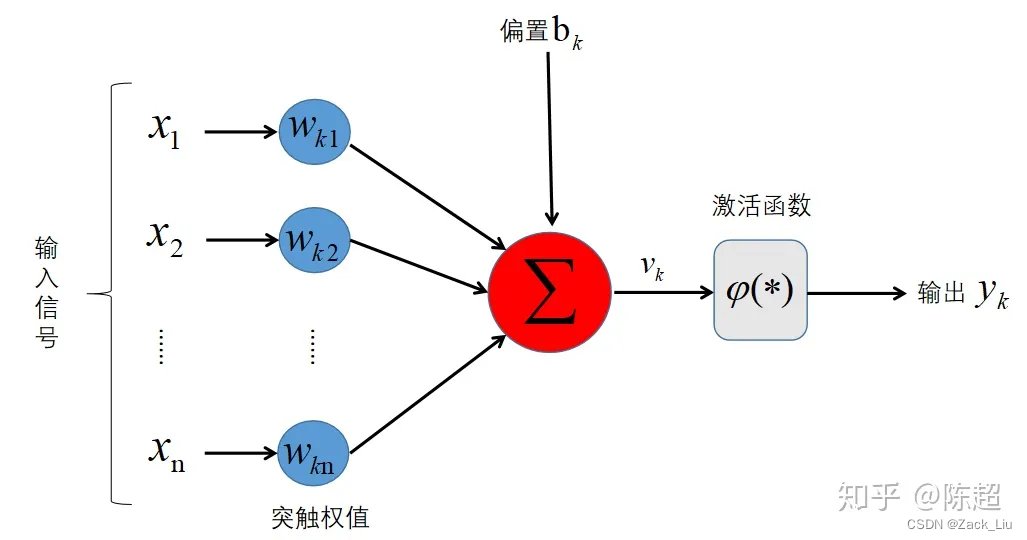
3. 神经元模型


4. 神经网络分类
神经网络可以分为三种主要类型:前馈神经网络、反馈神经网络和图神经网络。
4.1 前馈神经网络
前馈神经⽹络(feedforward neural network)是⼀种简单的神经⽹络,也被称为多层感知机(multi-layer perceptron,简称MLP),其中不同的神经元属于不同的层,由输⼊层-隐藏层-输出层构成,信号从输⼊层往输出层单向传递,中间⽆反馈,其⽬的是为了拟合某个函数,由⼀个有向⽆环图表⽰,如下:
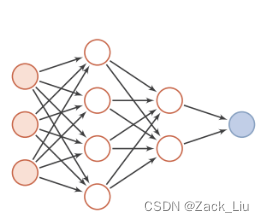
前馈神经⽹络中包含激活函数(sigmoid函数、tanh函数等)、损失函数(均⽅差损失函数、交叉熵损失函数等)、优化算法(BP算法)等。常⽤的模型结构有:卷积神经⽹络、全连接神经⽹络、BP神经⽹络、RBF神经⽹络、感知机等。
下面介绍下经典的卷积神经网络:
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积运算且具有深度结构的前馈神经网络(Feedforward Neural Networks)。相比早期的BP神经网络,卷积神经网络最重要的特性在于“局部感知”与“参数共享”。
整体架构:输入层——卷积层——池化层——全连接层——输出层
5.计算机视觉核心任务
5.1 分类
是根据图像的语义信息对不同类别图像进行区分。即首先确认图像中有哪几类目标,然后根据图像所包含的目标对单个图像进行聚类或者对多个图像进行分类。
比如在学习分类中数据集有人(person)、羊(sheep)、狗(dog)和猫(cat)四种,图像分类要求给定一个图片输出图片里含有哪些分类,比如下图的例子是含有person、sheep和dog三种。

5.2 检测
检测相交于分类,不光需要识别出图片中的目标类别,还需要给出目标类别的bounding box和标签。即除了说明有哪几类,还需要说明位置。
如下图,人脸检测(人脸为目标、背景为非目标)、汽车检测(汽车为目标、背景为非目标)

5.3 识别
在检测的基础上,进行识别。例如:在一张图片检测出了10个人脸中识别出哪个是小明的脸。
5.4 语义分割(Semantic Segmentation)
在检测的基础上,要达到像素级别的精确度。羊这一类别是哪些像素,从另一方面,每一像素属于什么类别。但不需要区分羊1,羊2

5.5 实例分割 (Instance Segmentation)
相交于语义分割,需要区分羊1、羊2.

5.6 目标跟踪
单目标跟踪VOT:直接预测位置。
多目标跟踪MOTL:匈牙利算法
6.常识
6.1 浅层特征、浅层网络、局部信息
浅层特征:浅层网络提取的特征和输入比较近,蕴含更多的像素点的信息,主要为一些细粒度的信息,比如颜色、纹理、边缘、棱角信息。
原理:浅层网络感受野较小,感受野重叠区域也较小,所以保证网络捕获更多细节
浅层网络:一般感受野较小,能够利用更多的细粒度特征信息,而且此时特征图每个像素点对应的感受野重叠区域还很小,这就保证了网络能够捕获更多细节。
局部信息:局部信息来源于浅层网络,即细粒度信息,此时的感受野比较小,故浅层网络得到的特征图局部信息比较丰富,该级别的特征图分辨率比较高,单个像素的感受野比较小,可以捕捉更多小目标的信息。
浅层网络提取的往往是比较细节的特征或者小目标。
6.2 深层特征、深层网络、全局信息
深层特征:深层网络提取的特征离输出较近,蕴含更抽象的信息,即语义信息,主要为一些粗粒度的信息。
原理:感受野增加,感受野之间重叠区域增加,图像信息进行压缩,目的是获取的是图像整体性的一些信息。
深层网络:随着下采样或卷积次数增加,感受野逐渐增加,感受野之间重叠区域也不断增加,此时的像素点代表的信息是一个区域的信息,获得的是这块区域或相邻区域之间的特征信息,相对不够细粒度,但语义信息丰富
全局信息:全局信息来源于深层网络,此时随着网络的加深,感受野变大,故深层网络得到的特征图全局信息更加丰富,该级别的特征图分辨率比较低,单个像素的感受野比较大,可以捕获更多中、大目标的信息。
深层网络往往提取的是全图语义信息或者较大目标的信息。
6.3 全连接层作用
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
目前由于全连接层参数冗余,仅全连接层参数就可占整个网络参数80%左右。
FC可在模型表示能力迁移过程中充当“防火墙”的作用。
微调(fine tuning)是深度学习领域最常用的迁移学习技术。针对微调,若目标域(target domain)中的图像与源域中图像差异巨大(如相比ImageNet,目标域图像不是物体为中心的图像,而是风景照,见下图),不含FC的网络微调后的结果要差于含FC的网络。因此FC可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。(冗余的参数并不一无是处。)
如果想提升预测性能,可用GAP(全局平均池化)代替全连接层,例如resnet和GoogLeNet
全链接层由于参数量较大,容易出现过拟合,可以使用一些正则化方法避免过拟合。
6.4 正则化作用
6.4.1 Dropout正则化
Dropout是一种常用的正则化方法,用于减少神经网络的过拟合现象。它的基本思想是在训练神经网络的过程中,随机地将一部分神经元的输出值置为0,从而使得神经网络的结构变得不稳定,从而强制网络学习到更加鲁棒的特征表示。
具体来说,Dropout在训练过程中,对于每个神经元以一定的概率进行保留或者丢弃。通常情况下,保留概率为p,丢弃概率为1−p,可以通过一些随机采样的方法来实现。在前向传播过程中,被丢弃的神经元的输出值会被置为0;在反向传播过程中,被丢弃的神经元也不参与误差反向传播,从而减少神经网络的参数量和模型复杂度,进而避免过拟合。
Dropout的好处是可以让神经网络学习到更加鲁棒的特征表示,从而提高模型的泛化能力。同时,Dropout还可以起到一定的正则化作用,使得神经网络中的权重参数更加平滑,进一步减少过拟合的风险。
需要注意的是,Dropout只在训练过程中使用,在测试过程中应该关闭Dropout,以便得到更加准确的输出结果。
6.4.2 L1/L2正则化简介(讲的不好,需要优化)
1)L1
L1(也称为Lasso)正则化是指在神经网络的损失函数中添加一个L1范数惩罚项,用来惩罚模型权重参数中的大值,使得模型权重变得更加稀疏。L1正则化的效果是使得模型中的一些无关紧要的特征的权重变为0,从而减小模型的复杂度。
L1正则化的公式为:
(2)L2
L2正则化是指在神经网络的损失函数中添加一个L2范数惩罚项,用来惩罚模型权重参数的平方和。L2正则化的效果是让所有的权重都尽可能小,从而减小模型的复杂度。
L2正则化的公式为:
。
在实际应用中,L1和L2正则化可以分别通过在损失函数中添加对应的惩罚项来实现。在优化过程中,加上正则化项对应的梯度会影响权重的更新,使得权重不会过大。同时,正则化项的权重需要根据实际情况进行调整,以充分发挥正则化的作用。
7 网络各模块作用
7.0最优网络配置
从各种网络的发展经验来看,最优网络配置如下:
1、优先使用多层小卷积核,替代打卷积核,因为小卷积核可以提供更多非线性,且参数量更小。
卷积后接dropout,防止过拟合。
7.1 dropout作用
用于防止过拟合,一般位于特征提取层之后,任务头全连接层之前。eg:alexnet
因为一个神经元不能依赖特定的其他神经元的存在。因此,它被迫学习更强大的特征。
7.2 ReLU作用
使用ReLU激活函数的原因:就梯度下降的训练时间而言,饱和非线性( tanh 激活函数)比非饱和非线性(ReLU 激活函数) f(x) = max(0; x) 慢得多。具有 ReLU 的深度卷积神经网络的训练速度比具有 tanh 单元的等效网络快几倍。
8 各网络总结
8.0 网络设计经验
0、总体架构为卷积-> pooling->BN->mlp
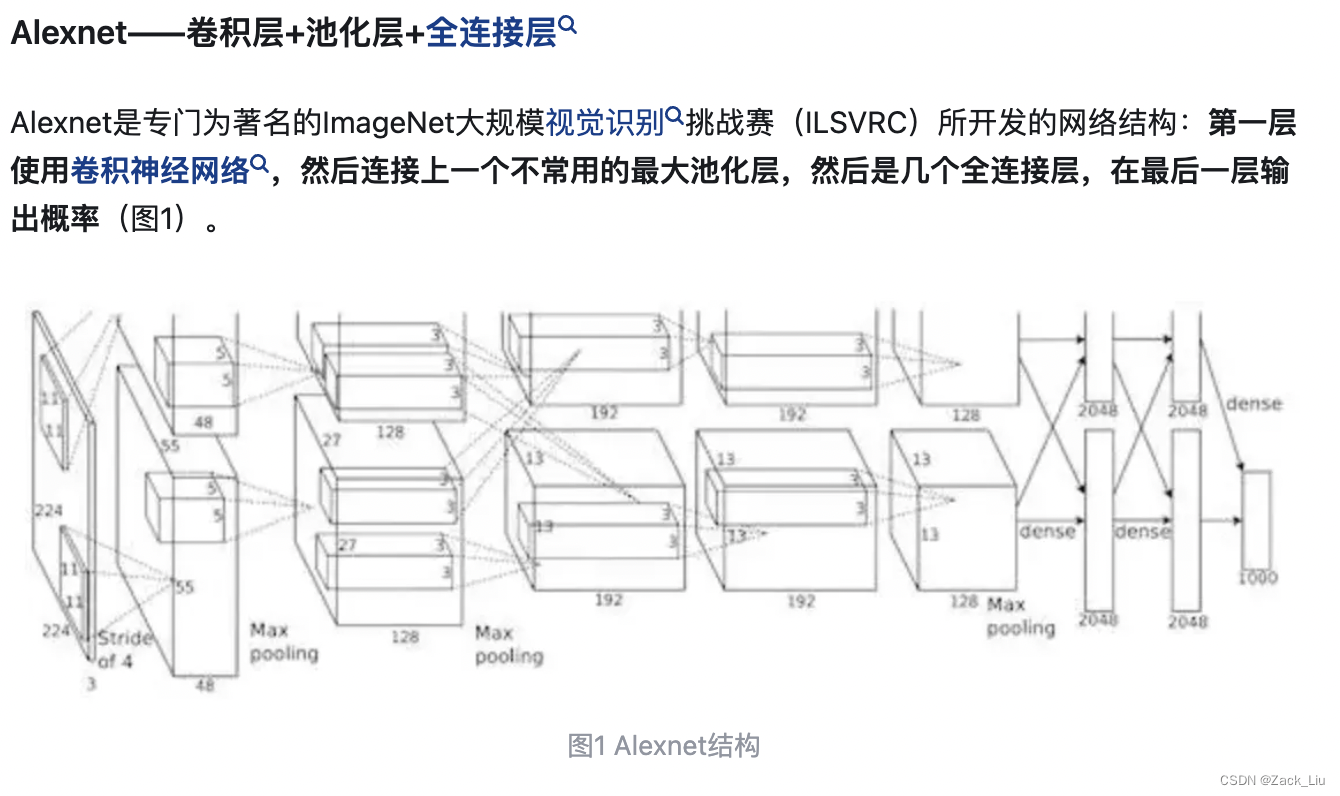
eg: alexnet:
1、目前的cnn一般是[CONV - RELU - POOL]
2、增加Dropout模块抑制过拟合;
3、优化函数:
常用有relu 和sigmoid:
(1) sigmoid容易梯度消失
(2)使用ReLU代替Sigmoid作为激活函数,减少梯度消失现象;
4、用数据增广抑制过拟合
5、优先用小卷积,参数量小且 更多非线性层可拟合更复杂的函数,学习更复杂的模式
6、可用一维卷积压缩通道,降低模型参数
7、可用多层特征分别分类,以缓解梯度消失
8、关于分类头设计
1、有的利用自适应平均池化,将HW变为(1,1)然后利用通道 + 全连接层映射到分类结果,eg: ResNet
2、有的是通道 和size直接拍平,然后再映射到分类结果。
9、不同特征层输出相加方式
1、直接在元素上相加 即: out += x, eg: resnet
2、在通道{又名:深度}上相加,即: torch.cat((x_ch0, x_ch1, x_ch2), 1), eg: GoogleLeNet
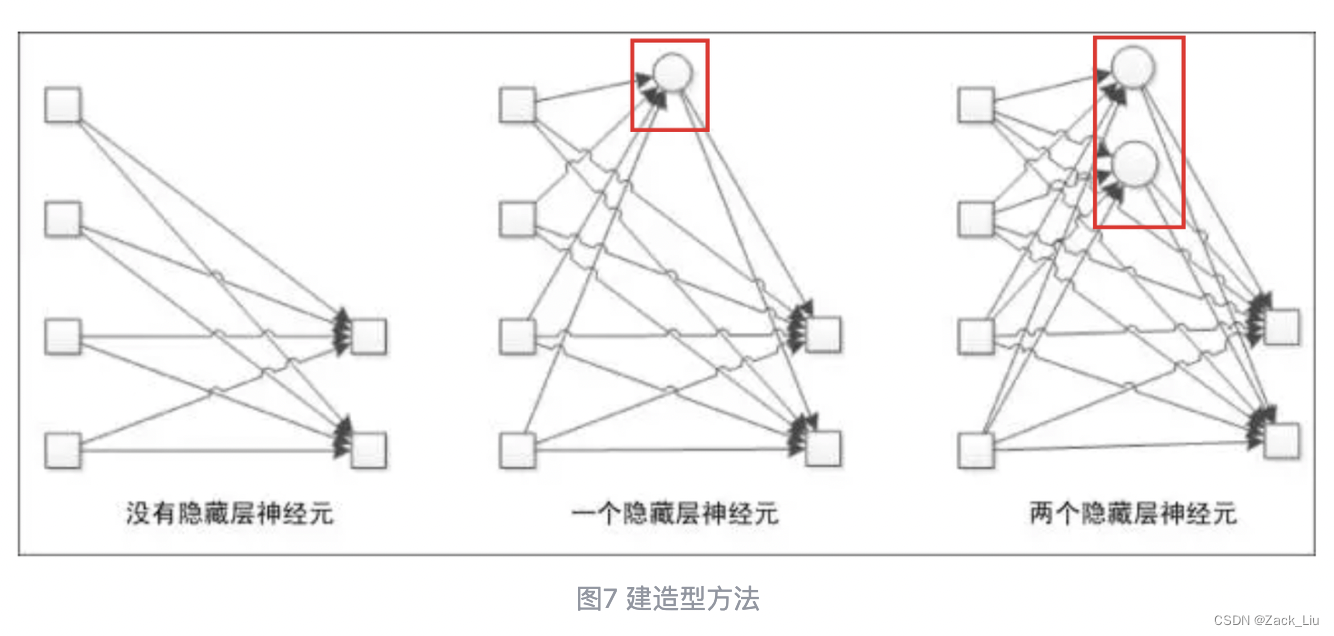
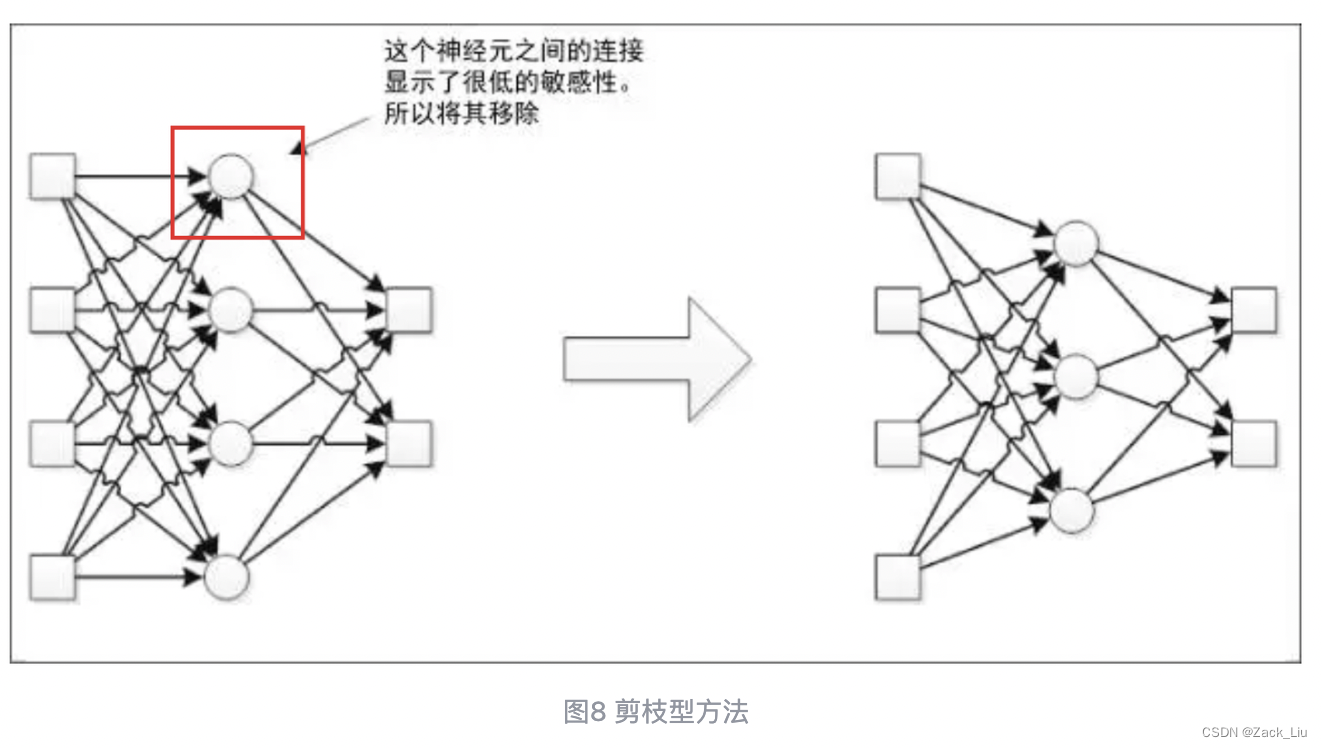
8.0.1 神经网络结构优化的两种方法论:建造型和剪枝型
建造型方法指的是一开始只确定输入层和输出层,接着开始往隐藏层增加新的神经元,直到得到一个好的结果(图7)。
破坏型方法,也称为剪枝型,它基于较大的结构工作,当神经元数量有很多时,“剪掉”那些敏感度低,也就是对输出贡献较小的神经元(图8)。
8.1 LeNet(1998)
意义:基本与现代cnn结构一致
8.2 AlexNet(2012)
意义:
1、使用ReLU代替Sigmoid作为激活函数,减少梯度消失现象;
2、增加Dropout模块抑制过拟合;
3、数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
8.3 VGG(2014)
意义:采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)
8.4 GoogleLeNet(2014)
意义:1、Inception模块使用多尺度卷积核,相比于单尺度的卷积核,在对不同尺度的特征提取上,更有优势;
2、一维卷积使用:1*1 conv(最初提出的并非GoogLeNet,而是Network In Network这篇论文)的使用有效地减少了conv的深度,减少模型参数;
3、模型增加softmax0和softmax1,在训练的时候,将三个分类器的损失函数进行加权求和,以缓解梯度消失现象。
即:使用不同level特征分别进行分类,以缓解梯度消失现象。
9 pytorch
9.1 nn.Parameter()
nn.Parameter() 是 PyTorch 中的一个类,用于创建可训练的参数(权重和偏置),这些参数会在模型训练过程中自动更新。
nn.Parameter() 具有以下特点:
nn.Parameter() 继承自 torch.Tensor,因此它本质上也是一个张量(tensor),可以像普通张量一样进行各种张量操作,例如加法、乘法、索引等。
nn.Parameter() 具有额外的属性 requires_grad,用于指定参数是否需要计算梯度。默认情况下,requires_grad 的值为 False,即参数不会计算梯度。当设置为 True 时,参数会在反向传播过程中计算梯度,并且可以通过优化器进行自动更新。
nn.Parameter() 对象可以作为模型的成员变量,例如通过类的属性进行定义,这样在模型的前向传播和反向传播过程中可以自动识别并更新这些参数。
从以下代码中可以看出,nn.Parameter本质上是一个可学习的矩阵,linear和conv2d的weight和bias本质上就是nn.Parameter().
import torch
import torch.nn as nn
from torch.optim import Adam
class NN_Network(nn.Module):
def __init__(self,in_dim,hid,out_dim):
super(NN_Network, self).__init__()
self.linear1 = nn.Linear(in_dim,hid)
self.linear2 = nn.Linear(hid,out_dim)
self.linear1.weight = torch.nn.Parameter(torch.zeros(in_dim,hid))
self.linear1.bias = torch.nn.Parameter(torch.ones(hid))
self.linear2.weight = torch.nn.Parameter(torch.zeros(in_dim,hid))
self.linear2.bias = torch.nn.Parameter(torch.ones(hid))
def forward(self, input_array):
h = self.linear1(input_array)
y_pred = self.linear2(h)
return y_pred
in_d = 5
hidn = 2
out_d = 3
net = NN_Network(in_d, hidn, out_d)
nn.Parameter()可用于网络学习一个初始变量,该变量用于学习到最优值,eg.注意力机制中的权重参数、Vision Transformer中的class token和positional embedding等。
9.2 nn.embedding
Embedding用于将输入向量化,实际是一个索引表或查找表,它是符合随机初始化生成的正太分布的表,将输入向量化,其结构如下:
nn.Embedding(num_embeddings, embedding_dim)
“”“第1个参数 num_embeddings 就是生成num_embeddings个嵌入向量。
第2个参数 embedding_dim 就是嵌入向量的维度,即用embedding_dim值的维数来表示一个基本单位。”“”
















 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











