






点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源丨量子位
编辑丨极市平台
导读
清华大学计图团队和南开大学程明明教授团队、卡迪夫大学Ralph R. Martin教授合作,在ArXiv上发布关于计算机视觉中的注意力机制的综述文章。该综述系统地介绍了注意力机制在计算机视觉领域中相关工作
清华计图胡事民团队的这篇注意力机制的综述火了!
在上周的arXiv上,这是最热的一篇论文:
推特以及GitHub上也有不低的热度:
而这篇论文引用近200篇内容,对计算机视觉领域中的各种注意力机制进行了全面回顾。
在大量调查之后,论文将注意力机制分为多个类别,GitHub还给出了各类别下提到内容的PDF下载文件:

现在,就来一起看看这篇论文。
文章主要内容
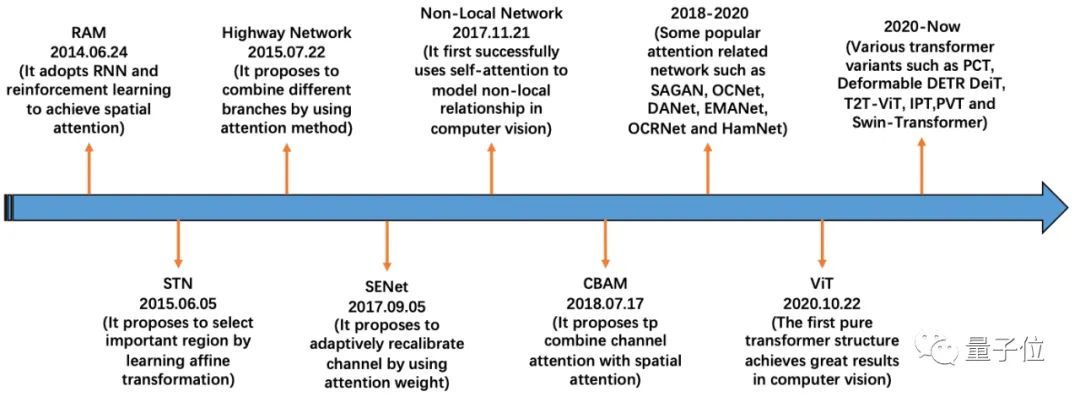
论文首先将基于注意力的模型在计算机视觉领域中的发展历程大致归为了四个阶段:
将深度神经网络与注意力机制相结合,代表性方法为RAM
明确预测判别性输入特征,代表性方法为STN
隐性且自适应地预测潜在的关键特征,代表方法为SENet
自注意力机制
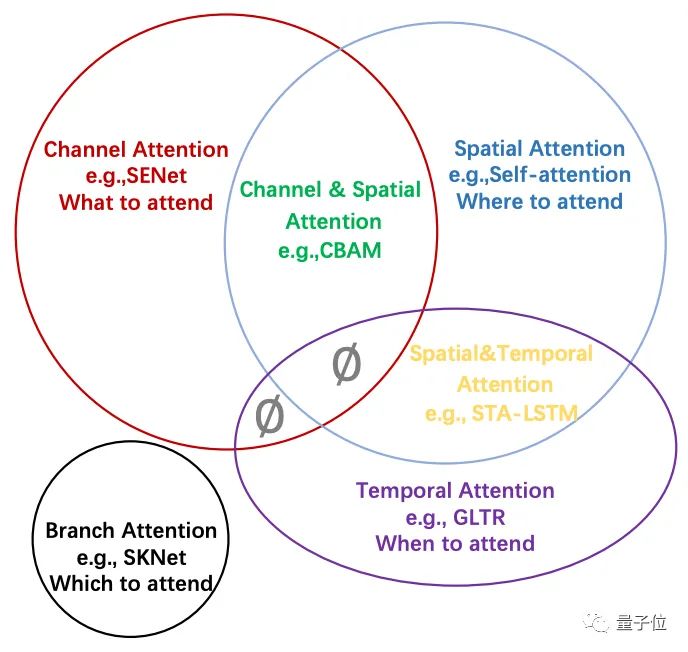
同时,注意力机制也被分为了通道注意、空间注意、时间注意、分支注意,以及两个混合类别:
针对不同类别,研究团队给出了其代表性方法和发展背景:
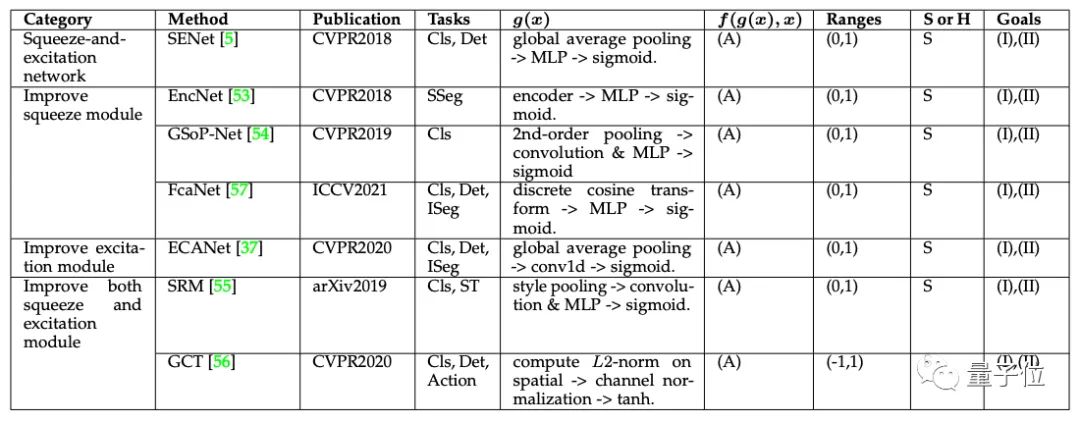
通道注意力(Channel Attention)
在深度神经网络中,不同特征图的不同通道常代表不同对象。
而通道注意力作为一个对象选择过程,可以自适应地重新校准每个通道的权重,从而决定关注什么。
因此,按照类别和出版日期将代表性通道关注机制进行分类,应用范围有分类(Cls)、语义分割(SSeg)、实例分割(ISeg)、风格转换(ST)、动作识别(Action)。
其中,(A)代表Channel-wise product,(I)强调重要通道,(II)捕捉全局信息。
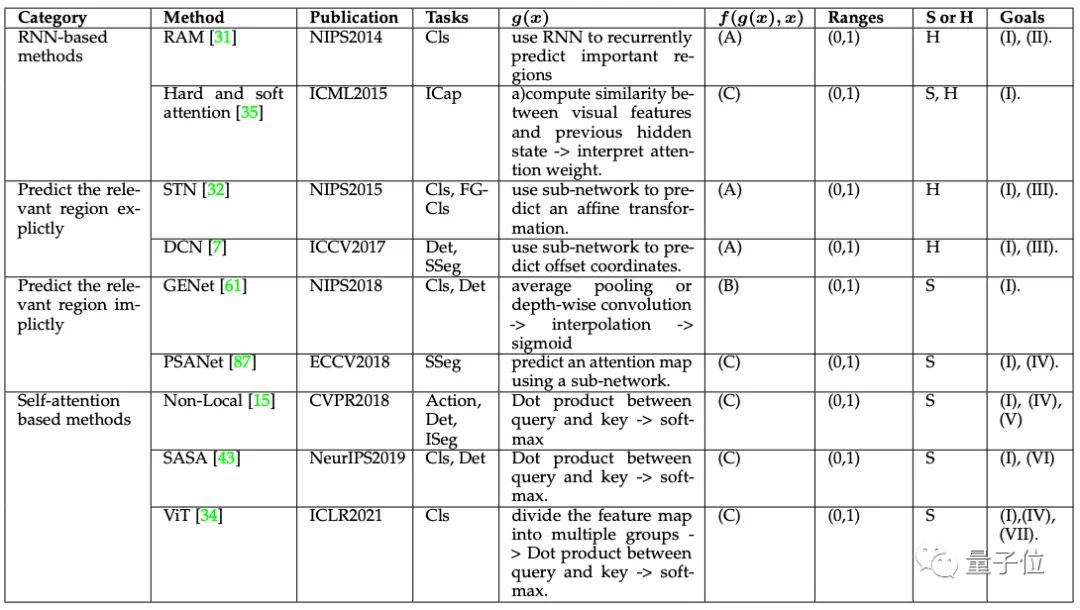
空间注意力(Spatial Attention)
空间注意力可以被看作是一种自适应的空间区域选择机制。
其应用范围比通道注意力多出了精细分类(FGCls)和图像字幕(ICap)。
时间注意力(Temporal Attention)
时间注意力可以被看作是一种动态的时间选择机制,决定了何时进行注意,因此通常用于视频处理。

分支注意力(Branch Attention)
分支注意可以被看作是一种动态的分支选择机制,通过多分支结构决定去注意什么。

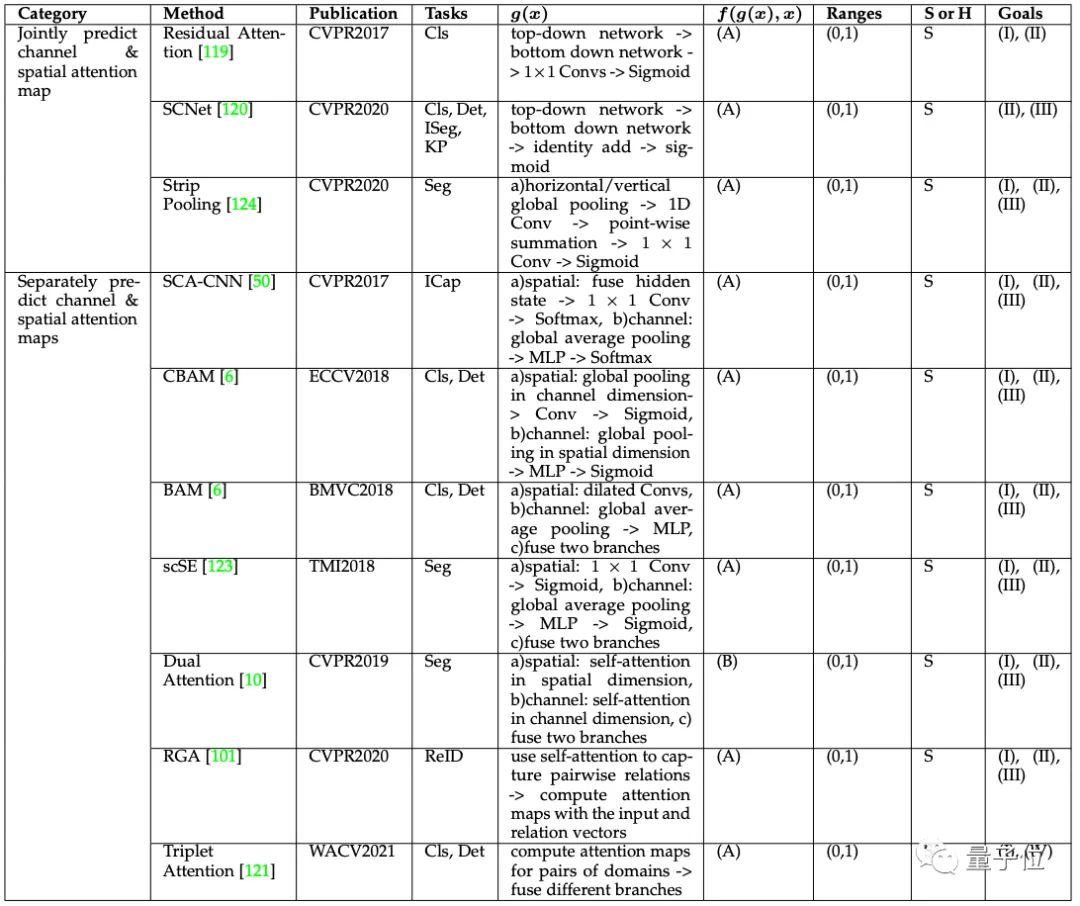
通道空间注意力(Channel & Spatial Attention)
通道和空间结合的注意力机制可以自适应地选择重要的对象和区域,由残差注意力(Residual Attention)网络开创了这一内容。
在残差注意力之后,为了有效利用全局信息,后来的工作又相继引入全局平均池化(Global Average Pooling),引入自注意力机制等内容。
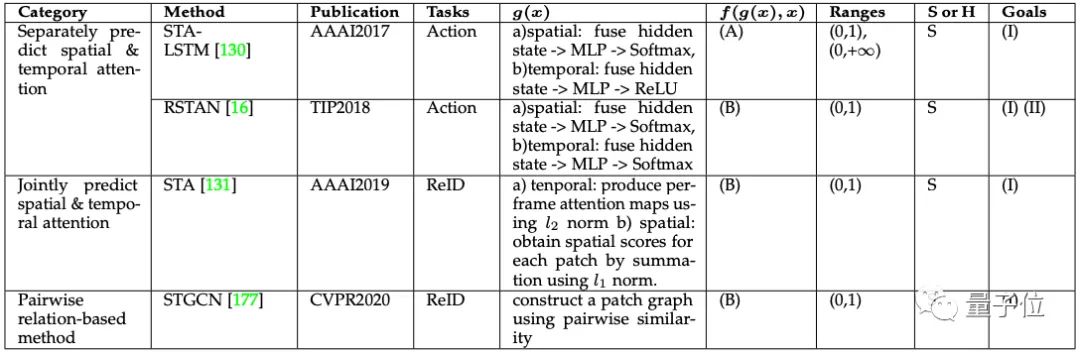
时空注意力(Spatial & Temporal Attention)
时空注意力机制可以自适应地选择重要区域和关键帧。
最后,作者也提出了注意力机制在未来的一些研究方向:
探索注意力机制的必要和充分条件
是否可以有一个通用的注意块,可以根据具体的任务在各类注意力机制之间进行选择
开发可定性和可解释的注意力模型
注意力机制可以产生稀疏的激活,这促使我们去探索哪种架构可以更好地模拟人类的视觉系统
进一步探索基于注意力的预训练模型
为注意力模型研究新的优化方法
找到简单、高效、有效的基于注意力的模型,使其可以广泛部署
关于作者
这篇论文来自清华大学计算机系胡事民团队。
胡事民为清华大学计算机系教授,教育部长江学者特聘教授,曾经和现任IEEE、Elsevier、Springer等多个期刊的主编、副主编和编委。同时,他也是清华“计图”框架团队的负责人,这是首个由中国高校开源的深度学习框架。

文章一作为胡事民教授的博士生国孟昊,现就读于清华大学计算机系,也是清华计图团队的一员。

各类资源汇总链接:
https://github.com/MenghaoGuo/Awesome-Vision-Attentions
论文地址:
https://arXiv.org/abs/2111.07624
如果觉得有用,就请分享到朋友圈吧!


点个在看 paper不断!















 3621
3621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









