






转:http://news.hexun.com/2018-04-22/192880330.html
注:台湾话
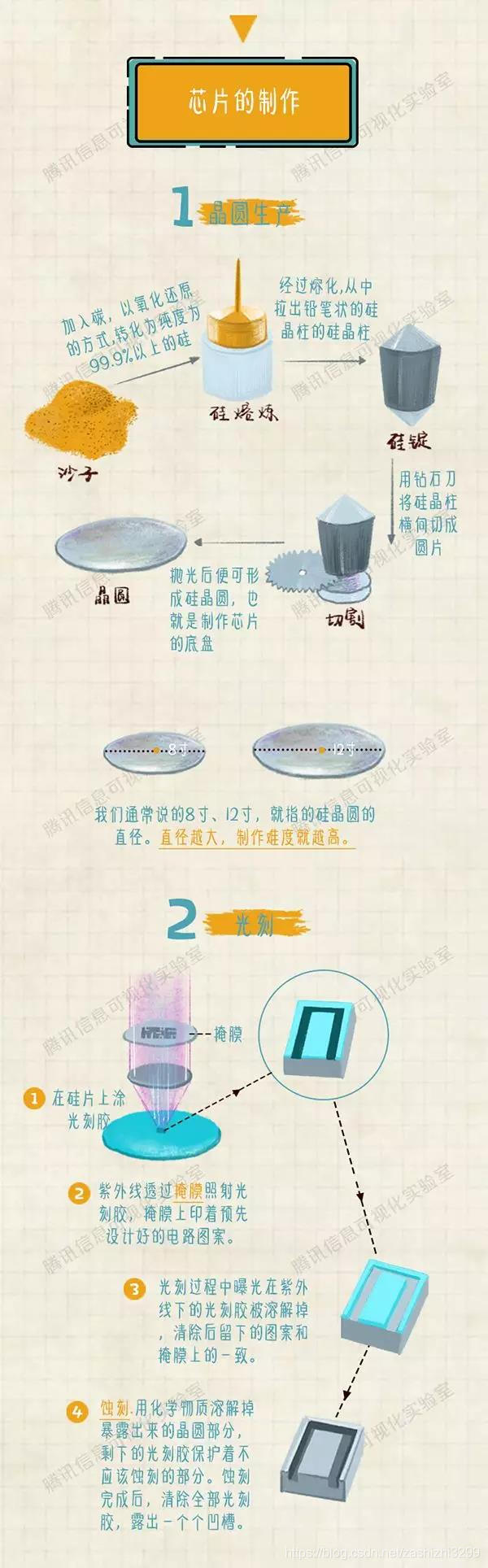
在开始前,我们要先认识 IC 芯片是什么。IC,全名积体电路(Integrated Circuit),由它的命名可知它是将设计好的电路,以堆叠的方式组合起来。藉由这个方法,我们可以减少连接电路时所需耗费的面积。下图为 IC 电路的 3D 图?????从图中可以看出它的结构就像房子的樑和柱,一层一层堆叠,这也就是为何会将 IC 制造比拟成盖房子。

从上图中 IC 芯片的 3D 剖面图来看,底部深蓝色的部分就是晶圆,从这张图可以更明确的知道,晶圆基板在芯片中扮演的角色是何等重要。至于红色以及土黄色的部分,则是于 IC 制作时要完成的地方。
知道 IC 的构造后,接下来要介绍该如何制作。试想一下,如果要以油漆喷罐做精细作图时,我们需先割出图形的遮盖板,盖在纸上。接着再将油漆均匀地喷在纸上,待油漆乾后,再将遮板拿开。不断的重复这个步骤后,便可完成整齐且复杂的图形。制造 IC 就是以类似的方式,藉由遮盖的方式一层一层的堆叠起来。
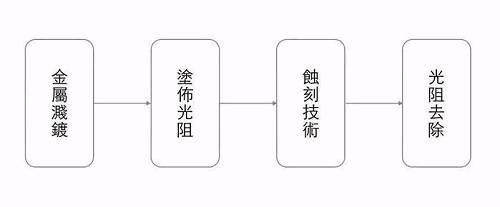
金属溅镀:将欲使用的金属材料均匀洒在晶圆片上,形成一薄膜。
涂布光阻:先将光阻材料放在晶圆片上,透过光罩(光罩原理留待下次说明),将光束打在不要的部分上,破坏光阻材料结构。接着,再以化学药剂将被破坏的材料洗去。
蚀刻技术:将没有受光阻保护的硅晶圆,以离子束蚀刻。
光阻去除:使用去光阻液皆剩下的光阻溶解掉,如此便完成一次流程。
最后便会在一整片晶圆上完成很多 IC 芯片,接下来只要将完成的方形 IC 芯片剪下,便可送到封装厂做封装(DIP、BGA)。
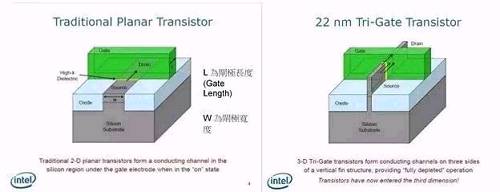
14纳米芯片概念,纳米制程是指在芯片中,线???最小可以做到 14 纳米的尺寸,下图为传统电晶体的长相,以此作为例子。缩小电晶体的最主要目的就是为了要减少耗电量,然而要缩小哪个部分才能达到这个目的?左下图中的 L 就是我们期望缩小的部分。藉由缩小闸极长度,电流可以用更短的路径从 Drain 端到 Source 端(有兴趣的话可以利用 Google 以 MOSFET 搜寻,会有更详细的解释)。
不过,制程并不能无限制的缩小,当我们将电晶体缩小到 20 纳米左右时,就会遇到量子物理中的问题,让电晶体有漏电的现象,抵销缩小 L 时获得的效益。作为改善方式,就是导入 FinFET(Tri-Gate)这个概念,如右上图。在 Intel 以前所做的解释中,可以知道藉由导入这个技术,能减少因物理现象所导致的漏电现象。
更重要的是,藉由这个方法可以增加 Gate 端和下层的接触面积。在传统的做法中(左上图),接触面只有一个平面,但是采用 FinFET(Tri-Gate)这个技术后,接触面将变成立体,可以轻易的增加接触面积,这样就可以在保持一样的接触面积下让 Source-Drain 端变得更小,对缩小尺寸有相当大的帮助。
为什么会有人说各大厂进入 10 纳米制程将面临相当严峻的挑战,主因是 1 颗原子的大小大约为 0.1 纳米,在 10 纳米的情况下,一条线只有不到 100 颗原子,在制作上相当困难,而且只要有一个原子的缺陷,像是在制作过程中有原子掉出或是有杂质,就会产生不知名的现象,影响产品的良率。
目前常见的封装有两种,一种黑色长得像蜈蚣的 DIP 封装,另一为购买盒装 CPU 时常见的 BGA 封装。
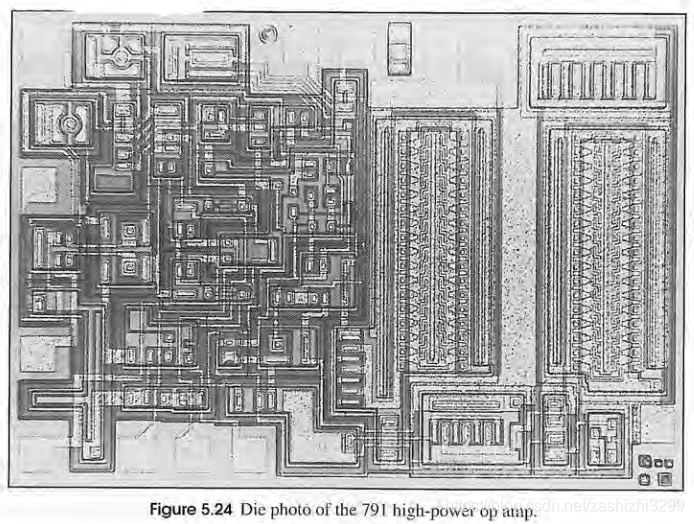
首先要介绍的是双排直立式封装(Dual Inline Package;DIP),从下图可以看到采用此封装的 IC 芯片在双排接脚下,看起来会像条黑色蜈蚣,让人印象深刻,此封装法为最早采用的 IC 封装技术,具有成本低廉的优势,适合小型且不需接太多线的芯片。但是,因为大多采用的是塑料,散热效果较差,无法满足现行高速芯片的要求。因此使用此封装的大多是历久不衰的芯片,如下图中的电压放大器OP741及其冲模照片,或是对运作速度没那么要求且芯片较小、接孔较少的 IC 芯片。
|
|

球格阵列(Ball Grid Array,BGA)封装,和 DIP 相比封装体积较小,可轻易的放入体积较小的装置中。此外,因为接脚位在芯片下方,和 DIP 相比,可容纳更多的金属接脚。适合需要较多接点的芯片。然而,采用这种封装法成本较高且连接的方法较复杂,因此大多用在高单价的产品上。
|
|

然而,如果各个元件都独立封装,组合起来将耗费非常大的空间,因此目前有两种方法,可满足缩小体积的要求,分别为 SoC(System On Chip)以及 SiP(System In Packet)。
在智慧型手机刚兴起时SoC 这个名词,就是将不同 IC整合在一颗芯片中。不单可以缩小体积,还可以缩小 IC 间的距离,提升芯片的计算速度。至于制作方法,便是在 IC 设计阶段时,将各个不同的 IC 放在一起,制作成一张光罩。
然而信号干扰,像是通讯芯片的高频讯号可能会影响其他功能的 IC 等情形。
此外,SoC 还需要获得其他厂商的 IP(intellectual property)授权,增加了 SoC 的设计成本。
折衷方案,SiP 现身
作为替代方案,SiP 跃上整合芯片的舞台。和 SoC 不同,它是购买各家的 IC,在最后一次封装这些 IC,如此便少了 IP 授权这一步,大幅减少设计成本。此外,因为它们是各自独立的 IC,彼此的干扰程度大幅下降??????举例:apple watch


【60FPS】 60帧的Intel芯片制作过程!!!_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
https://www.bilibili.com/video/av19382074/?spm_id_from=333.788.videocard.12




显微镜下的集成电路,人类工艺的巅峰!_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
https://www.bilibili.com/video/av12652893/?spm_id_from=333.788.videocard.6
级别:1微米(1000纳米)



单片机
https://www.bilibili.com/video/av7515293/?spm_id_from=333.788.videocard.12
显微镜下的CD光盘 [2000倍]
https://www.bilibili.com/video/av34555351/?spm_id_from=333.788.videocard.4
数量级:???





电脑科技: 电脑CPU芯片放大14万倍后,内部构造复杂到不可思议!_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili https://www.bilibili.com/video/av22251521/?spm_id_from=333.788.videocard.2
机械硬盘,不管多大,结构都差不多。
《硬盘三连拆》第三章:昆腾大脚机械硬盘_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili https://www.bilibili.com/video/av55809051

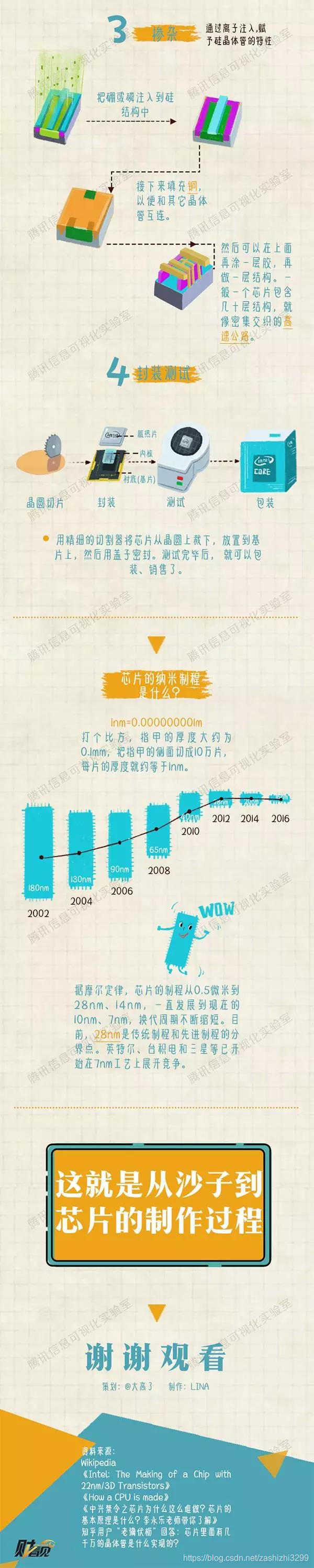
芯片的制程
原文链接:https://blog.csdn.net/chauncey_wu/article/details/81352706
此文以MOS管为例。
1 CMOS管的基本构造
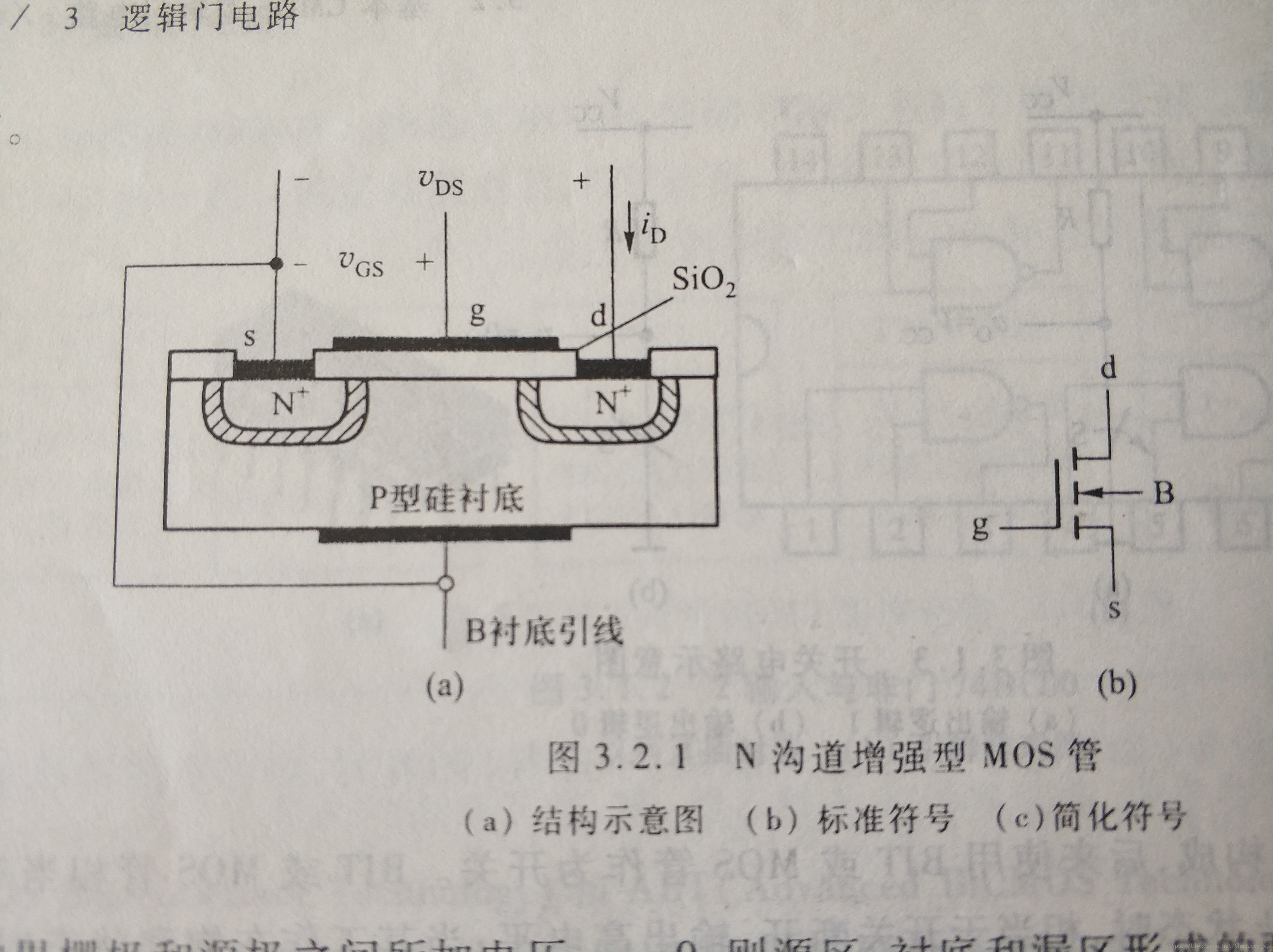
N沟道增强型MOS管的结构示意见上图。它是在P型衬底上,用扩散法制作两个高掺杂度的N区。然后在P型硅表面生长一层很薄的二氧化硅绝缘层,并在二氧化硅表面及两个N型区各安置一个电极,形成栅极g,源级s和漏级d。
2 晶体管栅极g是什么作用?
晶体管栅极是晶体管的控制端。晶体管(这里只考虑MOSFET,不考虑BJT啥的)有四个电极:栅、源、漏、衬底。其中衬底电压一般是固定的,也不会有电流流入,可以忽略。栅极是控制极,栅极和源极之间的的电压差,控制了漏极和源极之间的电流大小。(就是个跨导啦)简单地说栅极就是一个开关,当Vgs为高时导通(简称高导)。
3 xx制程的含义
晶体管结构中,电流从Source(源极)流入Drain(漏级),Gate(栅极)相当于闸门,主要负责控制两端源极和漏级的通断。电流会损耗,而栅极的宽度则决定了电流通过时的损耗,表现出来就是手机常见的发热和功耗,宽度越窄,功耗越低。而栅极的最小宽度(栅长),就是XX nm工艺中的数值。对于芯片制造商而言,主要就要不断升级技术,力求栅极宽度越窄越好。不过当宽度逼近20nm时,栅极对电流控制能力急剧下降,会出现“电流泄露”问题。为了在CPU上集成更多的晶体管,二氧化硅绝缘层会变得更薄,容易导致电流泄漏。一方面,电流泄露将直接增加芯片的功耗,为晶体管带来额外的发热量;另一方面,电流泄露导致电路错误,信号模糊。为了解决信号模糊问题,芯片又不得不提高核心电压,功耗增加,陷入死循环。因而,漏电率如果不能降低,CPU整体性能和功耗控制将十分不理想。
【转】160亿晶体管!苹果首款Mac处理器M1
ROB(reorder buffer)630项,比Intel的大一倍多。通俗一点来说ROB大小就是指令窗口大小,CPU可以从630条指令里面找出能乱序执行的指令去发射,这极大地提高了指令的并行度。
现在CPU架构设计越来越简单粗暴了,全靠工艺来堆,架构设计师就拼命堆晶体管就行了。
苹果完全延续了Intel 酷睿以来的设计思路:更大的Cache、更大的数据位宽、更大的指令窗口,就能带来更高的性能。而这一切,跟你的设计能力无关,只要晶体管够多、够快、够低功耗。
也不能说完全跟设计能力无关,如果分支预测器准确率上不去,再大的指令窗口也白搭。这至少说明苹果的分支预测器是过硬的。
2020.11苹果推出了搭载了苹果自研Arm桌面处理器的全新的MacBook系列。
得益于公司在硬件和软件之间的垂直集成,这是一个巨大的变化,只有苹果公司才能如此迅速地迎来变革。上一次苹果公司在2006年放弃了IBM的PowerPC ISA和处理器,转而支持英特尔x86设计。今天,英特尔已经放弃了基于ARM ISA构建的公司自己的内部处理器和CPU微体系结构。如今,英特尔被抛弃,转而采用建立在ARM ISA的基础上的该公司自己的内部处理器和CPU微架构。
新处理器称为Apple M1,这是该公司针对Mac的第一个SoC设计。它具有四个高性能大核,四个高效能的小核和一个8-GPU内核GPU。在新的5nm工艺节点上集成了160亿个晶体管。苹果公司正在为此新系列处理器启动新的SoC命名方案,但至少在纸面上看起来确实像A14X。
Apple M1 SoC:适用于Mac的A14X
新款Apple M1确实是Apple进行新的重大旅程的开始。在苹果公司的演示中,该公司并没有透露太多设计细节,但是有一张PPT告诉了我们很多有关芯片的封装和设计的信息:
这种将DRAM嵌入到有机封装中的封装风格对于新的M1芯片来说并不新鲜,因为我们已经在A12X上看到了这样的设计。之所以没有采用更通用的智能手机POP封装,是因为这些芯片在设计时考虑了更高的TDP,并确保在新设计中可以更有效散热。
这很可能意味着,我们还将在新芯片上看到一个128位的DRAM总线,与上一代A-X芯片的总线非常相似。
在苹果提供的PPT上,看到了实际裸片(die)的照片。它与苹果描述的芯片特性完全吻合,看起来就像一张真实的裸片照片。我们划分了各个主要的功能块: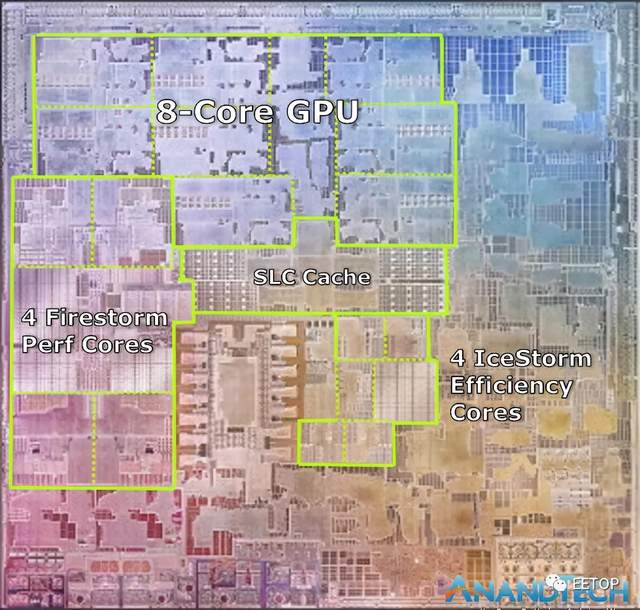
可以在左侧看到M1的四个新的高性能Firestorm CPU内核。可以看到采用了大量的缓存,因为而在A14仍仅具有8MB的L2缓存。这里的新缓存看起来可以分成3个更大的块,这对于考虑到Apple在此新配置中从8MB过渡到12MB来说是有道理的,毕竟这是由4核而不是2核。
4个Icestorm高效能核心位于SoC的中心,我们发现SoC的系统级缓存在所有IP块之间共享。
8核GPU占用了大量的裸片空间,位于该裸片的上部。
M1最有趣的地方是它与Intel和AMD的其他CPU设计相比。苹果公司提到M1是真正的SoC,上述所有模块仅覆盖整个芯片的一部分,其他部分集成了大量的辅助IP。其中包括以前Mac笔记本电脑中几个分立芯片的功能。
苹果声称新的CPU内核是世界上最快的。在我们深入探讨Firestorm内核的微体系结构以及为您提供Apple A14 SoC的性能数据时,这将是今天文章的重点。
我们期望M1内核比我们今天将要展示的A14更快,因此苹果声称拥有世界上最快的CPU内核的说法似乎是非常合理的。
整个SoC集成了庞大的160亿个晶体管,比最新iPhone中的A14高35%。如果苹果公司将两块芯片之间的晶体管密度保持在相似水平,那么我们应该算出的芯片尺寸约为120平方毫米,这比Macbooks内部的上一代英特尔芯片要小得多。
苹果的巨型CPU微体系结构
那么苹果打算如何在这个市场上与AMD和Intel竞争呢?过去几年来一直在关注苹果在硅技术方面的努力的读者一定不会惊讶地看到苹果在活动中宣称的性能。
秘密之处在于苹果公司内部的CPU微体系结构。苹果进入定制CPU微体系结构的漫长旅程始于2012年在iPhone 5中发布的Apple A6。甚至早在第一代“ Swift”设计时,与移动竞争对手相比,该公司就已经取得了令人印象深刻的性能数据。
然而真正让业界震惊的是苹果随后在2013年的苹果A7 SoC和iPhone 5S中发布的CycloneCPU微架构。苹果很早就采用了64位Armv8 ISA,这让所有人都感到震惊,因为该公司是业界第一个实现新指令集架构的公司,但他们甚至比Arm自己的CPU团队快了一年多的时间,因为Cortex-A57(Arm自己的64位微架构设计)要到2014年年底才能见到曙光。
苹果公司将其“ Cyclone”设计称为“桌面级架构”,在事后看来,它可能应该明显地指向公司的发展方向。在随后的几代人中,苹果公司以惊人的速度发展了他们的定制CPU微体系结构,每一代人都获得了巨大的性能提升。
今年的A14芯片包括了苹果64位微架构家族中的第8代产品,而这个家族曾以A7和Cyclone设计为开端。这些年来,苹果的设计节奏似乎已经稳定下来,从A7芯片组开始,围绕着主要的两代微架构更新,A9、A11、A13都展现了其设计复杂度和微架构宽度和深度的大幅提升。
鉴于苹果公司并没有披露任何细节,苹果的CPU仍然几乎是一个黑箱设计,唯一公开的关于此事的资源可以追溯到A7 Cyclone时代的LLVM补丁,这些补丁与今天的设计已经非常不相关。虽然我们没有官方的手段和信息来了解苹果CPU的工作原理,但这并不意味着我们无法弄清楚某些方面的设计。通过我们自己的内部测试以及第三方微基准(特别感谢@Veedrac的microarchitecturometer测试套件),我们却可以揭开苹果设计的一些细节。以下披露的内容是基于测试iPhone 12 Pro内部最新的苹果A14 SoC的行为而估算出来的。
苹果的Firestorm CPU核心:更大更宽
苹果最新一代A14内部的大核心CPU设计代号为“Firestorm”,延续了去年苹果A13内部的“Lightning”微架构。今天讨论的核心是新的Firestorm核心和它多年来不断改进的血统,这也是苹果如何从英特尔x86设计大幅跳跃到他们自己内部的SoC的关键部分。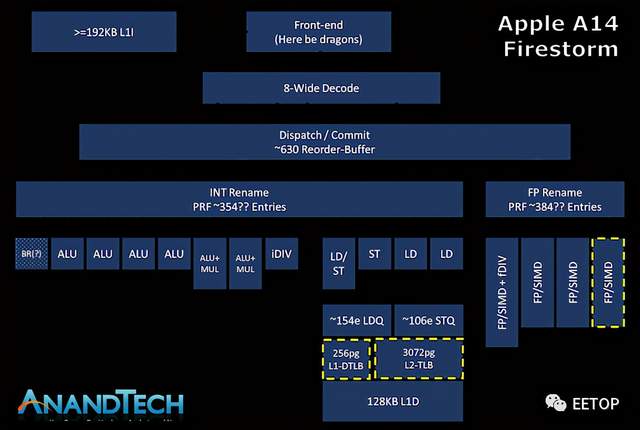
上图是苹果最新的大核设计的估计功能布局--这里所代表的是我们在确定新设计功能方面的最大努力尝试,但肯定不是对苹果设计的所有功能的详尽钻研--所以自然可能存在一些不准确的地方。
真正将苹果Firestorm CPU核心与业界其他设计区分开来的,只是微架构的宽度。苹果的Firestorm拥有8个宽度的解码块,是目前业界最宽的商业化设计。IBM即将在POWER10中推出的P10内核是唯一一个有望在市场上发布的具有如此宽解码器设计的官方设计,此前三星取消了自家的M6核心,而M6核心也被称为采用相同宽度的设计。
当代的其他设计,如AMD的Zen(1到3)和Intel的μarch的,x86的CPU如今仍然只采用4宽的解码器设计,由于ISA固有的指令长度可变的特性,相比ARM ISA的固定长度指令,设计能够处理架构方面的解码器更加困难,因此目前似乎还限制了它的宽度。在ARM方面,三星的设计从M3开始一直是6宽,而Arm自己的Cortex内核每一代都在稳步变宽,目前现有的硅片中是4宽,预计在即将到来的Cortex-X1内核中会增加到5宽设计。
苹果最近的设计中,有一个我们从未真正能够具体回答的问题是,苹果的乱序执行能力有多强。Firestorm的ROB在630指令范围内,这是去年A13闪电核心的升级,它在560指令范围内测量。目前还不清楚这是否与其他架构中的传统ROB相同,但测试至少暴露了与ROB相关的微架构限制,并暴露了行业中其他设计的正确数据。乱序窗口是指当内核试图获取并执行每条指令的依赖关系时,内核可以“停放”的、等待执行的指令数量。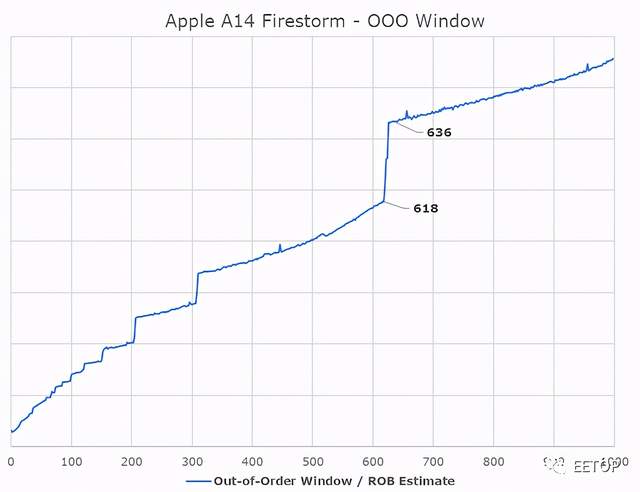
对于苹果的新核心来说,+-630深的ROB是一个极其巨大的乱序窗口,因为它远远超过了业界的任何其他设计。英特尔的Sunny Cove和Willow Cove核心以352条ROB结构成为目前 "深度 "第二高的OOO设计,而AMD最新的Zen3核心则以256条,最近的Arm设计如Cortex-X1则采用224条结构。
究竟苹果是如何以及为什么能够实现与业界其他所有设计者相比如此严重不成比例的设计,目前还不完全清楚,但这似乎是苹果实现高ILP(指令级并行)的设计理念和方法的一个重要特征。
移动处理器性能对比
在我们深入探讨x86与AppleSilicon的争论之前,不妨先详细了解一下A14 Firestorm核心在A13 Lightning核心的基础上有怎样的改进,并详细介绍一下新芯片5nm工艺节点的功耗和能效提升。
在这里的对比中,工艺节点其实是相当的悬殊,因为A14是市场上第一款5nm芯片组,紧随其后的是华为Mate 40系列的麒麟9000。我们正好有两款设备和芯片在内部进行测试,对比麒麟9000(N5上的Cortex-A773.13GHz)与骁龙865+(N7P上的Cortex-A773.09GHz),我们可以一定程度上推断出工艺节点在功耗和效率上的影响有多大,将这些改进转化为A13与A14的对比。
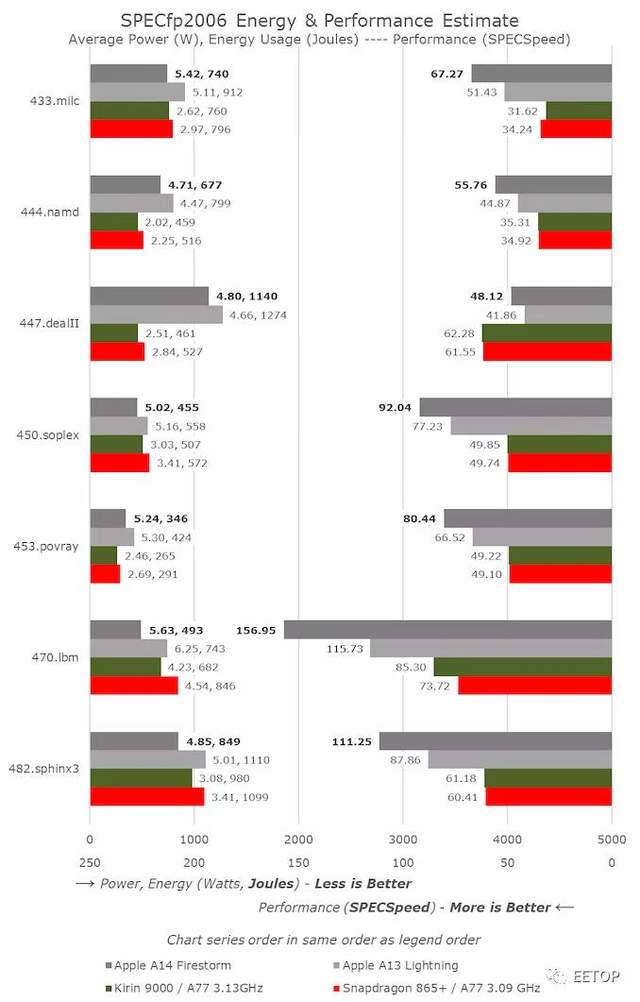
从SPECint2006开始,除了456.hmmer的巨大进步外,我们并没有看到A14的成绩有什么非常异常的地方。其实,这并不是因为微架构的跳跃,而是由于Xcode12中新的LLVM版本的新优化。这里看来,编译器采用了类似于GCC8上的循环优化。A13的得分实际上已经从47.79提高到64.87,但我还没有在整个套件上运行新的数据。
对于其余的工作负载,A14通常看起来像是A13相对线性的演进,这说明时钟频率从2.66GHz增长到3GHz。该套件的总体IPC增益约为5%,虽然比通常的时钟速度提高得大,但比Apple的前几代要少一些。
新芯片的功耗实际上是一致的,有时甚至比A13更好,这意味着即使在最高性能点,这一代的工作负载能效也得到了显着改善。
与Android和Cortex核心的SoC相比,性能似乎更偏向于苹果。最突出的一点是具有内存密集型,稀疏内存特征的工作负载,例如429.mcf和471.omnetpp,尽管所有芯片都在运行类似的移动级LPDDR4X/LPDDR5,但Apple设计的性能却要高出两倍以上。在我们的微架构调查中,我们看到了苹果设计中“memorymagic”的迹象,我们可能认为他们使用了某种指针追逐预抓取机制。
在SPECfp中,A14比A13的增幅比线性时钟频率的增幅要高一些,因为我们在这里测量的是10-11%的整体IPC提升。考虑到该设计多了第四条FP/SIMD流水线,这并不太令人意外,而与A13相比,该核心的整数方面相对没有变化。
在整体的移动对比中,我们可以看到,新的A14在性能提升方面比A13取得了强劲的进步。与竞争对手相比,苹果已经遥遥领先--我们必须等待明年的Cortex-X1设备才能看到差距再次缩小。
这里还需要注意的是,苹果在取得这些成绩的同时,还保持了新芯片的功耗持平,甚至降低了功耗,尤其是降低了相同工作负载的能耗。
从麒麟9000与骁龙865+的对比来看,我们看到在性能相对相似的情况下,功耗降低了10%。两款芯片使用的是相同的CPU IP,只是在工艺节点和实现方式上有所不同。看来苹果这里的A14能够取得更好的数据,不仅仅是工艺节点的提升,鉴于它也是全新的微架
还有一个值得注意的是A14的小效率核心的对比数据。这一代我们看到这些新核心在微架构上有很大的提升,相比去年的A13效率核心,现在的性能提升了35%--同时进一步降低了能耗。我不知道这些小核心在苹果的 Apple Silicon Mac设计上会有怎样的表现,但相比于其他Arm设计,它们的性能肯定还是很强的,而且效率极高。
与x86对比:轻松击败英特尔i7处理器
迄今为止,我们对Apple芯片组的性能比较一直是在iPhone评测的背景下进行的。
我们目前还没有苹果硅设备,很可能再过几周才能拿到手,但我们有A14,并预计新的Mac芯片将强烈基于我们看到的iPhone设计中采用的微架构。当然,我们仍然在比较手机芯片与高端笔记本电脑甚至高端台式机芯片。
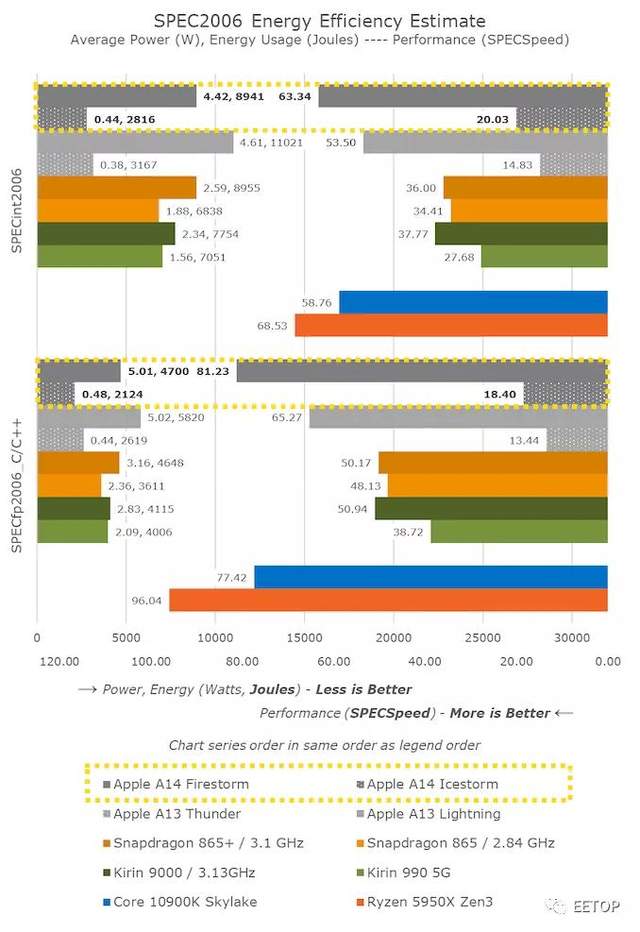
这张图上A14的性能数据比较让人难以置信。如果我在公布这些数据的同时隐藏了A14的标签,人们会猜测这些数据点来自于AMD或Intel的其他x86 SKU。事实上,A14目前能与目前市场上x86厂商最优秀的顶级性能设计相抗衡,实在是一个惊人的壮举。
再来看看详细的成绩,再次让我们惊讶的是,A14不仅能跟上,而且在429.mcf和471.omnetpp等对内存延迟敏感的工作负载上,A14居然比这两个竞争对手都要强,尽管它们要么拥有相同的内存(i7-1185G7,LPDDR4X-4266),要么拥有桌面级内存(5950X,DDR-3200)。
同样,不考虑A14的456.hmmer分数优势,那主要是由于编译器差异造成的,减去33%,对比数据更贴切。
即使在SPECfp中,内存负担更多的工作量甚至占主导地位,A14不仅跟得上,而且通常比Intel CPU设计更胜一筹。如果没有最新发布的Zen3设计,AMD也比不过A14。
在总体SPEC2006图表中,A14表现绝对出色,在绝对性能上领先,只是低于AMD最近的Ryzen5000系列。
事实上,苹果能够在一个包括SoC、DRAM和电源管理在内的设备总功耗为5W的情况下实现这一点,这绝对是令人震惊的。
对于GeekBench等比较常见的基准套件有很多批评,但坦率地说,我发现这些担心或争论是很没有根据的。SPEC中的工作负载和GB5中的工作负载唯一的事实区别是,后者的异常值测试较少,而这些测试都是重内存的,也就是说它更多的是CPU基准,而SPEC则更倾向于CPU+DRAM。
苹果公司在两种工作负载中均表现出色,这证明它们具有极其平衡的微体系结构,并且将能够在性能方面扩展至“桌面工作负载”而不会出现太大问题。
不要忘了GPU
今天我们主要介绍了CPU方面的内容。然而,我们不应该忘记GPU,因为新的M1代表着苹果首次将他们的定制设计引入Mac领域。
我们知道的是,在移动领域,苹果在性能和能效方面是绝对领先的。上一次我们测试A12Z的时候,该设计就足以与集成显卡设计相抗衡。但从那以后,我们看到AMD和英特尔都有了更显著的提升。
性能将保持领先?
苹果声称M1是世界上最快的CPU。鉴于我们在A14上获得的数据,击败了英特尔的设计,并且仅落后于AMD最新的Zen3芯片-更高的主频超过3GHz的Firestorm,更大的L2缓存和释放的TDP,我们可以肯定地说,只有苹果M1才能实现这一要求。
英特尔已陷入停滞,并失去了今天的主要客户。AMD最近展示了许多进步,但是要赶上Apple的能效将非常困难。如果Apple的性能轨迹以这种速度继续下去,则x86的性能王冠将永远无法夺回。
参考文献
1、模电,Paul R. Gray - Analysis and Design of Analog Integrated Circuits, 5th edition (2009, John Wiley & Sons Inc)
2、模电,Allen P.E., Holberg D.R. - CMOS Analog Circuit Design
3、https://mp.weixin.qq.com/s/4pM6kaTojr-x97jczRsGHA
4、【转载】芯片级拆解51、AVR、MSP430、凌阳61、PIC,5种单片机,多张显微照片 - 编程浪子_ - 博客园 https://www.cnblogs.com/zyqgold/p/3296277.html
5、《计算机体系结构—量化研究方法(第5版)》
6、芯片制造22nm制程是什么含义 - Chauncey_wu的博客 - CSDN博客 https://blog.csdn.net/chauncey_wu/article/details/81352706
7、160亿晶体管!苹果首款Mac处理器之我见 https://m.newsmth.net/article/CSArch/62535

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









