







XingGAN for Person Image Generation(人体姿势生成笔记)
1.概述
XingGAN中的生成器由两个代分支组成,分别对人的外观和形状信息进行建模。此外,我们提出了两个新的块,以交叉的方式有效地传递和更新人的形状和外观嵌入,从而相互改进。
数据集:Market 1501 ,DeepFashion
2.介绍
基于论文:Progressive Pose Attention Transfer for Person Image Generation
实现目标:输入一个人物图像和几个理想姿势生成具有真实感的人物图像。
存在的问题:由于某些原因,在生成的人物图像中存在不令人满意的方面和视觉伪影。
- 1.堆叠几个卷积层生成形状特征的注意图,然后利用生成的注意图集中突出外观特征。卷积操作是一次处理一个局部邻域的构建块,因此不能捕捉外观和形状特征之间的联合影响。
- 2.论文中的注意力地图仅通过单一的模态产生,例如:姿势,导致对两种模态(姿势和图像)的相关性不够准确,从而误导图像的生成。
XingGAN的简要介绍:

- GAN组成部分:Xing生成器,形状引导鉴别器,外观引导鉴别器。
- Xing生成器的组成部分:基于外观的姿势引导生成器分支(SA),基于姿势的外观引导生成器分支(AS),共同注意力融合模块(CAF)。如上图所示。
3.相关工作(具体实现)
输入参数:源图片(Is),源姿势(Ps),目标姿势(Pt)
目标:源图片(Is),转移目标姿势(Pt)合成为一个图片(It’)
3.1SA分支:

- 组成:一个图像编码器和一系列的SA块。
- 操作:将源图像Is第一次注入到图像编码器中产生外观编码F0I,该编码器在该实验中包含两层卷积层。SA分支中包含一些级联的SA块,这些块主要在AS分支的引导下渐进式地更新初始的外观编码到最后的外观编码FTI。每一个SA块有一个确定的网络结构。上图为第t块,输入为:维度为chw的外观编码Ft-1I和形状编码Ft-1P,输出为:维度为chw的外观编码FtI。
- 具体的解释:提供维度为chw的外观编码Ft-1I,首先将其注入到一个卷积层去产生一个新的维度为chw的外观编码C.然后将C重塑成维度为c*(hw)的外观编码。同时将SA块接收到的维度为chw的形状编码Ft-1P注入到卷积层产生一个新的维度为chw的形状编码B,并重塑成维度为c*(hw)的形状编码。在这之后,将对C的转置和B进行矩阵的相乘运算并应用一个Softmax层产生一个维度为(hw)(hw)的关联矩阵P。对于矩阵中的pij的计算如下式:
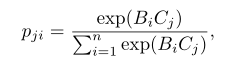
注:此式中的pij用于衡量B中第i个位置在外观编码C的j位置的的影响。
随后我们将Ft-1I注入到卷积层产生一个新的维度为chw的外观编码A并将其重塑成维度为c(hw)。然后将其与P的转置进行矩阵乘法运算并对结果重塑使得维度为chw。最后将该结果与一个尺度参数进行乘积操作并与Ft-1I执行元素方式的求和操作,得到精炼后的维度为chw的外观编码FtI,公式如下:
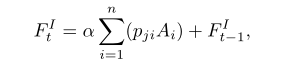
注:式中的α初始为0,逐渐提升。
3.2AS分支:

- 组成:一个图像编码器和一系列的AS块。
- 操作:源姿势Ps和目标姿势Pt首先在通道维度进行连接,然后注入到姿势编码器中产生一个初始的形状代表F0P。姿势编码器和图像编码器具有相同的网络结构。如上图所示,输入为:维度为chw的形状编码Ft-1P和外观编码Ft-1I,输出为:维度为chw的形状编码FtP。
- 具体的解释:首先将提供形状编码Ft-1P注入到一个卷积层以产生一个新的形状编码H,然后重塑为维度为c*(hw)。同时,将AS块接收到的外观编码Ft-1I注入到一个卷积层以产生一个新的外观编码E,然后重塑成为维度为c*(hw)。随后,执行H的转置与E的矩阵乘积操作并应用一个Softmax层以产生另一个关联矩阵Q,qji的计算公式如下:
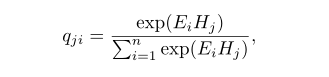
注:qji用来衡量E的第i个位置在H的第j个位置上的影响。
与此同时,将Ft-1P注入到一个卷积层以产生一个新的形状编码D并重塑成维度为c*(hw),然后进行D与Q的转置的矩阵乘法运算并将结果重塑到维度为chw,最后将该结果与一个尺度参数β进行乘积操作并与Ft-1P执行元素方式的求和操作,再与外观编码FtI进行通道方式的连接操作并将结果注入到一个卷积层以获得更新后的形状编码FtP,公式如下:
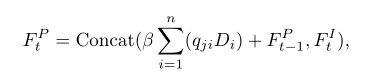
注:β是一个参数,Concat代表进行通道方式的连接操作。
3.3 CAF
组成部分:产生中间结果和共同注意力地图
共同注意映射(co-attention map):用于从中间的产生和输入图像进行空间地选择并结合生成最后的输出。
操作:首先首先将FTI和FTP信道轴叠加,然后将它们输入一组滤波器{WAi, bAi}i=12N+1 中,生成相应的2N+1共同注意映射,如下图所示:
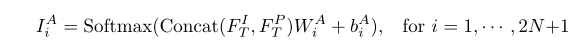
注:Softmax是一个通道方式Softmax方法用来进行归一化操作
最后共同注意映射从每一个中间的产生和输入图像中进行通道方式选择:
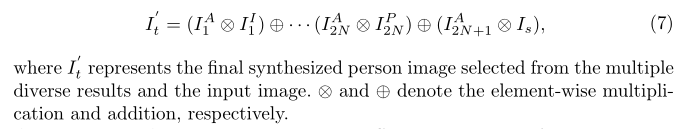
产生中间结果:分别于最终的外观编码和形状编码解码生成,并且有一个Tanh激活函数如下图所示:
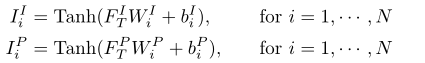
3.4 优化目标
主要有三种损失进行优化:对抗损失Lgan,像素损失Ll1,感知损失Lp。
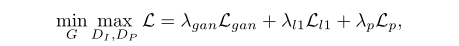















 5205
5205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









