







最近在Spark程序运行的过程中发现了一个问题,系统每天会运行很多任务,任务计算逻辑是一样的,但是每个任务拉去的数据量有多有少,不知道怎么给Spark程序设置多少资源比较合理。这时候Spark的动态Executor分配机制就派上用场了,它会根据当前任务运行的情况自动调整Executor的数量,实现资源的弹性分配。
Spark的动态Executor分配机制介绍:
//开启Dynamic Resource Allocation
spark.dynamicAllocation.enabled=true;
//在每个nodeManager上设置外部shuffle服务,避免Executor被移除时Shuffel数据找不到。同时Yarn上还要进行其他配置,见参考中的链接
spark.shuffle.service.enabled=true;
//最少的Excutor数目
spark.dynamicAllocation.minExecutors;
//最大Executro数目
spark.dynamicAllocation.maxExecutors;
//初始Executor数目(看下文分析)
spark.dynamicAllocation.initialExecutors ;
//任务队列非空,资源不够,申请executor的时间间隔,默认1s
spark.dynamicAllocation.schedulerBacklogTimeout;
//申请了新一批executor之后继续申请下一批的间隔,默认等于schedulerBacklogTimeout
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout;
//Executor如果一段时间没有任务执行就会被回收,默认60s(个人觉得应该设置大一点)
spark.dynamicAllocation.executorIdleTimeout
// 当某个缓存数据的executor空闲时间超过这个设定值,就会被kill,默认Integer.MAX_VALUE,所以可以认为Executor cache了数据,就不会被Kill
spark.dynamicAllocation.cachedExecutorIdleTimeout
注意启用动态Executor之后,最初的Executor的个数其实不仅仅是由initialExecutors 参数决定的:
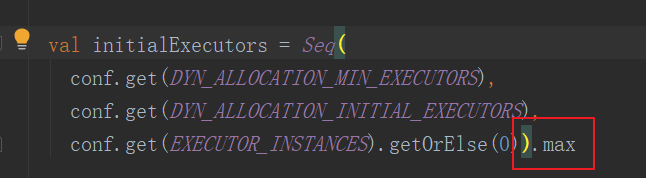
动态Executor分配机制的代码都在ExecutorAllocationManager类里面,但是看了上面这些参数之后,感觉已经解释的很清楚了,所以就不去特别分析下源码了。
个人的一些想法:
- 根据数据量设置合理的minExecutors和maxExecutors值
- spark.executor.cores,即一个Executor所拥有的cpu core默认为1,建议设置的多一点(比如3;Executor的内存也不要设置太大,5G-10G左右吧),不然没任务Executor就被移除了,后续又要申请资源。
- 对于每个Stage持续时间很短的应用,其实不适合这套机制。因为SubmitStage会涉及到资源调整,这样可能会频繁增加和杀掉Executors,造成系统颠簸,而Yarn对资源的申请处理速度并不快。建议把Executor的超时时间设置长一点
- 还有程序的并行数设置,建议最小是 初始Executor * 核数。
- 建议将Executor的超时时间(spark.dynamicAllocation.executorIdleTimeout)设置的长一点,比如300s。由于默认超时时间是60s,如果某些Task运行时间较长会导致Executor被回收然后又要重新申请Executor。个人测试了下,原先28min的任务,增加超时时间之后,只要20min便能运行完毕
参考:
http://spark.apache.org/docs/2.4.4/configuration.html#dynamic-allocation(官网介绍)
https://www.jianshu.com/p/f8b9d0ec49e5(动态资源申请是指数级增长的)
https://my.oschina.net/starqiu/blog/3187805(动态资源分配性能对比)
https://developer.aliyun.com/article/60211(Executor何时会被判断为空闲)

















 5829
5829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









