







最近有好几个朋友都有咨询这个问题,大概有两类:
1、为啥我用了with..as效率没有提高?
2、sql跑不动,改成with..as的写法,会不会更好些?
网上博客几乎都有结论with ... as语句会把数据放在内存:


hive-sql
在hive中有一个参数
hive.optimize.cte.materialize.threshold这个参数在默认情况下是-1(关闭的);当开启(大于0),比如设置为2,则如果with..as语句被引用2次及以上时,会把with..as语句生成的table物化,从而做到with..as语句只执行一次,来提高效率。
测试
explainwith atable as (SELECT id,source,channel FROM test )select source from atable WHERE channel = '直播'union ALLselect source from atable WHERE channel = '视频'
不设置该参数时,执行计划:
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: testStatistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEFilter Operatorpredicate: (channel = '直播') (type: boolean)Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONESelect Operatorexpressions: source (type: string)outputColumnNames: _col0Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEUnionStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeTableScanalias: testStatistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEFilter Operatorpredicate: (channel = '视频') (type: boolean)Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONESelect Operatorexpressions: source (type: string)outputColumnNames: _col0Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEUnionStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
从执行计划上看,test表被读两次,即有两个TableScan。
设置set hive.optimize.cte.materialize.threshold=1,执行计划:
STAGE DEPENDENCIES:Stage-1 is a root stageStage-6 depends on stages: Stage-1 , consists of Stage-3, Stage-2, Stage-4Stage-3Stage-0 depends on stages: Stage-3, Stage-2, Stage-5Stage-8 depends on stages: Stage-0Stage-2Stage-4Stage-5 depends on stages: Stage-4Stage-7 depends on stages: Stage-8STAGE PLANS:Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: testStatistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONESelect Operatorexpressions: id (type: int), source (type: string), channel (type: string)outputColumnNames: _col0, _col1, _col2Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEtable:input format: org.apache.hadoop.mapred.TextInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDename: default.atableStage: Stage-6Conditional OperatorStage: Stage-3Move Operatorfiles:hdfs directory: truedestination: hdfs://localhost:9000/tmp/hive/bytedance/bae441cb-0ef6-4e9c-9f7a-8a5f97d0e560/_tmp_space.db/ce44793b-6eed-4299-b737-f05c66b2281b/.hive-staging_hive_2021-03-24_20-17-38_169_5695913330535939856-1/-ext-10002Stage: Stage-0Move Operatorfiles:hdfs directory: truedestination: hdfs://localhost:9000/tmp/hive/bytedance/bae441cb-0ef6-4e9c-9f7a-8a5f97d0e560/_tmp_space.db/ce44793b-6eed-4299-b737-f05c66b2281bStage: Stage-8Map ReduceMap Operator Tree:TableScanalias: atableStatistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEFilter Operatorpredicate: (channel = '直播') (type: boolean)Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONESelect Operatorexpressions: source (type: string)outputColumnNames: _col0Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEUnionStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeTableScanalias: atableStatistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEFilter Operatorpredicate: (channel = '视频') (type: boolean)Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONESelect Operatorexpressions: source (type: string)outputColumnNames: _col0Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONEUnionStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 2 Data size: 0 Basic stats: PARTIAL Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-2Map ReduceMap Operator Tree:TableScanFile Output Operatorcompressed: falsetable:input format: org.apache.hadoop.mapred.TextInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDename: default.atableStage: Stage-4Map ReduceMap Operator Tree:TableScanFile Output Operatorcompressed: falsetable:input format: org.apache.hadoop.mapred.TextInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDename: default.atableStage: Stage-5Move Operatorfiles:hdfs directory: truedestination: hdfs://localhost:9000/tmp/hive/bytedance/bae441cb-0ef6-4e9c-9f7a-8a5f97d0e560/_tmp_space.db/ce44793b-6eed-4299-b737-f05c66b2281b/.hive-staging_hive_2021-03-24_20-17-38_169_5695913330535939856-1/-ext-10002Stage: Stage-7Fetch Operatorlimit: -1Processor Tree:ListSink
可以看到test表被物化了。
源码:
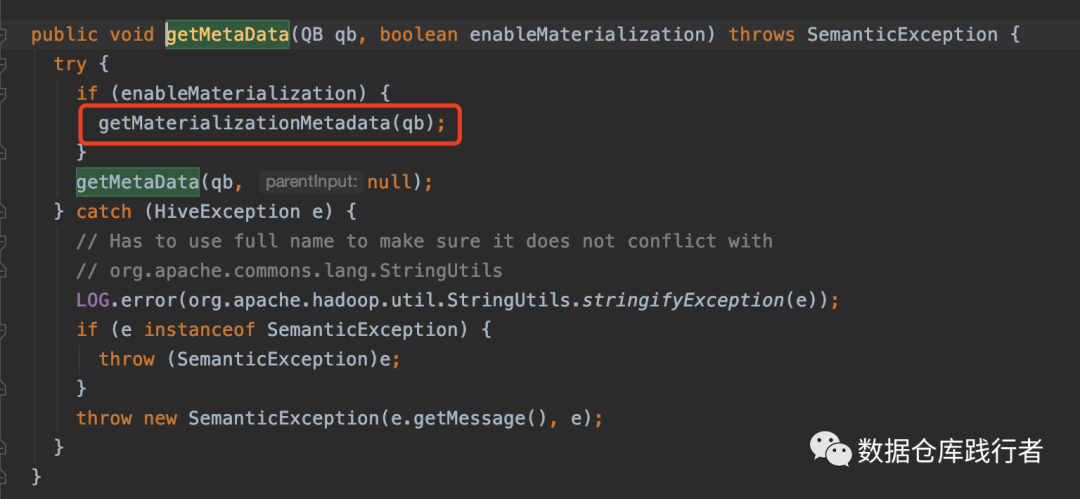
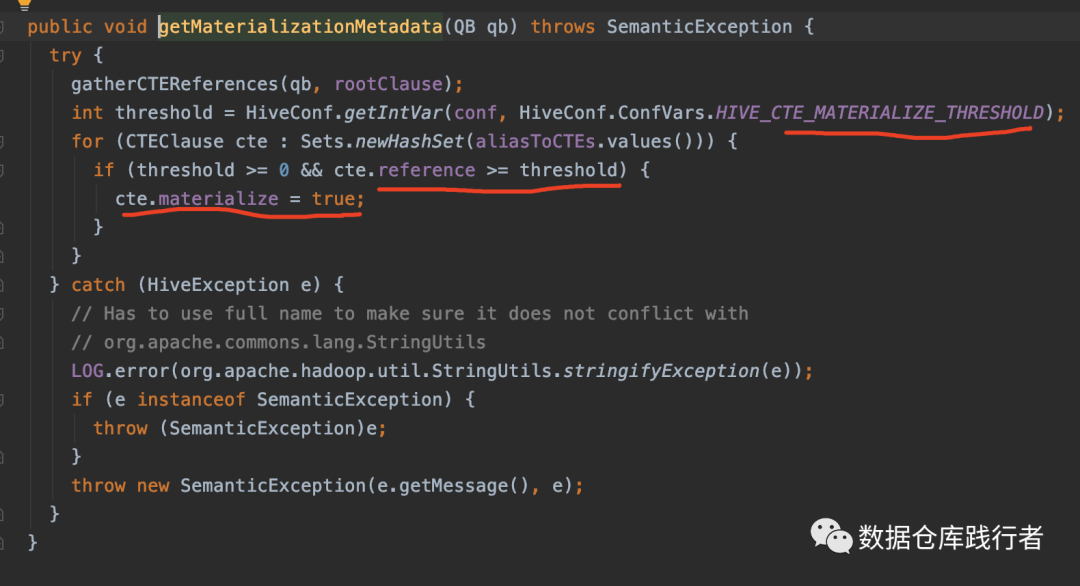
从源码看,在获取元数据时,会做参数判断,判断参数阈值及cte的引用次数
spark-sql
spark对cte的操作比较少,在spark侧,现在还没有相关的优化参数。
不过spark可以通过cache table的方式,将临时结果先缓存,然后对缓存的数据执行多次操作,















 3314
3314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









