







作业3是食品分类,可以在台大网站下载相关代码和PPT:ML 2022 Spring
参考了机器学习手艺人的李宏毅2022机器学习HW3解析_2022 hw3-CSDN博客和【深度解析→博文总结】李宏毅机器学习2023作业03CNN(Image Classification) - 知乎的解析,因为很多概念都没学过,有点无从下手,想着还是要自己动手才能学会,于是便一个个知识点去学习应用。
Data augmentation(数据增强):
数据增强就是通过对原图进行各种变换再做训练,相当于训练的样本增加了,从而提升模型的泛化能力。这也是HW3的问题1要解答的。
我加的都是Random的变换,因为每次获取训练数据的时候,都是把所有的变换操作都执行一遍的,如果不是随机变换,那原图就永远不会参与训练,只有转换以后的图片才会参与训练,那训练效果可能就不好了。
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((128, 128)),
# You may add some transforms here.
transforms.RandomResizedCrop(size=(128, 128), antialias=True),
transforms.RandomHorizontalFlip(p=0.5), #50%的概率水平翻转
transforms.RandomVerticalFlip(p=0.5), #50%的概率垂直翻转
transforms.RandomRotation(degrees=(0, 180)),
transforms.RandomAffine(degrees=(30, 70), translate=(0.1, 0.3), scale=(0.5, 0.75)),
transforms.RandomCrop(128, padding=10),
transforms.RandomGrayscale(p=0.1), #根据概率转灰度
# transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1), #修改亮度、对比度和饱和度,色调
# ToTensor() should be the last one of the transforms.
transforms.ToTensor(),
])validate的时候要不要加入变换呢?我的理解是要加入,因为validate和train使用相同的样本数据才能保证保存下来的是合适的模型。如果只在train加入变换,validate不做变换,那相当于两者的样本空间不一样,train的时候表现最好的模型,在validate中表现不一定最好。
Test Time Augmentation(TTA):
TTA是在test阶段的数据增强,即在预测的时候将原图变换出来的多张图片分别进行分类,再综合分类结果的方法。
有一个开源的库可以做TTA:https://github.com/qubvel/ttach,但是似乎没有效果,不知道是不是我用错了或者理解错了。自己写了一个简单的函数实现TTA。
def mytta(model, data):
tfm_list = [
transforms.RandomResizedCrop(size=(128, 128), antialias=True),
transforms.RandomHorizontalFlip(p=0.5), #50%的概率水平翻转
transforms.RandomVerticalFlip(p=0.5), #50%的概率垂直翻转
transforms.RandomRotation(degrees=(0, 180)),
transforms.RandomAffine(degrees=(30, 70), translate=(0.1, 0.3), scale=(0.5, 0.75)),
transforms.RandomCrop(128, padding=10),
transforms.RandomGrayscale(p=0.1), #根据概率转灰度channel=1,CNN中in_channel=3,不可行
# transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1) #修改亮度、对比度和饱和度,色调
]
base_rate = 0.5
pred = base_rate * model(data)
# print(f'original pred shape: {pred.shape}')
aug_rate = (1 - base_rate) / len(tfm_list)
for tfm in tfm_list:
pred += aug_rate * model(tfm(data))
return pred上面的代码在TPU可以正常运行,但是在GPU就会引发一个view函数异常,因为变换以后tensor变成不连续的,导致不能直接使用view函数操作。具体参见这篇文章CSDN。
关于TTA有一个疑问,是不是在validation的时候也要增加Data Augmentation呢?因为如果没有变换,通过validation找到的最优模型不一定是真的最优模型。
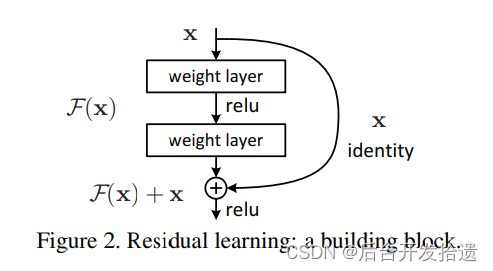
ResNet(残差网络):
残差网络的思想比较简单,就是在网络输出中加上网络输入,这样做可以在最差的情况下(网络训练不好),还能保证输出跟输入一样的数据。通过这种技术使训练多层的网络变得容易起来。放上一张原文的图片就很清晰了。
因为作业不能采用预训练的模型,我尝试了ResNet18,发现要训练的次数比一般自己拼凑的CNN要多得多,计算资源都不太够了,最后用cross validation只训练了3个模型,都跑了600 epochs。
这里又有一个小插曲,前两个模型都没有接全连接层,直接就拿来用了,在assemble的时候才发现,resnet的输出维度是batch*1000。神奇的是,它不用接全连接层也是可以训练和测试的,通过tensor的广播机制蒙混过去了。因为分类是11类,所以最终输出结果里,只有前11列是正数,其他都是负数。因为计算资源有限,所以只能凑合着用了,效果也还行。
Cross Validation + Ensemble
在机器学习里常用的k折交叉验证,这里也派上用场,这里是通过k折,将数据拆分成k份从而训练出k个相对独立的模型,再采用Ensemble方法提升精度。Ensemble说穿了也很简单,就是把多个模型输出的结果做一个整合,有很多方法可选,我用的是输出平均。
我采用k=10,但是因为计算资源有限,只训练了几个模型,用90%的数据训练,再用10%的数据做validation。这两种方法都可以有效提升精度。
Accelerator:
因为要使用多个GPU训练,所以要考虑并行,默认情况下训练只在一个GPU进行。有一个HuggingFace这个项目很好用https://github.com/huggingface/accelerate,不用对原来的代码进行大的调整就可以使代码在多个GPU并行。
有几个踩过的坑记录一下:
(1)Accelerator(mixed_precision='fp16'),带了这个参数就训练不起来,可能是因为数据精度太低,不太确定。
(2)用了set_seed就要把其他配置seed的地方注释掉,否则会报错,re-init 重复初始化问题(RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method)。
(3)还有一个疑问:我的理解是一个epoch里的batch分到两个GPU上计算梯度,计算累加起来做更新,更新的频率可能是两个batch一次,不知道理解得对不对,还是一个epoch只更新一次?
最终结果:
按照网上的资料,学习ResNet,训练ResNet18,600epochs,达到Score: 0.82569。
训练普通的cnn网络,用10-fold训练了2个model,做assemble,也达到了0.82586。
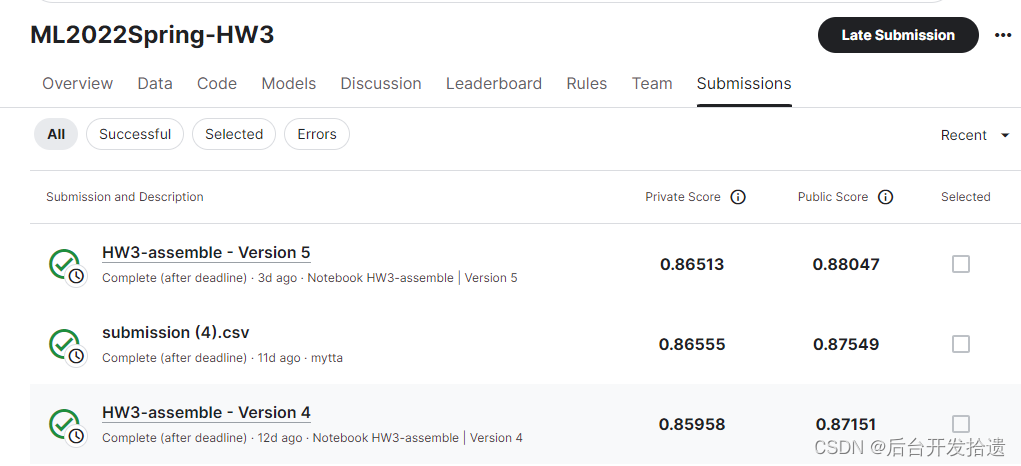
尝到甜头以后,尝试训练更多的model,做assemble,最终达到0.88047,还没有达到boss line 0.88446。不过预计多加几个模型或者微调一下就可以达到了,就不继续刷了。















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









