






损失函数
https://towardsdatascience.com/super-resolution-a-basic-study-e01af1449e13
在GAN出现之前,使用的更多是MSE,PSNR,SSIM来衡量图像相似度,同时也使用他们作为损失函数。
MSE
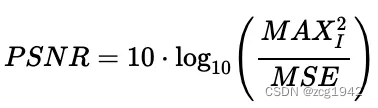
表面上MSE直接决定了PSNR,MSE:
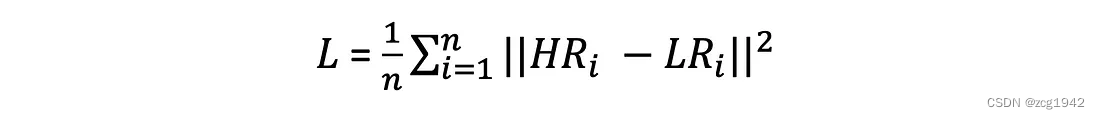
但是这些引以为傲的指标,有时候也不是那么靠谱:

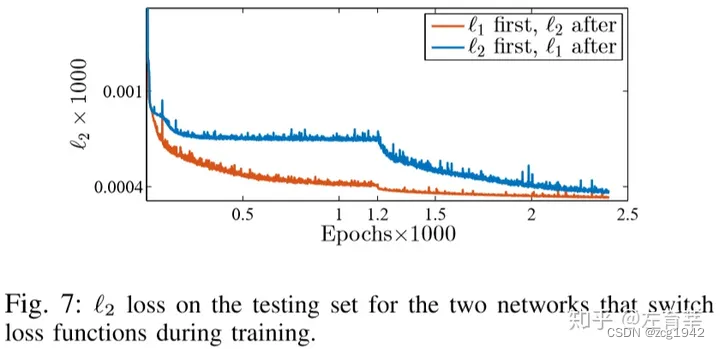
MSE对于大的误差更敏感,所以结果就是会倾向于收敛到期望附近,表现为丢失高频信息。同时根据实验,MSE的收敛效果也差于L1:
MAE

MAE相比于MSE,对所有像素一视同仁,能保留更多高频信息,所以更符合人眼。
但是只使用L1也有问题,现在通常的做法是多种损失混合使用,比如MS-SSIM+L1,还有基于DCT的loss。
在目前超分辨率的论文中不使用MSE,而使用L1或者Perceptual loss的原因是什么? - 知乎
SSIM
Image Quality Assessment: From Error Visibility to Structural Similarity
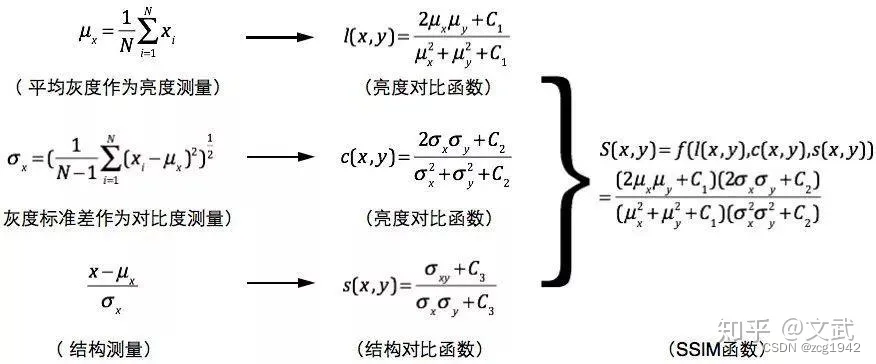
以亮度对比函数为例,忽略常数项(确保分母不为0),亮度对比函数其实是由误差平方大于等于0推导出来的:
误差平方只有当预测值和标签值完全相等才等于0,亮度对比函数小于等于1,只有当二者相等时才会取等于1.
既然来源于MSE,那么和直接使用MSE做损失函数或者评价指标有什么区别?区别就在于SSIM符合Weber’s law。韦伯定律指出了引起人眼关注的亮度变化与背景亮度呈线性关系。预测值和标签值同时扩大10倍,二者的比值不变,SSIM也是不变的;但是MSE就会剧烈变化。
亮度和对比度的相似度分别从均值和方差的角度约束他们在完全相等时达到最大。而对于结构相似度,直接使用的是基于协方差的相关系数。
至于为什么相关系数可以描述结构。其实这是因为预测值和标签值根据均值和方差做归一化之后,再计算协方差,就正好等于预测值和标签值的相关系数:
而相关系数,衡量的是两个变量之间是否是线性关系。当完全线性时,相关系数等于1或者-1。所以ssim可能是负数。取负数其实很好理解,因为协方差等于,而x和y都可能是大于或者等于他们的均值的。一个简单的例子就是左黑右白的图和右黑左白的图,在分界线的位置他们的均值是一样的,但是一个减去均值后是大于0,一个是小于0,这样就可能出现负数。特别地,当两个棋盘格图案正好相反时,他们的ssim会是-1.
很明显,ssim符合交换律。
一般取l,c,s函数的指数项都为1,当c2=c3,c和s函数可以化简,所以看上去最终的SSIM函数只有两部分。
如果指数大于1,因为均值本身就是比较小的数,指数之后可能出现nan的问题。
MS-SSIM
其实就是构建图像金字塔,每一层计算ssim,每一层有不同的权重。
1. 权重不是递进的,而是中间层的权重最大:[0.0448, 0.2856, 0.3001, 0.2363, 0.1333]);
2. 权重是以指数的形式,这和SSIM是一样的;
3. l只有在最后一层参与了计算,而ssim=l*c*s。每一层的函数返回ssim和c*s,连乘发生在不同层的c*s上,最后再乘最后一层的ssim。
results = np.prod(mcs[:-1, :]**weights[:-1, np.newaxis], axis=0) * \
(mssim[-1, :]**weights[-1])https://ece.uwaterloo.ca/~z70wang/publications/msssim.pdf
TV-loss
它更像是一个平滑函数,通过最小化四近邻的差异来平滑噪声。同时也可以看到,它没有考虑对应的HR图像。

上面几种loss都是像素级别的,属于pixel loss。同样是MSE,但如果在特征图上计算,那就是Perceptual Loss/content loss。

提取特征图通常使用预训练好的VGG/ResNet模型。
LPIPS/Perceptual loss

Learned Perceptual Image Patch Similarity,基于VGG等网络提取到的特征计算相似度。感知损失关注于图像的高级特征(如纹理、形状等),这更接近于人类的视觉感知。
Texture Loss
也称为style loss or gram matrix loss。
它借鉴了风格迁移任务,仍然是基于特征图,但是不是直接计算MSE,而是先基于特征图计算gram矩阵。
gram矩阵是特征A和A的转置进行矩阵乘法。格拉姆矩阵由向量两两内积构成,而内积的结果表示的是相似度,所以gram矩阵可以知道特征图不同分量之间的相关性:
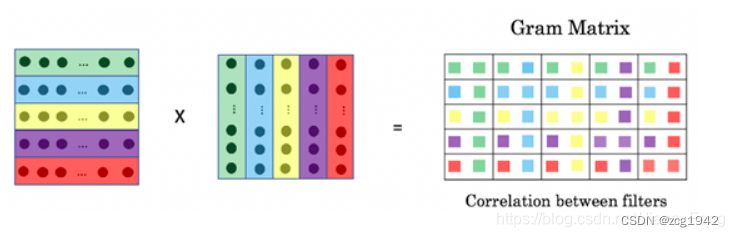
如果两个图的gram矩阵差异小,那么他们是更接近的:

以上的loss基本都可以在basicSR中找到。
算法
SRGAN,ESRGAN,Real ESRGAN,一步步演化,对比着看才更容易理解。
SRCNN
这是第一篇使用CNN做超分的算法。
首先使用bi-cubic将LR图像上采样上来,然后使用CNN提取特征,同时学习映射关系。损失函数使用的依然是MSE,但仍然获得了更多的细节。

SRGAN
SRGAN主要从损失函数的角度优化。因为发现一MSE为损失函数时,网络会倾向于平均的结果,表现在图像上就是过于平滑,丢失细节。https://arxiv.org/pdf/1609.04802.pdf

SRGAN使用了两个损失函数,一个是使用VGG的特征图,在特征图上计算欧式距离。第二个损失函数是使用对抗网络中的鉴别器,判断当前输出结果是否是真实的HR数据。

ESRGAN
ESRGAN在损失函数上继续优化。特征图损失部分,使用的是激活前的而不是激活后的,因为激活后的未免太抽象;

鉴别器损失部分,借鉴relativistic GAN,使用相对损失而不是绝对损失。
除了损失函数,网络结构方面也是把残差,dense net组合成更复杂的RRDB:
首先是构建Dense Block,卷积越往后,接受的通道数越多(因为是之前所有的输出和最开始的输入)。Dense Block把输出和输入线性组合,就是RDB。RRDB就是把三个RDB串起来,再把输出和输入做线性组合。组合的时候,输出只占0.2.
最终以PSNR和GAN为目标,作者训练了两套模型参数,对两套参数加权融合,可以互补二者的优缺点。

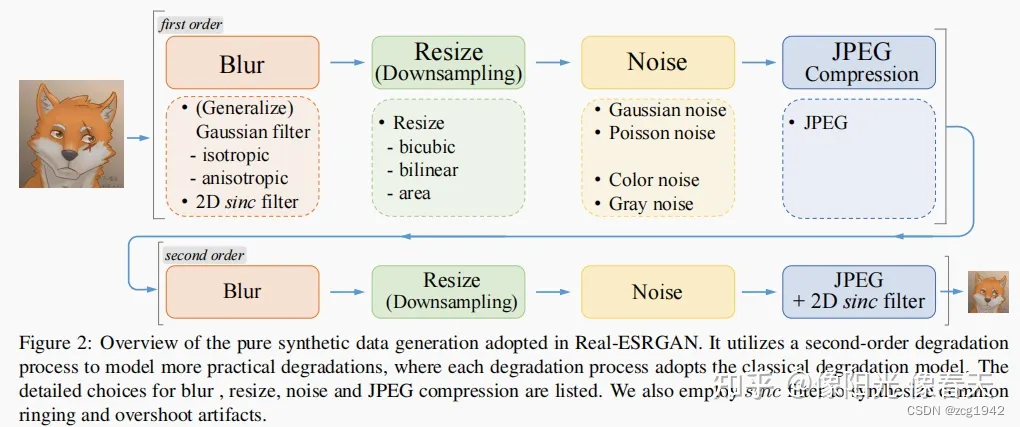
Real ESRGAN
Real ESRGAN主要的贡献是数据对的生成。通过模糊,下采样,加噪声,压缩,模拟振铃效应等得到了更接近真实退化的图像对:















 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









