







吴恩达【深度学习工程师】专项课程包含以下五门课程:
1、神经网络和深度学习;
2、改善深层神经网络:超参数调试、正则化以及优化;
3、结构化机器学习项目;
4、卷积神经网络;
5、序列模型。
今天介绍《改善深层神经网络:超参数调试、正则化以及优化》系列第二讲:优化算法。
主要内容:1、Mini-batch梯度下降法;
2、指数加权平均;
3、momentum、RMSProp、Adam优化算法;
4、学习率衰减.
1、 Mini-batch 梯度下降法
神经网络训练过程是对所有m个样本,称为batch,通过向量化计算方式,同时进行运算。这种梯度下降算法被称为Batch Gradient Descent。
我们可以把m个训练样本分成若干个子集,称为mini-batch,这样每个子集包含的数据量就小了,每次在单一子集上进行神经网络训练,网络收敛的速度就会大大提高。这种梯度下降算法被称为Mini-batch Gradient Descent。
假设总的训练样本个数m=5 000 000,其维度为 (nx,m) 。将其分成5000个子集,每个mini-batch含有1000个样本。我们将每个mini-batch记为 X{t} ,其维度为 (nx,1000) 。相应的每个mini-batch的输出记为 Y{t} ,其维度为 (1,1000) ,且 t=1,2,⋯,5000 。
Mini-batch Gradient Descent的实现过程是:将训练样本分成 N 个 mini-batches,对每个mini-batch进行神经网络训练,经过N次循环之后,所有m个训练样本都进行了梯度下降计算,我们称之为经历了一个epoch。使用Batch Gradient Descent时,一个epoch只进行一次梯度下降算法;而使用Mini-BatchGradient Descent时,一个epoch会进行 N 次梯度下降算法。
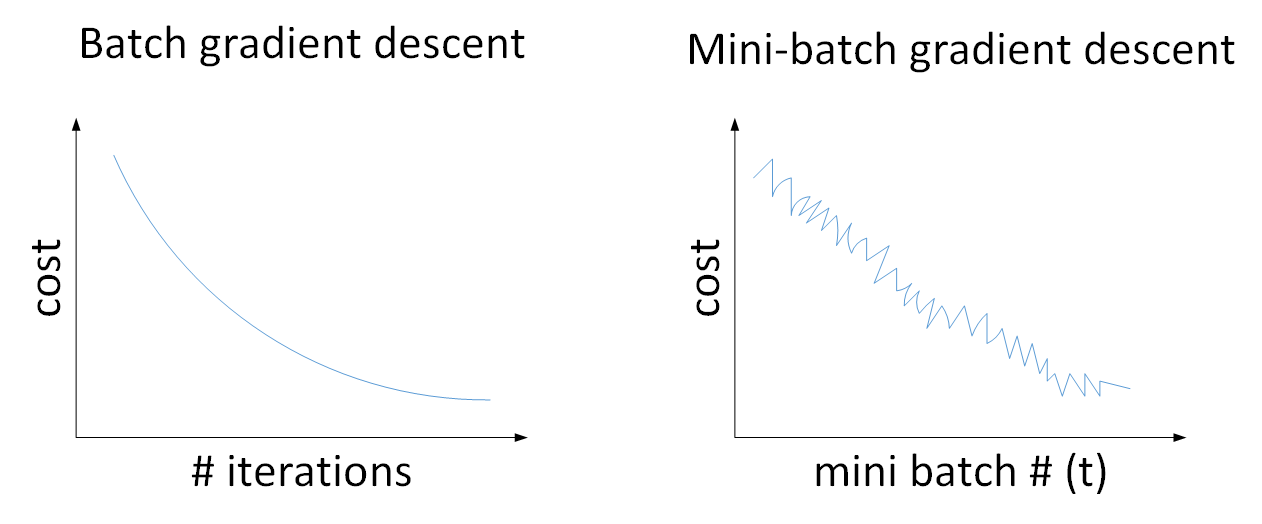
使用Batch gradient descent,随着迭代次数增加,cost是不断减小的;使用Mini-batch gradient descent,随着在不同的mini-batch上迭代训练,由于不同的mini-batch之间是有差异,因此其cost不是单调下降,而是出现振荡,但整体趋势是下降的。
mini-batch 大小参数通常设置为 64, 128, 256, 512。
2、指数加权平均
举个例子,记录半年内伦敦市的气温变化,并在二维平面上绘制出来,如下图所示:
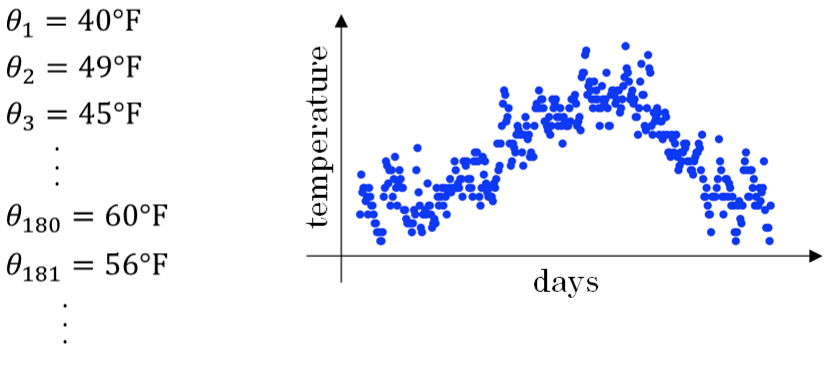
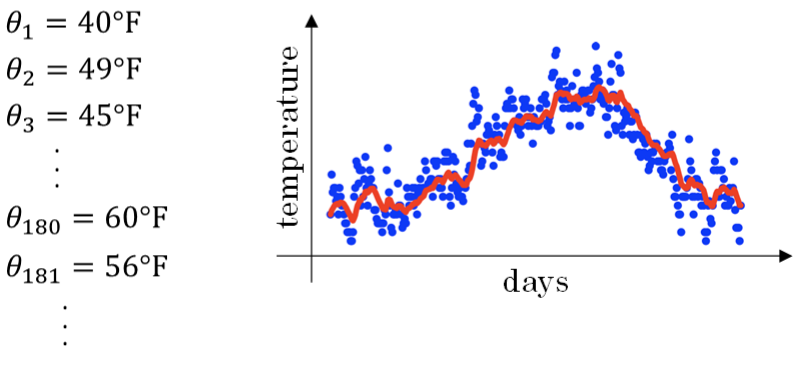
温度数据抖动较大。如果我们希望看到半年内气温的整体变化趋势,可以通过移动平均(moving average)的方法来对每天气温进行平滑处理。
例如我们可以设 V0=0 ,当成第0天的气温值。
第一天的气温与第0天的气温有关:
第二天的气温与第一天的气温有关:
即第t天与第t-1天的气温迭代关系为:
经过移动平均处理得到的气温红色曲线:
这种滑动平均算法称为指数加权平均(exponentially weighted average)。其一般形式为:
上面的例子中, β=0.9 。 β 值决定了指数加权平均的天数,近似表示为:
例如,当 β=0.9 ,则 11−β=10 ,表示将前10天进行指数加权平均。当 β=0.98 ,则 11−β=50 ,表示将前50天进行指数加权平均。 β 值越大,则指数加权平均的天数越多,平均后的趋势线就越平缓,但是同时也会向右平移。
当 β=0.98 时,指数加权平均结果如下图绿色曲线所示。但是实际上,真实曲线如紫色曲线所示。
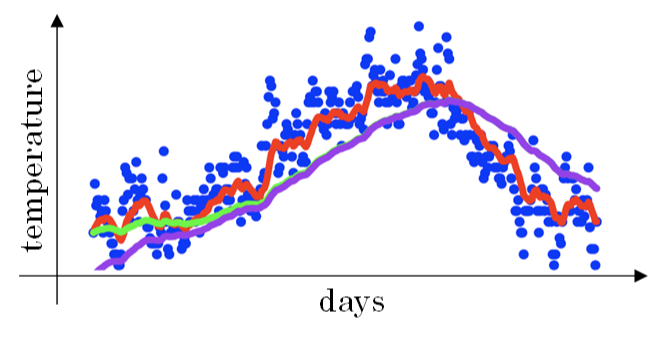
其中,紫色曲线开始的时候相对较低一些。这是因为开始时我们设置 V0=0 ,所以初始值会相对小一些,直到后面受前面的影响渐渐变小,趋于正常。
修正这种问题的方法是进行偏移校正(bias correction),即在每次计算完 Vt 后,对 Vt 进行下式处理:
在刚开始的时候,t比较小, (1−βt)<1 ,这样就将 Vt 修正得更大一些,效果是把紫色曲线开始部分向上提升一些,与绿色曲线接近重合。随着t增大, (1−βt)≈1 , Vt 基本不变,紫色曲线与绿色曲线依然重合。这样就实现了简单的偏移校正,得到我们希望的绿色曲线。
但是偏移校正并不总是必须的。因为,在一次次迭代后, Vt 受初始值影响越来越小,紫色曲线与绿色曲线基本重合。所以,在经过一段初始迭代过程后,再取值就不需要进行偏移校正了。
3、momentum
动量梯度下降算法,是指在每次训练时,对梯度进行指数加权平均处理,然后用处理后的梯度值更新权重W和常数项b。
原始的梯度下降算法在梯度下降过程中,梯度下降的振荡较大。每一点处的梯度只与当前方向有关,产生类似折线的效果,前进缓慢。而如果对梯度进行指数加权平均,这样使当前梯度不仅与当前方向有关,还与之前的方向有关,这样处理让梯度前进方向更加平滑,减少振荡,能够更快地到达最小值处。
权重W和常数项b的指数加权平均表达式如下:
从动量的角度来看,以权重W为例, VdW 可以看成速度V, dW 可以看成是加速度a。指数加权平均实际上是计算当前的速度,当前速度由之前的速度和现在的加速度共同影响。
初始时令 VdW=0,Vdb=0 。 β=0.9 ,即指数加权平均前10天的数据。
关于偏移校正可以不使用。因为经过10次迭代后,随着滑动平均的过程,偏移情况会逐渐消失。
补充一下,在其它文献资料中,动量梯度下降还有另外一种写法:
即消去了 dW 和 db 前的系数 (1−β) 。这样简化了表达式,但是学习因子 α 相当于变成了 α1−β ,表示 α 也受 β 的影响。从效果上来说,这种写法也是可以的,但是不够直观,且调参涉及到 α ,不够方便。所以,实际应用中,推荐第一种动量梯度下降的表达式。
4、RMSprop
RMSprop梯度下降算法。每次迭代训练过程中,权重W和常数项b的更新表达式为:
在RMSprop算法中,如果梯度下降在垂直方向(b)上振荡较大,在水平方向(W)上振荡较小,表示在b方向上梯度较大,即
db 较大,而在W方向上梯度较小,即 dW 较小。因此,上述表达式中 Sb 较大,而 SW 较小。在更新W和b的表达式中,变化值 dWSW√ 较大,而 dbSb√ 较小。也就使得W变化得多一些,b变化得少一些。也就是说,如果哪个方向振荡大,就减小该方向的更新速度,从而减小振荡。
为了避免RMSprop算法中分母为零,通常可以在分母增加一个极小的常数 ε :
其中, ε=10−8 ,或者其它较小值。
5、 Adam优化算法
Adam(Adaptive Moment Estimation)算法结合了动量梯度下降算法和RMSprop算法。其算法流程为:
VdW=0, SdW, Vdb=0, Sdb=0
On iteration t:
Cimpute dW, db
VdW=β1VdW+(1−β1)dW, Vdb=β1Vdb+(1−β1)db
SdW=β2SdW+(1−β2)dW2, Sdb=β2Sdb+(1−β2)db2
VcorrecteddW=VdW1−βt1, Vcorrecteddb=Vdb1−βt1
ScorrecteddW=SdW1−βt2, Scorrecteddb=Sdb1−βt2
W:=W−αVcorrecteddWScorrecteddW√+ε, b:=b−αVcorrecteddbScorrecteddb√+ε
Adam算法包含了几个超参数,分别是: α,β1,β2,ε 。其中, β1 通常设置为0.9, β2 通常设置为0.999, ε 通常设置为 10−8 。一般只需要对 β1 和 β2 进行调试。
6、学习率衰减
学习率衰减 (learning rate decay)是一种随着迭代次数的增加,逐步减小学习因子 α 的方法。
随着训练次数增加, α 逐渐减小,步进长度减小,使得能够在最优值处较小范围内微弱振荡,不断逼近最优值。相比较恒定的 α 来说,learning rate decay更接近最优值。
其中,deacy_rate是参数,epoch是训练完所有样本的次数。随着epoch增加, α 会不断变小。
除了上面计算 α 的公式之外,还有其它可供选择的计算公式:
其中,k为可调参数,t为mini-bach number。
除此之外,还可以设置 α 为关于t的离散值,随着t增加, α 呈阶梯式减小。















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









