







最近在探究命名实体识别相关的内容。命名实体存在嵌套(nested)现象,例如
[[0, 3, '上海市', 'LOC'], [0, 6, '上海市公安局', 'ORG'], [0, 10, '上海市公安局奉贤分局', 'ORG'], [0, 14, '上海市公安局奉贤分局治安支队', 'ORG'], [6, 8, '奉贤', 'LOC'], [16, 18, '金海', 'LOC'], [16, 21, '金海派出所', 'ORG']]
‘上海市公安局奉贤分局’中的“上海市”是地点实体LOC,“上海市公安局”是组织实体ORG。有的模型不能标注这些嵌套实体,只能标注平坦(flat)实体。那么对于嵌套实体,可以将其线性化(Linearization),只标注’上海市公安局奉贤分局’,而不关注其中嵌套的实体。
嵌套实体主要形成“树状结构”,如果我们按照实体的嵌套关系构造树的话,我们可以发现,实体一般没有“重合关系”,如下图所示:
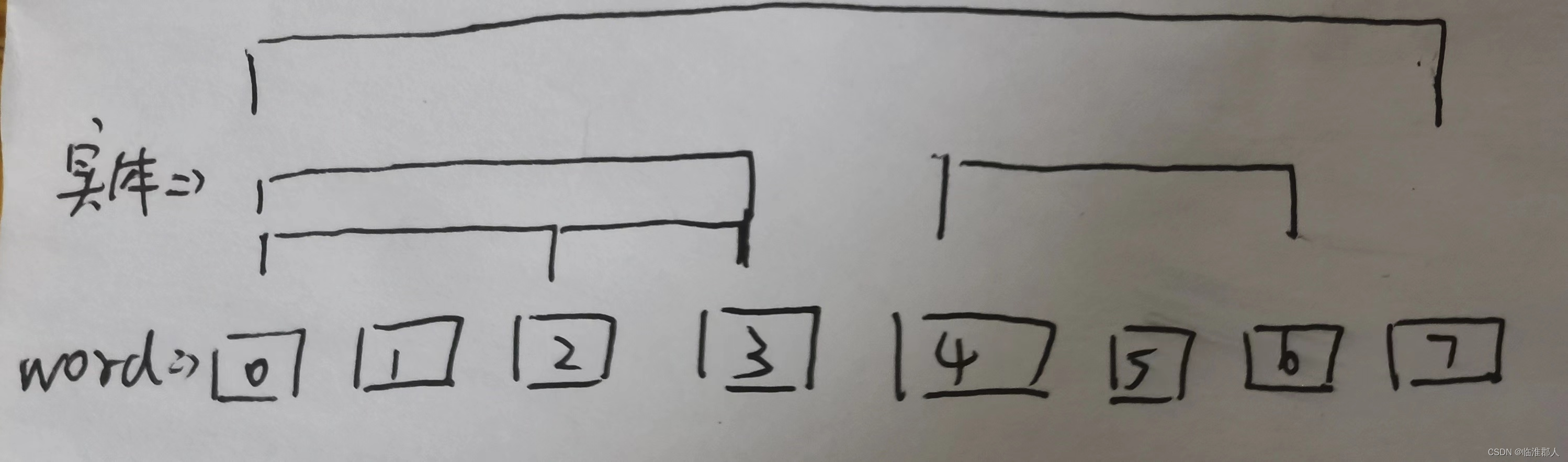
将嵌套实体“线性化”(Linearization)的方法有很多,考虑到实体“不存在交汇的情况”,在这里我采取最简单的方法,将只取嵌套实体的最大者或者最小者,将实体平坦化,其他不看。
1.数据集格式
原本的数据集格式如下:
{"sentence": "新华社北京八月十一日体育专电中国足协十一日消息", "audio": "BAC009S0139W0495", "entity": [[0, 3, "新华社", "ORG"], [3, 5, "北京", "LOC"], [14, 18, "中国足协", "ORG"], [14, 16, "中国", "LOC"]], "speaker_info": "F"}
我们希望将其转化为如下格式,如下是最大实体平坦化的结果:
{"text": ["新", "华", "社", "北", "京", "八", "月", "十", "一", "日", "体", "育", "专", "电", "中", "国", "足", "协", "十", "一", "日", "消", "息"], "label": ["B-ORG", "I-ORG", "I-ORG", "B-LOC", "I-LOC", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-ORG", "I-ORG", "I-ORG", "I-ORG", "O", "O", "O", "O", "O"]}
2. 最大实体平坦化
由于实体不会出现
b
e
g
i
n
A
<
b
e
g
i
n
B
<
e
n
d
A
begin_A < begin_B <end_A
beginA<beginB<endA、
b
e
g
i
n
A
<
e
n
d
B
<
e
n
d
A
begin_A < end_B <end_A
beginA<endB<endA的情况,因此还是比较方便的。
我们考虑一般化的情况,实体间的关系无外乎以下几种情况。
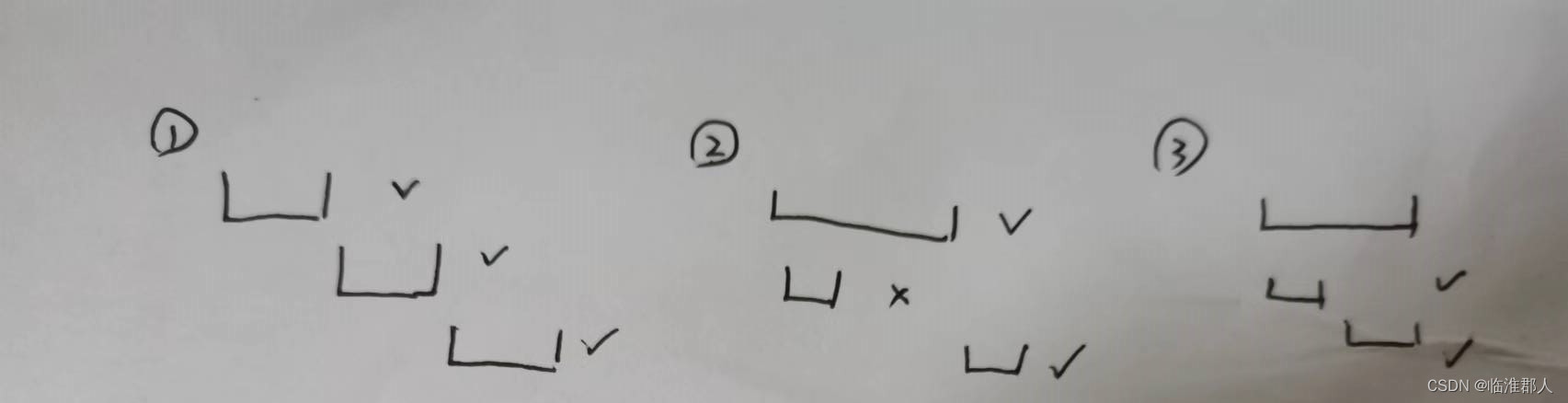
由于我们需要对实体的区间[begin,end]做探讨,因此维护序列的首尾排序关系是比较重要的。在这里,我们可以总结最大实体的必要条件:
- 同begin的实体中,end最大的可能是最大实体;
- 不同begin的实体中,begin最小、end最大的可能是最大实体。
因此这里,我们首先对实体排序,维护实体的begin的升序关系,希望end最好也是升序的。按照begin的大小,从小到大排序;当begin相同的时候,按照end从小到大排序。
那么如果是只有第一种情况,那么问题很简单,我只需要观察begin什么时候发生变化,并把发生变化前的最后一个实体视作最大实体就行。
但是我们不能只保存前一个实体的信息,例如情况2。其中嵌套的实体begin和最大实体不同,但是其end反而收缩了。换言之,我们需要维护end的最大值:对于某个嵌套的最大实体A,当我们发现另一个实体B的begin大于等于A的end时,我们可以确定,实体B之前,end最大,begin最小的是最大实体。因此,我们还必须记录最大end是哪一个实体保持的。
最后是边界条件,我们不能在看到下一个实体前,判断本实体是否被嵌套了。因此,需要特判最后一个实体。自然而然的,还有:
- 空实体,什么都没有;
- 一个实体,即同是最后一个,也是非尾部的实体。
最终代码见“完整代码”。
3. 最小实体平坦化
同理,我们分析相应情况。

同理,维护序列的首尾排序关系是比较重要的。在这里,我们可以总结最大实体的必要条件:
- 同begin的实体中,end最小的一定是**同begin*最小实体;
- 不同begin的实体中,begin大、end小的可能是最小实体。
其实,既然我们能根据条件1确定实体,那么最小实体的判别就比最大实体简单了。但是只有同begin的最小实体未必是最小实体,例如情况2,同begin时,最大实体也是同begin的最小实体。因此,我们通过判别end就行。
由于要考察同begin中end最小的实体,因此,这里按照begin升序,同begin时要求end降序排序。(当然似乎end升序也行?)
具体的,我们也不能通过当前实体,判断自己的状况,通过当前实体的begin变化,可以判断前一个实体是否可能是最小实体。这时候,唯一的干扰情况就是情况2、3中,同begin中只有1个实体的情况,我们只需要判断end是否较小就行。这里,不需要维护最大实体的end,只需要维护上一个实体的end,比上一个大就行。因为,end较小,我们已经将其排除了,我们不需要记录它,后续的实体判断与他无关了。
考虑边界条件,最后一个实体,其实一定是最小实体,因为不会有begin比它大的实体了。
4. 完整代码
from tqdm import tqdm
import json
from functools import cmp_to_key
# sorted(iterable, cmp=None, key=None, reverse=False)
def load_lines(path, encoding='utf8'):
with open(path, 'r', encoding=encoding) as f:
lines = [line.strip() for line in f.readlines()]
return lines
def get_input_data(file,order=True):
lines = load_lines("./origin/"+file+".json")
lengdict={}
totalresult=[]
if order:
flattener=max_flater
cmp=cmp1
else:
flattener=min_flater
cmp=cmp2
origin,flat=[],[]
tarfile={"train":"train","test":"test","valid":"dev"}
with open(tarfile[file]+".json", 'w',encoding='utf-8') as fw:
for (idx,line) in tqdm (enumerate(lines)):
data = json.loads(line)
txt=data["sentence"]
entities=data["entity"]
entities.sort(key=cmp_to_key(cmp))
ens=flattener(entities)
if len(entities) > 1:
if len(ens) != len(entities):
flat.append((idx,ens))
origin.append((idx,entities))
tagcheck(ens,lengdict)
result=processor(txt,ens)
fw.write(json.dumps(result,ensure_ascii=False)+'\n')
# 检查结果
with open(file+"_origin.txt", 'w',encoding='utf-8') as f:
for idx,line in origin:
f.write(str(idx)+" "+str(line)+"\n")
with open(file+"_flat.txt", 'w',encoding='utf-8') as f:
for items in flat:
f.write(str(items)+"\n")
def processor(txt,ens):
text=list(txt)
labellist=["O" for i in text]
for en in ens:
begin,end=en[0],en[1]
for j in range(begin+1,end):
labellist[j]="I-"+en[3]
labellist[begin]="B-"+en[3]
assert len(labellist) ==len(text)
return {"text":text,"label":labellist}
def cmp1(a,b):
'''
for max flatter
'''
if a[0] < b[0]:
return -1
elif a[0]==b[0] and a[1] < b[1]:
return -1
else:
return 1
def cmp2(a,b):
'''
for min flatter
'''
if a[0] < b[0]:
return -1
elif a[0]==b[0] and a[1] > b[1]:
return -1
else:
return 1
def max_flater(enlist):
if enlist==[]:
return enlist
result=[]
leng=len(enlist)
if leng==1:
return enlist
# 不是首部特判,是特判超大实体的情况
begin1,end1=enlist[0][0],enlist[0][1]
flag=0
lastin=-1
for i in range(1,leng):
begin,end=enlist[i][0],enlist[i][1]
if end1 <= begin :
result.append(enlist[flag])
lastin=flag
if end1 >= end:
continue
begin1,end1,flag=begin,end,i
# 首部、中间特判:
if lastin!=flag and flag!=leng-1:
result.append(enlist[flag])
# 尾部特判
begin1,end1=enlist[leng-2][0],enlist[leng-2][1]
begin,end=enlist[leng-1][0],enlist[leng-1][1]
if end1 <= begin :
result.append(enlist[leng-1])
elif begin==begin1 and end>end1:
result.append(enlist[leng-1])
return result
def min_flater(enlist):
if enlist==[]:
return enlist
leng=len(enlist)
if leng==1:
return enlist
result=[]
begin1,end1=enlist[0][0],enlist[0][1]
for i in range(1,leng):
begin,end=enlist[i][0],enlist[i][1]
if begin!=begin1 and end1 < end:
result.append(enlist[i-1])
begin1,end1=begin,end
result.append(enlist[leng-1])
return result
def check(enlist,origin):
if enlist==[]:
return
leng=len(enlist)
begin1,end1=enlist[0][0],enlist[0][1]
for i in range(1,leng):
begin=enlist[i][0]
end=enlist[i][1]
if begin < end1 and begin >= begin1:
print("error")
break
def tagcheck(enlist,lengdict):
for items in enlist:
if items[3] not in lengdict.keys():
lengdict[items[3]]=set()
else:
lengdict[items[3]].add(len(items[2]))
order=False
filelist=["train","test","valid"]
for file in filelist:
print("------------"+file+"---------------")
get_input_data(file,order)
一些测试用例:
# flater test
case=[[0, 2, '香港', 'LOC'], [0, 4, '香港联想', 'ORG'], [2, 4, '联想', 'ORG']]
case=[[0, 2, '长春', 'LOC'], [0, 7, '长春外国语学校', 'ORG'], [0, 11, '长春外国语学校实验小学', 'ORG']]
case=[[0, 3, '上海市', 'LOC'], [0, 6, '上海市公安局', 'ORG'], [0, 10, '上海市公安局奉贤分局', 'ORG'], [0, 14, '上海市公安局奉贤分局治安支队', 'ORG'], [6, 8, '奉贤', 'LOC'], [16, 18, '金海', 'LOC'], [16, 21, '金海派出所', 'ORG']]
case=[[2, 5, '潜山路', 'LOC'], [5, 9, '绿地蓝海', 'LOC'], [10, 12, '滴滴', 'ORG'], [10, 14, '滴滴打车', 'ORG']]
case=[[0, 1, '哈', 'LOC'], [0, 2, '哈大', 'LOC'], [1, 2, '大', 'LOC'], [2, 3, '盘', 'LOC'], [2, 4, '盘营', 'LOC'], [3, 4, '营', 'LOC']]
case=[[3, 6, '慈云寺', 'LOC'], [3, 7, '慈云寺桥', 'LOC'], [7, 10, '车道沟', 'LOC'], [7, 11, '车道沟桥', 'LOC'], [11, 14, '学知桥', 'LOC'], [14, 16, '林大', 'ORG'], [14, 18, '林大北路', 'LOC']]
case=[[0, 3, '车晓曦', 'PER'], [3, 6, '王博三', 'PER'], [9, 11, '鲁能', 'ORG'], [9, 14, '鲁能青岛队', 'ORG'], [11, 13, '青岛', 'LOC'], [15, 18, '王艺迪', 'PER'], [18, 21, '刘丁硕', 'PER']]
case=[[0, 2, '厦门', 'LOC'], [0, 4, '厦门大学', 'ORG'], [0, 13, '厦门大学中国能源经济研究所', 'ORG'], [4, 6, '中国', 'LOC'], [15, 18, '林伯强', 'PER']]
case=[[0, 3, '新京报', 'ORG'], [1, 2, '京', 'LOC']]
case=[[0, 2, '北京', 'LOC'], [2, 9, '摩托二环十三郎', 'PER'], [4, 9, '二环十三郎', 'PER'], [4, 6, '二环', 'LOC']]
if order:
flattener=max_flater
cmp=cmp1
else:
flattener=min_flater
cmp=cmp2
case.sort(key=cmp_to_key(cmp))
# re=max_flater(case)
re=min_flater(case)
print(re)















 1989
1989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









