







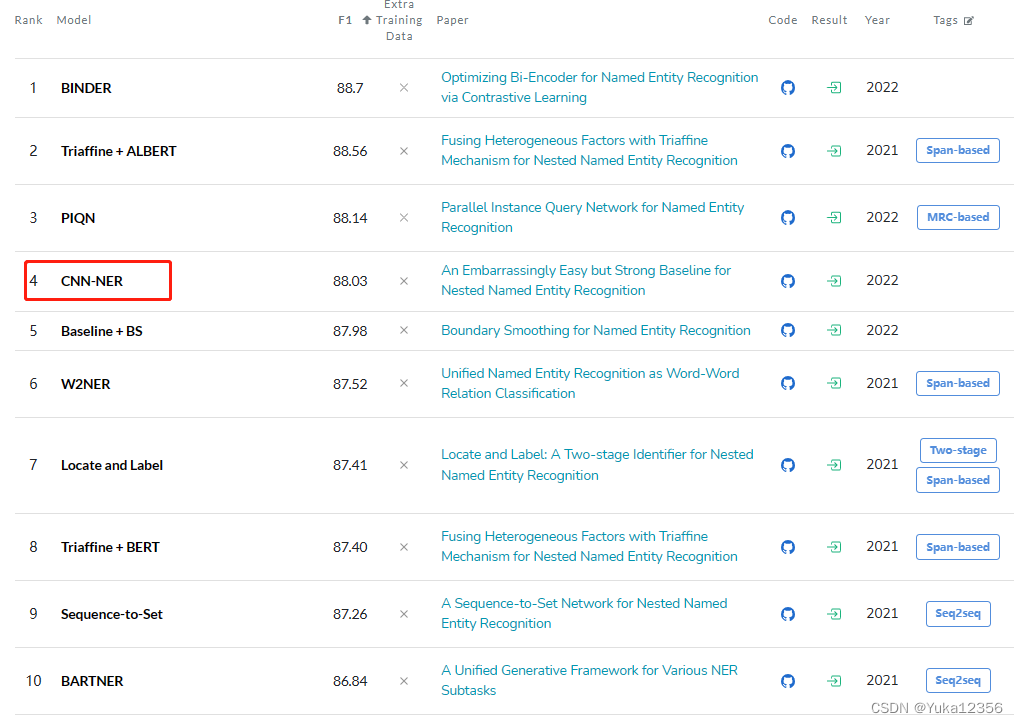
23/6/15
摘要
命名实体识别是对文本中的实体跨度进行检测和分类的任务。当实体跨度彼此重叠时,此问题被命名为嵌套NER。基于跨度的方法已被广泛用于解决嵌套NER问题。这些方法中的大多数都会得到一个分数为n×n的矩阵,其中n表示句子的长度,每个条目对应一个跨度。然而,先前的工作忽略了分数矩阵中的空间关系( spatial relations)。
在本文中,我们建议使用卷积神经网络(CNN) 在分数矩阵中对这些空间关系进行建模。进一步的分析表明,使用CNN可以帮助模型找到更多的嵌套实体。
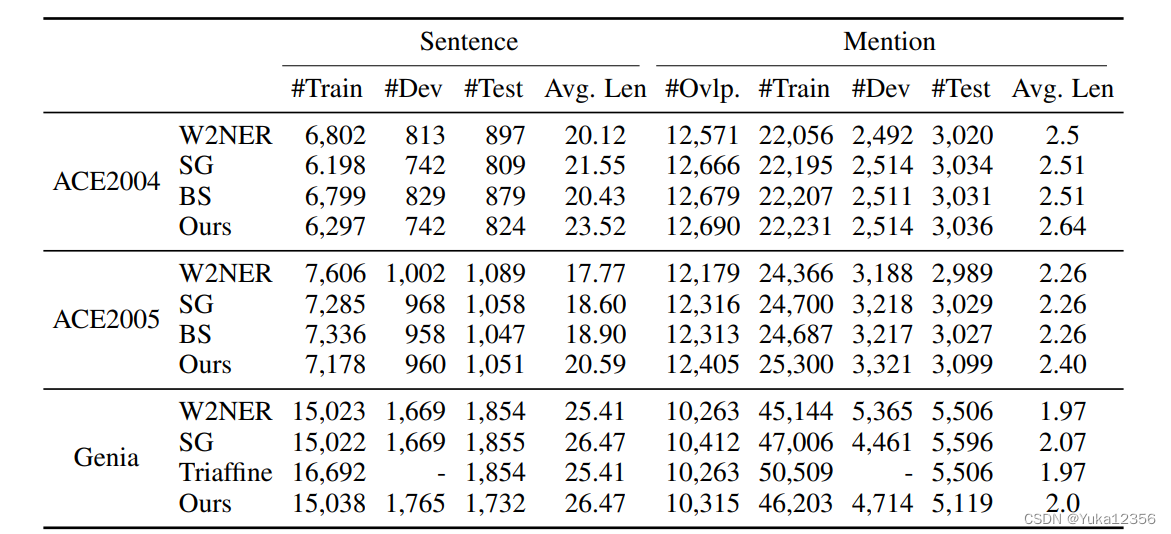
另外,我们发现不同论文在三个嵌套的NER数据集使用不同的tokenizations,这会影响比较。因此作者提供了一个预处理脚本,以便于进行比较
介绍
传统NER、嵌套NER的发展。嵌套的方法:使用实体类型作为查询,并要求模型选择属于该实体类型的跨度(MRC值得看)。然而,这些工作没有利用相邻跨度之间的空间相关性。如图1所示,跨度周围的跨度与中心跨度具有特殊关系。在本文中,我们使用Biaffine解码器(Dozat和Manning,2017)来获得3D特征矩阵,其中每个条目代表一个跨度。之后,我们将该特征矩阵视为图像,并利用卷积神经网络(CNN)对跨度之间的局部交互进行建模。
a:a后与o冲突(跨度边界交叉,a和o至少有一个不是实体,也可能都不是)
b:b前与o冲突
c:跨度包含了中心跨度
d:跨度在中心跨度内
e:跨度和中心跨度无冲突
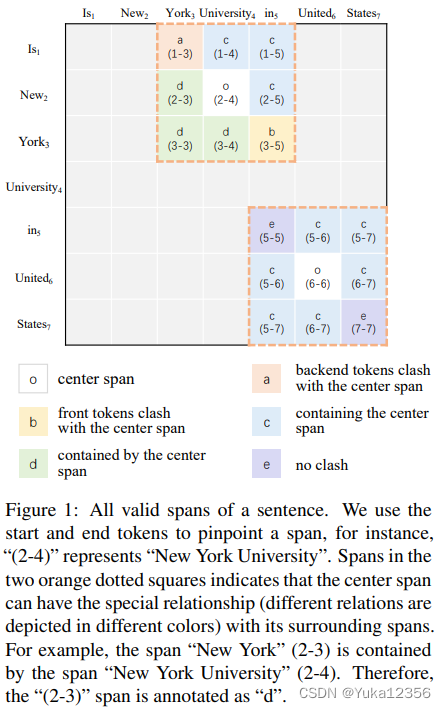
(这里只有包含和被包含的关系)
作者与近期的方法对比。为了确保我们的方法与他们的方法具有严格的可比性,我们向作者询问了他们的数据版本。尽管他们都使用了相同的数据集,但我们发现统计数据,如句子和实体的数量,并不相同。这是由于使用了不同的sentence tokenizen方法,这将影响性能(实验表明)。为了便于将来进行比较,我们发布了ACE2004、ACE2005和Genia数据集的预处理脚本。
贡献:
1)发现相邻跨度之间具有特殊的相关性,并提出使用CNN对它们之间的相互作用进行建模。尽管非常简单,但它在三个广泛使用的嵌套NER数据集中实现了相当大的性能提升
2)我们发布了三个嵌套NER数据集的预处理脚本,以便于直接和公平的比较。
3)我们将跨度特征矩阵视为图像的方式将为嵌套NER任务的基于跨度的方法的未来部署提供一些启示
相关工作
- 序列标注
- 超图
- Seq2Seq
- 跨度分类
3 方法
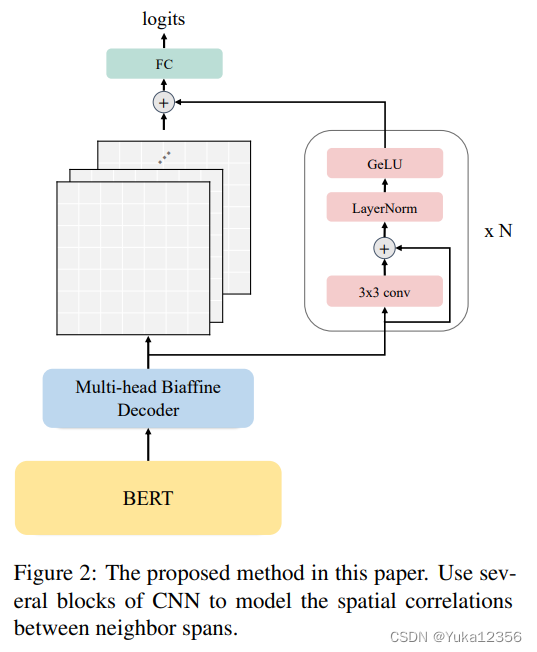
在本节中,我们首先介绍嵌套的NER任务,然后描述如何获得特征矩阵。然后进行CNN卷积。框架如图2所示。
3.1 嵌套实体任务
1)X=[x1,x2,x3,…,xn]。
2)任务是识别出X中的实体,每个实体可以被视为三元组{start,end,entity type}。
3)实体可能相互重叠,但不同的实体不允许有交叉边界
4)对于一句话n个tokens,span有n(n+1)/2个。
3.2 跨度方法的嵌套识别
1)句子编码,H ∈ Rn×d,Encoder可以是BERT。For the word tokenized into several pieces, we use max-pooling to aggregate from its pieces’ hidden states.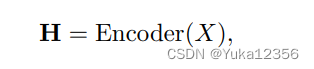
2)使用多头Biffine(MHBiffine)

仿照Biffine的方式得到R特征矩阵,n×n×r,r是特征维数。在下三角部分做了对称。
3.3 CNN卷积
我们在模型中多次重复以下CNN块:

其中Conv2d、LayerNorm和GeLU是2D CNN、层归一化(Ba et al.,2016)和GeLU激活函数(Hendrycks和Gimpel,2016)。层归一化是在特征维度中进行的。
由于句子长度不同,它们的Rs的形状也不同。为了确保批量处理R时的结果相同,2D CNN没有偏差项,并且R中的所有填充都用0 padding。在通过几个CNN块之后,R00将被另一个2D CNN模块进一步处理。
3.4 输出
- 感知机得到 prediction logits,P ∈ Rn×n×|T|(T是实体种类)。没有用Softmax原因是在极少数情况下(例如在ACE2005和Genia数据集中),一个跨度可以有多个entity tag。(使用Sigmoid代替Softmax的原因是,在某些情况下(如ACE2005和Genia数据集),一个span可能具有多个实体标签。Sigmoid函数可以将每个标签视为独立的二分类问题,从而适用于这种多标签分类场景。相比之下,Softmax函数将标签之间视为互斥的,并且在只能选择一个标签的情况下进行分类,不适用于多标签分类。)
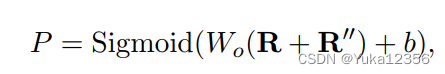
4 实验
设置
数据集:ACE 2004、ACE 2005和Genia
此外,我们选择最近发表的论文作为基线。为了确保我们的实验与他们的实验具有严格的可比性,我们向作者询问了他们的数据版本。
对于ACE2004和ACE2005,使用不同的sentence tokenizations,导致了不同数量的句子和实体。为了促进未来对嵌套NER的研究,我们发布了预处理代码,并修复了一些标记化问题,以避免包含未标注的文本和dropout的实体。而对于Genia数据,我们修复了一些注释冲突(同一个句子有不同的实体注释)。我们将每个实验重复五次,并用标准推导报告其平均性能。
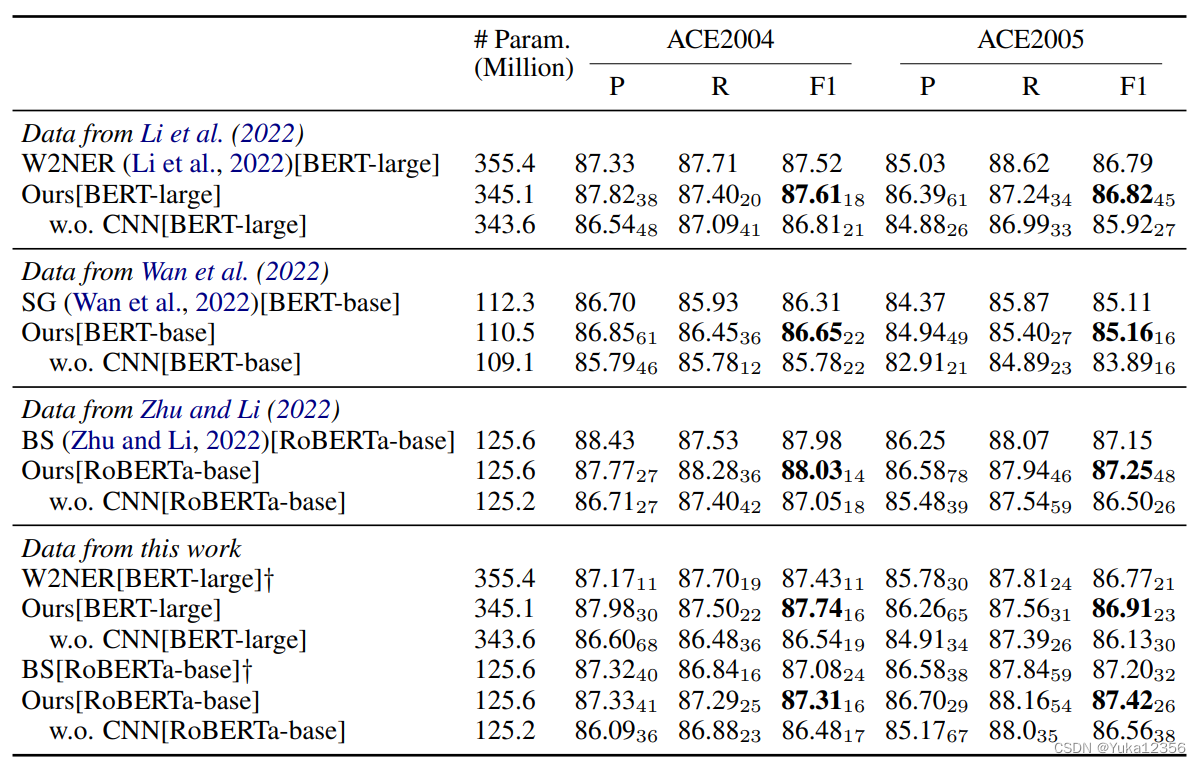
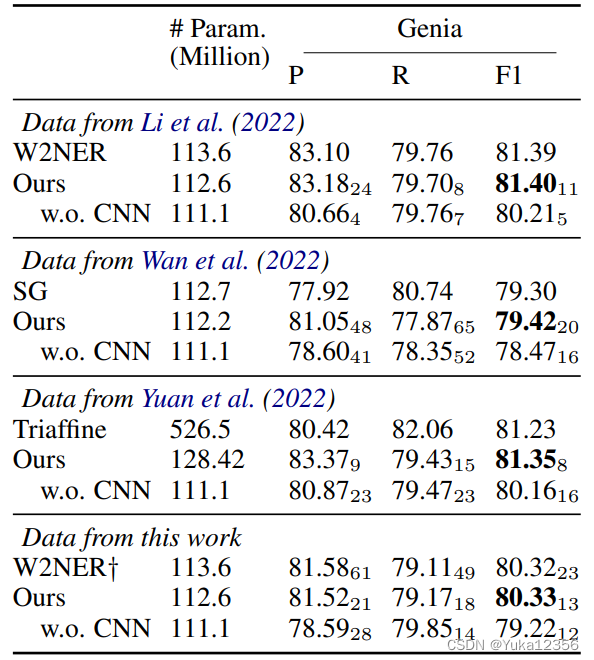
4.2 结果
4.3 CNN作用
为了研究为什么CNN可以提高嵌套NER数据集的性能,我们将实体分为两种。一种是与其他实体重叠的实体,另一种是不重叠的实体。与没有CNN的模型相比,有CNN的模型的ACE2004、ACE2005和Genia的NEP分别提高了2.2、2.8和10.7。也就是说,大部分性能改进可以归因于找到更多的嵌套实体。这是意料之中的事,因为当相邻实体嵌套时,CNN可以更有效地利用它们

FEP、FER、NEP和NER分别是平面实体精度、平面实体召回、嵌套实体精度和嵌套实体召回。
总结
在本文中,我们建议在基于跨度的NER模型的得分矩阵上使用CNN。尽管这种方法非常简单,但它实现了与最近提出的方法相当或更好的性能。分析表明,通过CNN利用相邻跨度之间的空间相关性可以帮助模型找到更多的嵌套实体。实验表明,不同的标记确实会影响性能。因此,有必要确保所有比较基线使用相同的标记化。为了便于将来进行比较,我们为三个嵌套的NER数据集重新租赁了一个新的预处理脚本。














 2783
2783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









