









1 简介
本文根据2022年《Hierarchical Text-Conditional Image Generation with CLIP Latents》翻译总结的。如题,基于CLIP进行图片生成。CLIP可以参考https://blog.csdn.net/zephyr_wang/article/details/126915466。
这个也是DALL·E 2 ,即OpenAI第二代文本生成图片模型。
第一代DALL·E,详见https://blog.csdn.net/zephyr_wang/article/details/130021457
我们的模型根据文本生成的图片效果如下,具有很强的图片现实主义。

我们叫我们的模型为unCLIP,其是一个两阶段模型:前半部分Prior是给定文本生成一个image embedding(这个Prior产生的image embedding就是把CLIP的image embedding当作真值训练所得的。),后半部分decoder是以image embedding为条件生成图片。
模型架构如下:虚线上面部分是CLIP。虚线之下是我们文本到图像生成过程,一个CLIP text embedding输入到autoregressive或者扩散模型(prior部分)来生成一个image embedding,然后这个embedding输入到扩散模型decoder,生成最终的图像。CLIP部分在我们模型训练时是冻住的。
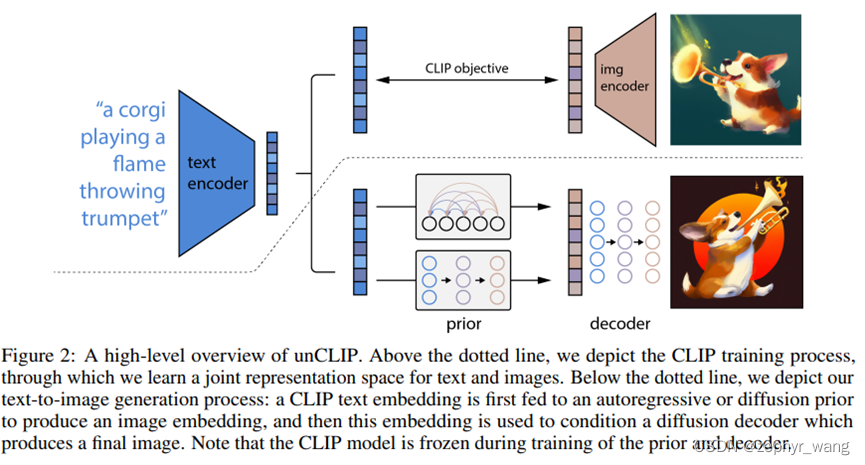
2 方法

2.1 Prior
Prior,我们探索了两种模型,Autoregressive (AR) 、Diffusion。发现Diffusion更好些。
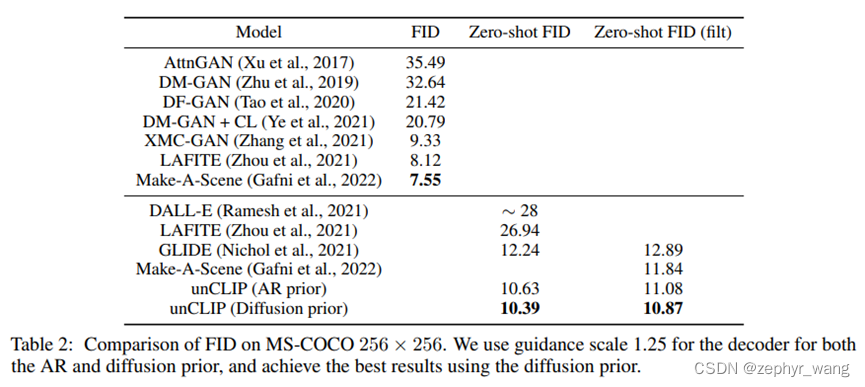
3 实验结果
FID比较图片相似的评分,越低越好。可以看到unCLIP在zero-shot中表现最好,同时Diffusion好过AR。
4 模型限制
1)在分割两个颜色的两个物体上有些困难,如下图左边。

2)容易混淆属性和物体,如下图

3)在连贯的文本(coherent text)上有困难,如下图

4)在复杂的场景下处理细节有困难。

5)生成的图片容易混淆原作,区分不出来。

















 1747
1747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









