







DALL-E是一个用于文字生成图片的模型,这也是一个很好思路的模型。该模型的训练分为两个阶段:
第一阶段:图片经过编码器编码为图片向量,当然我们应该注意这个过程存在无损压缩(图片假设200*200,如果用one-hot表示,我们还需要考虑通道,色彩表示,则其维度要达到200*200*(256^3),可以想象这个维度多高,经过编码器进行压缩编码,在进行解码器进行解码获取图片,不断训练,知道其误差极小,训练出一个较好的编码器和解码器。其损失函数是要考虑编码前图片和解码后图片的误差
第二阶段:文字通过GPT进行预测,不断训练使文字能够预测图片编码。
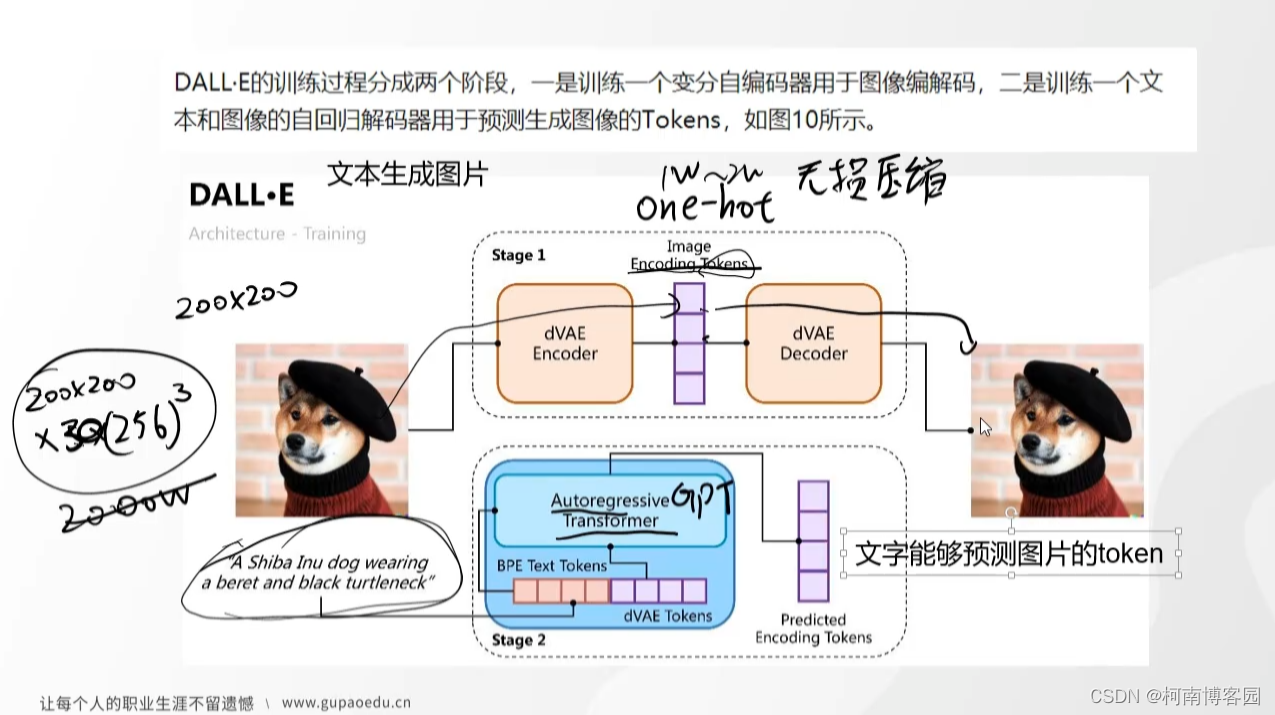
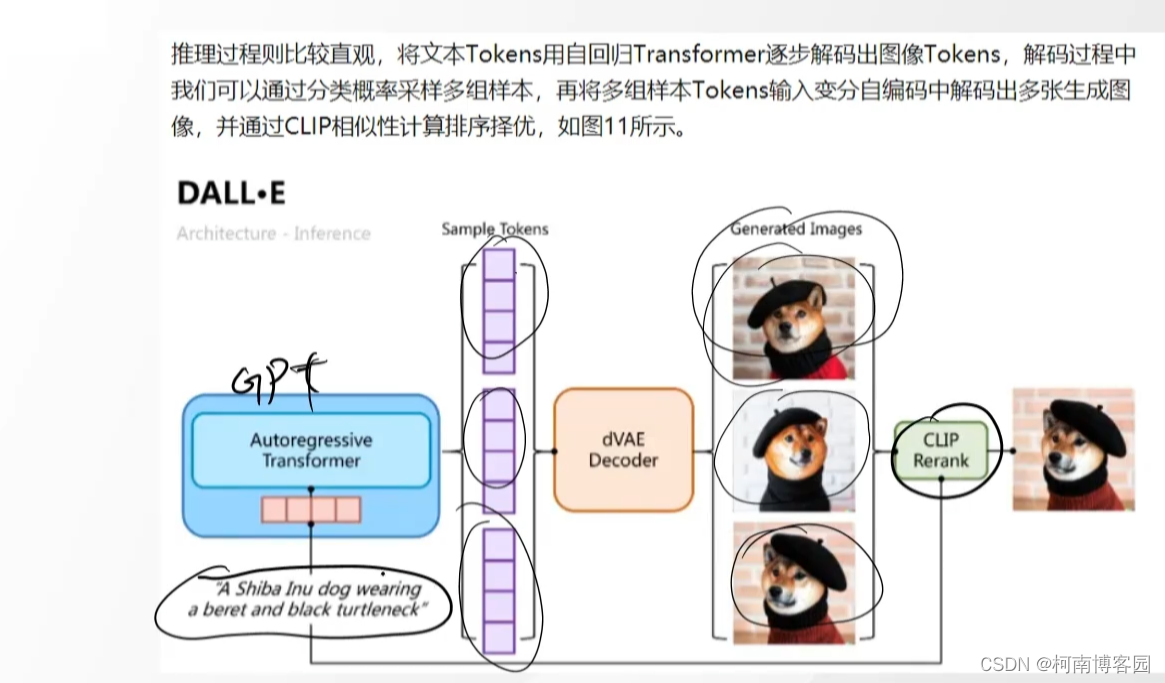
实现过程:文字进行GPT获取图片编码,图片编码经过解码器来获取图片,以实现文字生成图片。















 6099
6099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









