







项目场景:
遇到一个中文验证码,想到又是一个学习的机会,马上研究了下深度学习

解决过程
验证码包含干扰线、字体倾斜
一.干扰线
第一想法就是去除干扰线,搞了半天效果并不好,要么去掉干扰线同时将字体也去掉了部分,要么是干扰线去不掉,实在找不到办法去除,不过看到了一篇论文,有望去除:
一种通用的去除文字图像中干扰线的算法
不过我这边就不去研究了
在群里,大伙都说直接深度学习就行 不用去干扰线
二.使用cnn restnet18
根据大佬的推荐 使用这个进行训练,由于样本数量不够,模型不收敛。
目前有3W个样本 预计要10W+
由于未成功就不贴代码了
三.陷入迷茫
样本数不足,只能要么继续补充样本,要么换思路了。
补充样本自己人工打码,肯定不现实,又不想花钱找人打码,一切为了白嫖嘛
四.yolov5目标识别
突然诞生了一个想法,就是将这些扭曲的字 当作点选验证码进行识别,首先我有字的识别结果 但是没有定位,但是
定位只需要打几百张码就可以了,冲冲冲
用官方推荐的打码网站,这里打码我使用的roboflow网站
(可能需要科学上网一下比较快)这里我一共打了400左右的码,然后通过网站的export直接导出 放入yolov5里面直接开始跑
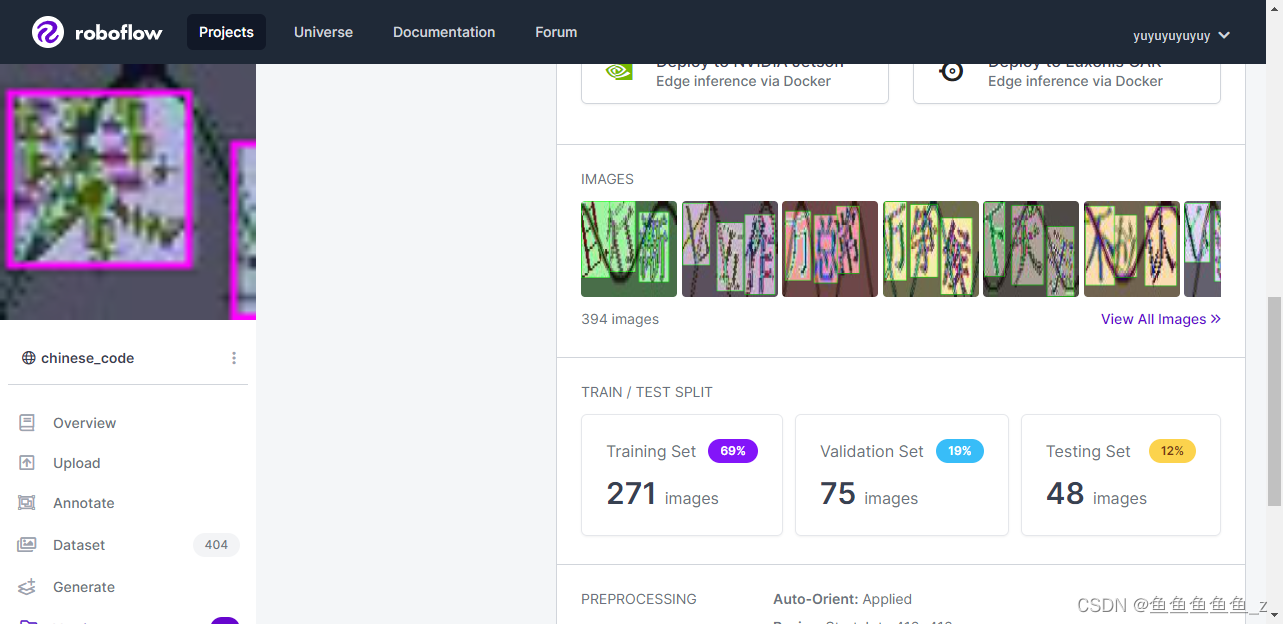
python train.py --data ./chinese_code/chinese_code.yaml --cfg yolov5l.yaml --weights yolov5l.pt --batch-size 4 --epochs 100

将导出的文件夹放入yolov5 文件夹下 执行
这里的 --weights 参数有 yolov5s m l x
因为我这里标注的样本较少我选择了一个收敛较慢 效果较好的yolov5l (个人理解 错误望指正)
这里模型跑完后 会在./runs/train/exp/weights/文件夹下生成best.pt 和last.pt
python detect.py --source D:\workSpace\PythonProject\chinese_YZM\picture\--weights ./runs/train/exp/weights/best.pt --data ./chinese_code/chinese_code.yaml --save-txt
然后这里我们直接用跑出来的pt 进行识别
运行之后会在./runs/detect/文件夹下面生成 一个文件夹
文件夹下面就是一个labels文件夹 以及所有识别的图片
0 0.460337 0.4375 0.300481 0.644231
0 0.725962 0.344952 0.317308 0.632212
0 0.151442 0.417067 0.293269 0.646635
这一串数字由空格隔开 每行有5个数字
第一个数字代表这个识别框的值
后面四个数字是这个框的坐标值
具体怎么算大家自行百度
然后我们根据detect 生成的结果 制作数据集
我们首先要去掉不合格的(识别出的内容不为3个的)
然后按照格式生成数据集
代码写的很差 涉及算法的都不会 大家见谅 菜就完了
#coding:utf-8
import random
import os
import shutil
"""
将用样本用标注训练集跑出来(仅标注了位置 未标注内容 样本数400)
然后将不合格的样本(目标检测数量不为3的)剔除
其他的放入数据集
再次进行训练 或直接用数据集直接进行识别结果
"""
b = ['理', '好', '她', '叫', '呼', '真', '或', '两', '长', '打', '种', '把', '十', '际', '根', '他', '笑', '面', '吧', '岸', '要', '怕', '白', '可', '像', '吗', '阵', '呀', '枪', '道', '夜', '员', '会', '进', '何', '动', '讲', '行', '听', '睡', '忽', '城', '特', '教', '旁', '地', '边', '古', '确', '岁', '说', '去', '爱', '未', '极', '音', '书', '没', '送', '叶', '代', '收', '各', '先', '平', '头', '整', '什', '因', '方', '离', '难', '命', '以', '明', '合', '脚', '拿', '更', '找', '往', '样', '星', '晚', '决', '比', '却', '革', '想', '为', '太', '便', '当', '义', '识', '河', '完', '赶', '个', '响', '活', '怎', '气', '沙', '块', '八', '拉', '掉', '术', '并', '件', '答', '了', '物', '只', '算', '色', '六', '记', '几', '该', '常', '相', '从', '这', '将', '叔', '四', '菜', '友', '住', '破', '候', '自', '本', '年', '细', '非', '眼', '然', '空', '等', '停', '类', '今', '声', '展', '研', '万', '很', '全', '政', '志', '再', '受', '屋', '树', '和', '又', '业', '指', '它', '轻', '成', '七', '中', '么', '着', '阶', '日', '信', '们', '般', '线', '事', '时', '法', '场', '且', '照', '敢', '快', '飞', '野', '次', '二', '话', '干', '提', '翅', '劳', '弟', '紧', '第', '由', '席', '应', '历', '伟', '土', '开', '人', '立', '告', '导', '我', '问', '女', '意', '冲', '关', '的', '运', '强', '被', '敌', '过', '片', '风', '落', '吃', '团', '睛', '内', '字', '共', '小', '所', '总', '雪', '领', '究', '子', '光', '身', '嘴', '取', '无', '放', '见', '争', '文', '围', '后', '建', '对', '读', '路', '顶', '包', '如', '三', '民', '使', '前', '兴', '也', '些', '哥', '界', '呢', '爬', '早', '钢', '坚', '南', '队', '帮', '火', '回', '都', '经', '雨', '而', '你', '众', '胜', '张', '给', '阳', '啊', '分', '饭', '唱', '连', '任', '北', '做', '房', '产', '深', '觉', '倒', '跳', '看', '百', '于', '已', '社', '体', '啦', '那', '您', '战', '装', '才', '林', '通', '之', '车', '热', '一', '草', '作', '海', '原', '科', '句', '画', '同', '近', '少', '量', '马', '走', '越', '青', '息', '利', '起', '题', '思', '急', '生', '似', '底', '半', '认', '忙', '其', '跑', '名', '者', '天', '加', '直', '山', '村', '门', '感', '里', '数', '东', '级', '渐', '是', '刻', '此', '哪', '接', '部', '九', '站', '史', '条', '月', '至', '系', '向', '穿', '船', '黑', '令', '咱', '写', '步', '切', '定', '结', '处', '但', '改', '观', '入', '世', '跟', '得', '果', '歌', '农', '大', '准', '带', '师', '千', '许', '压', '有', '木', '亮', '转', '国', '表', '外', '验', '报', '下', '乡', '传', '解', '反', '慢', '新', '苦', '工', '口', '群', '坐', '心', '清', '变', '性', '力', '己', '五', '够', '钱', '章', '情', '花', '不', '还', '军', '公', '老', '习', '学', '就', '主', '旧', '让', '服', '点', '形', '出', '在', '望', '知', '上', '治', '到', '家', '脸', '士', '度', '来', '办', '斗', '最', '亲', '牛', '满', '孩', '重', '背', '必', '论', '实', '儿', '刚', '机', '别', '位', '神', '谁', '用', '每', '衣', '发', '手', '流', '水', '多', '高', '现', '化', '造', '石', '座', '区']
def clear_dataset():
path = "../runs/detect/exp/labels/"
for i in os.listdir(path):
with open(f"{path}{i}","rb")as f:
a = f.read()
if a.count(b"\n") == 3:
#将数据集的值改变为汉字
bb = a.decode("utf-8")
c = bb.split("\r\n")
c0 = c[0].split(" ")[1]
c1 = c[1].split(" ")[1]
c2 = c[2].split(" ")[1]
end_c = ""
if c0 > c1 and c0 > c2:
end_c += c[0].replace("0 ", f"{b.index(i[2])} ") + "\n"
if c1 > c2:
end_c += c[1].replace("0 ", f"{b.index(i[1])} ") + "\n"
end_c += c[2].replace("0 ", f"{b.index(i[0])} ") + "\n"
else:
end_c += c[2].replace("0 ", f"{b.index(i[1])} ") + "\n"
end_c += c[1].replace("0 ", f"{b.index(i[0])} ") + "\n"
if c1 > c0 and c1 > c2:
end_c += c[1].replace("0 ", f"{b.index(i[2])} ") + "\n"
if c0 > c2:
end_c += c[0].replace("0 ", f"{b.index(i[1])} ") + "\n"
end_c += c[2].replace("0 ", f"{b.index(i[0])} ") + "\n"
else:
end_c += c[2].replace("0 ", f"{b.index(i[1])} ") + "\n"
end_c += c[0].replace("0 ", f"{b.index(i[0])} ") + "\n"
if c2 > c0 and c2 > c1:
end_c += c[2].replace("0 ", f"{b.index(i[2])} ") + "\n"
if c0 > c1:
end_c += c[0].replace("0 ", f"{b.index(i[1])} ") + "\n"
end_c += c[1].replace("0 ", f"{b.index(i[0])} ") + "\n"
else:
end_c += c[1].replace("0 ", f"{b.index(i[0])} ") + "\n"
end_c += c[0].replace("0 ", f"{b.index(i[1])} ") + "\n"
with open(f"{path.replace('labels','l1')}{i}","w",encoding="gbk")as f:
f.write(end_c)
dddd(i)
def create_file_notexist(file):
if not os.path.exists(file):
os.mkdir(file)
create_file_notexist("./chinese/valid/images/")
create_file_notexist("./chinese/valid/labels/")
create_file_notexist("./chinese/test/images/")
create_file_notexist("./chinese/test/labels/")
create_file_notexist("./chinese/train/images/")
create_file_notexist("./chinese/train/labels/")
#按照比例进行划分数据集
def dddd(i):
p1 = "D:/Download/416/"
print(f"{p1}{i}复制中")
random_num = random.randint(0,100)
if random_num > 80:
# shutil.copy(os.path.join(p1,"---"+i.split("_")[1].replace("txt","jpg")), f"./chinese/valid/images/{i.replace('txt','jpg')}")
shutil.copy(os.path.join(p1, i.replace("txt","jpg")), f"./chinese/valid/images/{i.replace('txt','jpg')}")
shutil.copy(f"./runs/detect/exp/l1/{i}", f"./chinese/valid/labels/{i}")
elif random_num > 75:
# shutil.copy(os.path.join(p1, "---"+i.split("_")[1].replace("txt", "jpg")), f"./chinese/test/images/{i.replace('txt', 'jpg')}")
shutil.copy(os.path.join(p1, i.replace("txt", "jpg")), f"./chinese/test/images/{i.replace('txt', 'jpg')}")
shutil.copy(f"./runs/detect/exp/l1/{i}", f"./chinese/test/labels/{i}")
else:
# shutil.copy(os.path.join(p1, "---"+i.split("_")[1].replace("txt", "jpg")), f"./chinese/train/images/{i.replace('txt', 'jpg')}")
shutil.copy(os.path.join(p1, i.replace("txt", "jpg")), f"./chinese/train/images/{i.replace('txt', 'jpg')}")
shutil.copy(f"./runs/detect/exp/l1/{i}", f"./chinese/train/labels/{i}")
if __name__ == '__main__':
clear_dataset()
对了图片记得resize一下,用roboflow生成的图片被改成416*416了
数据集生成后,我们用这数据集进行训练
修改一下yaml
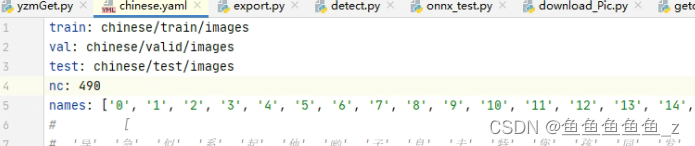
python train.py --data ./chinese/chinese.yaml --cfg yolov5l.yaml --weights yolov5l.pt --batch-size 4 --epochs 100
经过漫长时间训练后 最终终于识别了这个肉眼都不是很能看清楚的验证码
训练后怎么使用大家就自己想想办法把。。我写的代码太丑了就不放出来了

准确率应该达到了90以上 这里测试准确率97%
完结撒花
识别效果图

部署到cpu上识别速度大概是一张图0.5S,在3060ti上识别速度是0.1S
可能不该用这么复杂的算法,但是谁让我没有足够样本呢















 6567
6567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









