






一、搭建环境
anaconda:
labelImg:
anaconda的安装步骤以及添加环境变量不多说,安装完anaconda和添加完变量记得重启,然后打开anaconda prompt
然后在prompt里输入
conda create -n yolov5
yolov5是虚拟环境的名字,可随意
然后再输入conda env list即可查看目前所存在的虚拟环境有哪些

接着输入
conda activate yolov5
进入yolov5的虚拟环境,pip安装各类依赖库,建议换国内镜像源,会快很多
阿里云
http://mirrors.aliyun.com/pypi/simple/
中国科技大学
https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban)
http://pypi.douban.com/simple/
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学
http://pypi.mirrors.ustc.edu.cn/simple/
以安装numpy为例,用法是: pip install numpy -i ‘镜像源’,需要安装的各类库自己在站内搜吧,我搭建完了也没找到之前在哪看见的库,只在记忆中pip过这些库
beautifulsoup4 4.12.3
Cython 3.0.10
lxml 5.2.2
matplotlib 3.7.5
numpy 1.21.0
opencv-python 4.9.0.80
packaging 24.0
pandas 2.0.3
pycocotools 2.0.7
PyYAML 6.0.1
requests 2.32.2
seaborn 0.13.2
setuptools 70.0.0
tensorboard 2.14.0
tensorboard-data-server 0.7.2
thop 0.1.1
torch 2.2.0
torchaudio 2.2.0
torchvision 0.17.0
tqdm 4.66.4
wandb 0.17.0
注意,wandb这里我看站内有人说不下载也可以,但是我当时代码运行报错显示缺少了这个包,我还是下载了,这个包的安装使用比较麻烦,要注册也要秘钥,建议自己在站内找帖子解决
搭建完在prompt里输入 pip list 即可查看已安装的库,因为搭建环境比较简单,本人在搭建环境过程中没遇到过什么问题,所以这里不细说,搭建环境要注意的就是要下载visual C++ 2015 toolkit,站内有人说去官网下载,但是我去官网下载的包安装不了,显示损坏,这里建议大家去站内自己找包,我就是用的别人云盘里的vc toolkit,如果本机已经安装了visual studio,那么这步可以省略。

二、下载源码
去github官网下载yolov5的源码,网址:GitHub - ultralytics/yolov5 at v5.0YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.![]() https://github.com/ultralytics/yolov5/tree/v5.0注意,这里建议直接访问,方便后面下载预训练权重文件yolov5s.pt文件(打不开的话多打几次)
https://github.com/ultralytics/yolov5/tree/v5.0注意,这里建议直接访问,方便后面下载预训练权重文件yolov5s.pt文件(打不开的话多打几次)
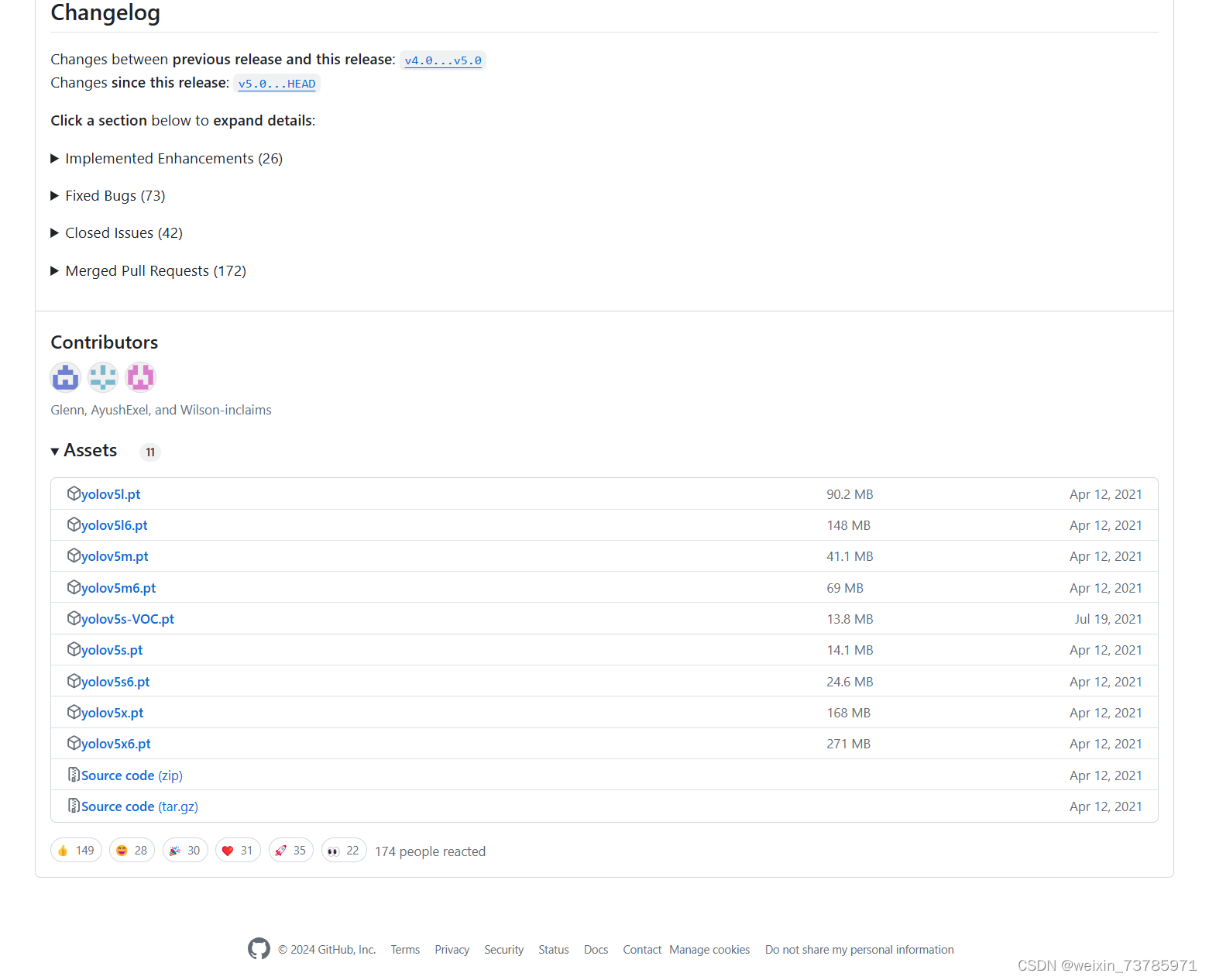
进去之后是这个页面,注意这里要看清楚是v5.0,然后点击右边的绿色图标code,然后download zip

下载完zip后点击 19branches 右边的那个 10Tags,向下拉找到 v5.0 ,然后点进去得到下面这个页面,向下拉找到yolov5s.pt,然后下载这个预训练权重文件

源码下载好之后,找到你存放源码的地方
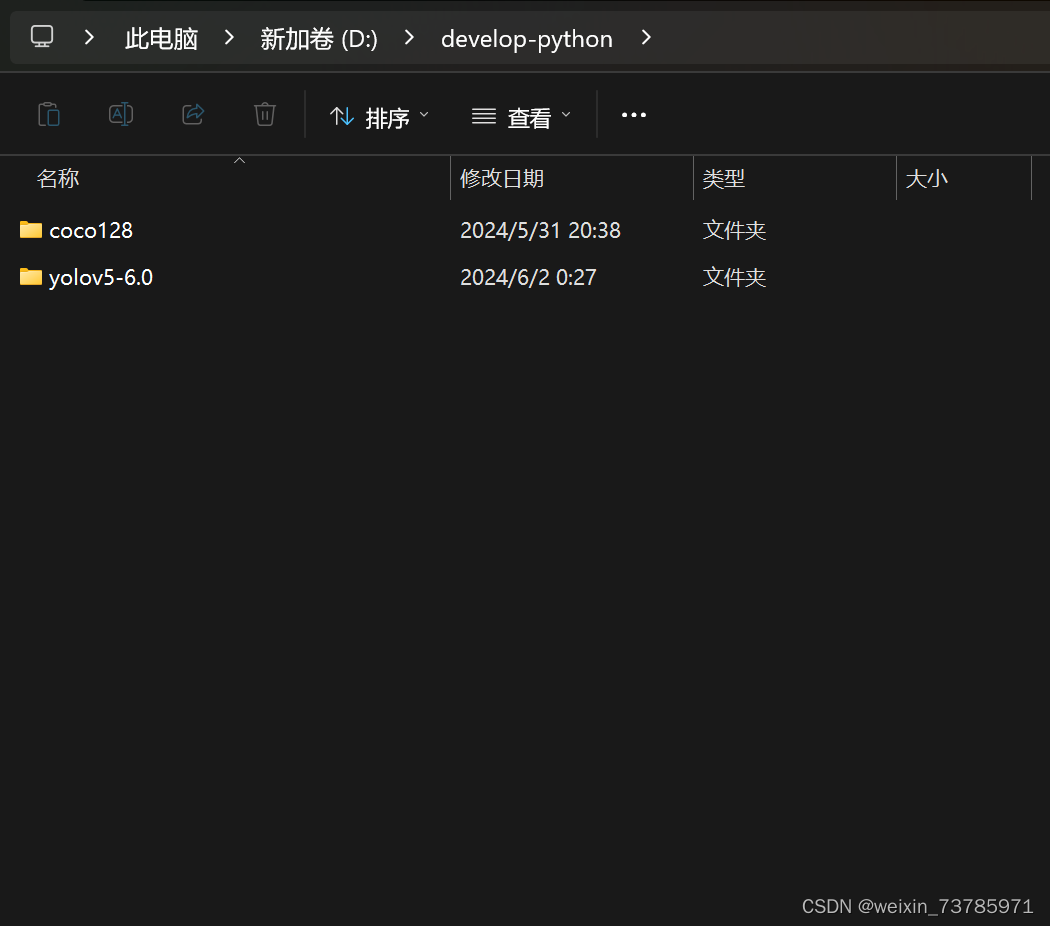
我这里是yolov5-6.0,把刚刚下载好的yolov5s.pt放到yolov5里(我的话就是放到了yolov5-6.0的根目录下)
 然后返回上一级目录(也就是develop-python这个目录),然后右键yolov5-6.0,用pycharm打开
然后返回上一级目录(也就是develop-python这个目录),然后右键yolov5-6.0,用pycharm打开
我已经跑过一次程序了所以打开之后是这样

然后点击左上角 file--setting,更换编译环境,因为我们是在前面搭建的conda环境里跑这个代码的,所以要更换编译环境

点击右上黄色字体add interpreter,左侧选择conda environment 按照路径找到conda.exe,点击use existing environment,选择我们刚刚搭建好的环境yolov5,然后一路点ok即可


已经切换好环境了,注意看看自己yolov5的根目录下有没有这个requirements.txt 文件,然后在terminal里输入命令安装需要的包
pip install -r requirements.txt
我已经安装过了所以显示的都是satisfied
下面讲讲训练集
在yolov5的根目录下建一个文件夹 dataset,然后在dataset里建三个文件夹 images,imagesets, annotations,然后在imagesets里新建一个文件夹main。images文件夹是存放未识别的jpg文件(也就是我们用来训练模型的原始图片)
 )
)
而annotations里存放的则是打过标签的xml文件

给jpg文件打标签,我用的是labelImg,这里注意,老老实实用labelImg,站内有人推荐用精灵标记助手,我就是用了这个导出来的xml文件有问题,代码一直读取不到数据,卡了我好久......在pycharm的terminal里输入下面这个命令,这里用的清华大学的镜像源,快很多
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple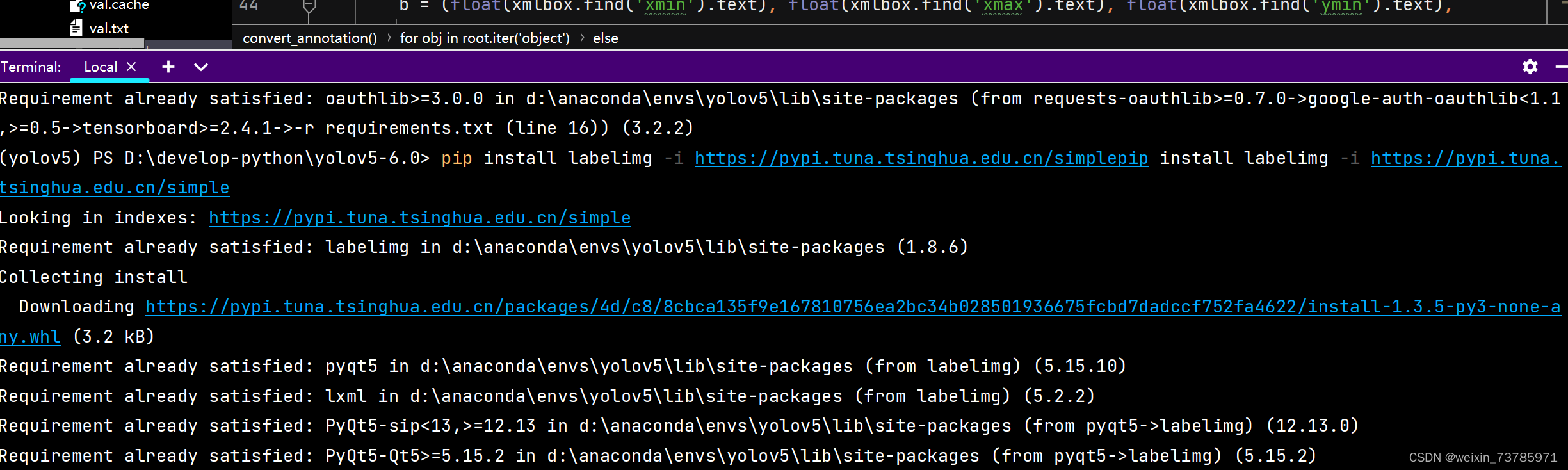
下载完之后,再输入labelImg即可打开labelImg

点击view 选中 autosave mode和display label,然后点击 open dir 打开你要标注的图片文件夹(也就是dataset下的images文件夹),然后点击change save dir,这个是用于选择导出xml文件的文件夹,可以切换其他导出格式,下图是pascalVoc,导出的是xml文件
标注如下图
使用:
按w呼出矩形框用来标记,按d是下一张,按a是上一张,因为前面已经打开了自动保存,那么annotations里会自动保存了xml文件。
讲讲代码的使用
在dataset文件夹中创建py代码split_train_val.py:
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在annotations下
parser.add_argument('--xml_path', default='annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='imagesets/main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
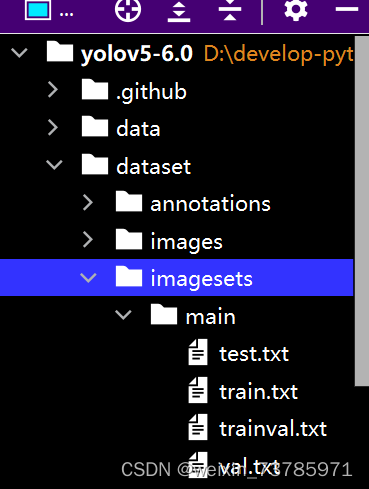
运行了上面这串代码之后,会在imagesets\main里生成四个文件
在dataset文件夹中新建py代码文件voc_label.py:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["bus"] # 改成自己的类别,我只用于识别bus所以只有一个标签
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
#修改自己电脑上对应文件目录,infile是打开xml文件的
in_file = open('D:/develop-python/yolov5-6.0/dataset/annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/develop-python/yolov5-6.0/dataset/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult')
if difficult is not None:
difficult = int(difficult.text) # 假设difficult是整数类型
else:
difficult = 0 # 或者你可以设置一个默认值,或者不处理difficult标签
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
#修改为自己电脑上对应目录
if not os.path.exists('D:/develop-python/yolov5-6.0/dataset/labels/'):
os.makedirs('D:/develop-python/yolov5-6.0/dataset/labels/')
image_ids = open('D:/develop-python/yolov5-6.0/dataset/imagesets/main/%s.txt' % (image_set)).read().strip().split()
list_file = open('D:/develop-python/yolov5-6.0/dataset/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '\images\%s.jpg\n' % (image_id))
convert_annotation(image_id)
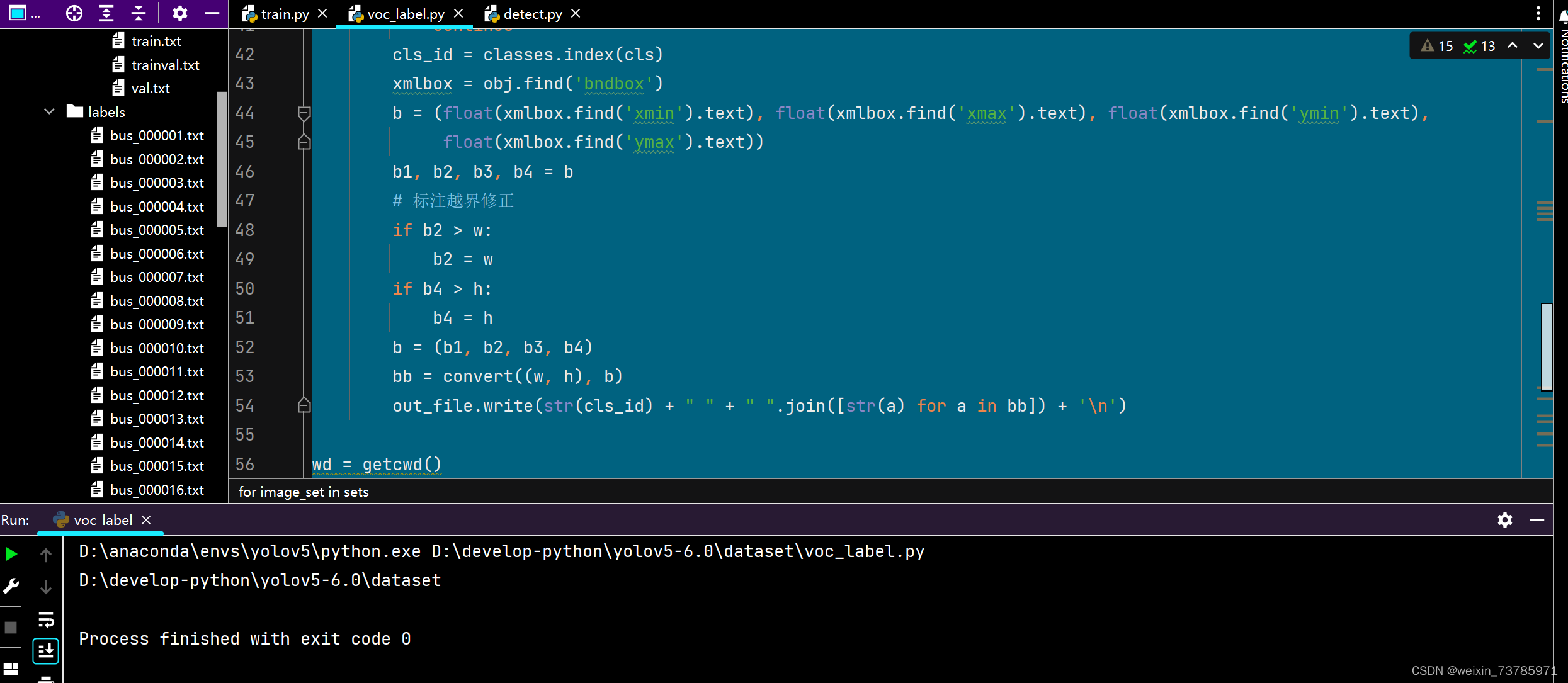
list_file.close()运行后dataset文件夹中会生成labels文件夹,以及三个txt文件:test.txt,train.txt,val.txt,如下图所示:

然后在data文件夹中新建CustomData.yaml:
train: D:\dev\yolov5-master\dataset\train.txt
val: D:\dev\yolov5-master\dataset\val.txt
# number of classes,有多少个标签就填多少个,我只有一个bus标签所以填1
nc:
# class names 我只有一个bus标签所以写bus
names: ['bus']
模型配置
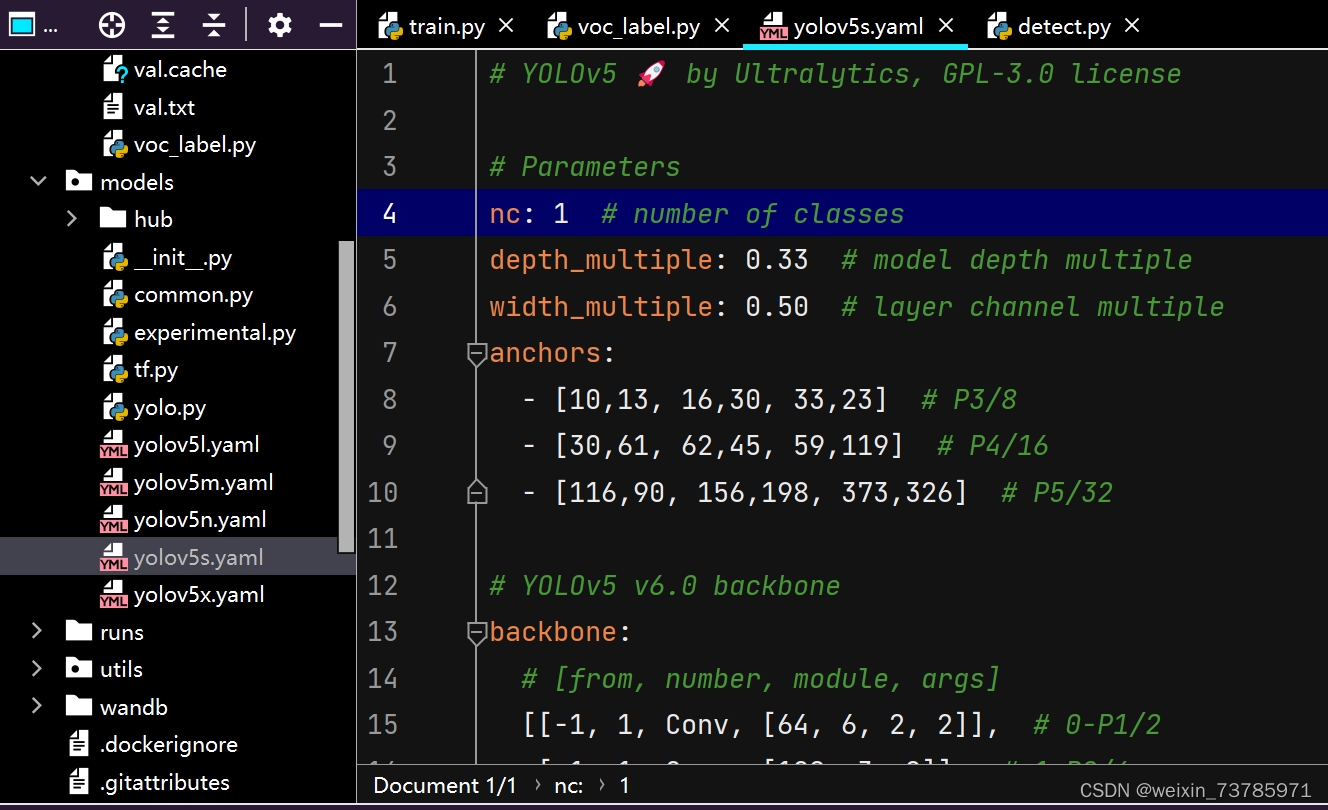
我们这里用yolov5s的模型(当然你用其他模型也可以),不同模型花的时间也不同,模型架构是按s,m,l,x。模型越大花的时间越长,这里选用yolov5s.yaml,只需修改一处,就是把nc改为你的标签数
到这一步,我们很快就可以开始训练模型了,这里讲讲train.py和detect.py
train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/CustomData.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
epochs:指的就是训练过程中整个数据集将被迭代多少次,默认是300次,次数越多模型越精准花的时间也越多
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch。
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片宽高。
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
bucket:gsutil bucket
cache-images:缓存图像以加快训练速度
weights:权重文件路径
name: 重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
我们需要修改的是weight 、cfg 、data。weight用的是我们前面下载的yolov5s.pt的权重文件,cfg用的就是yolov5s.yaml,data则用的是我们前编写的CustomData.yaml
detect.py
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT /'yolov5s.pt' , help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return optweights:训练的权重
source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
output:网络预测之后的图片/视频的保存路径
img-size:网络输入图片大小
conf-thres:置信度阈值
iou-thres:做nms的iou阈值
device:设置设备
view-img:是否展示预测之后的图片/视频,默认False
save-txt:是否将预测的框坐标以txt文件形式保存,默认False
classes:设置只保留某一部分类别,形如0或者0 2 3
agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
augment:推理的时候进行多尺度,翻转等操作(TTA)推理
update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
目前还不用修改这里的参数,后面训练完模型才修改权重文件。
可以开始训练了
运行train.py开始训练模型

出现这种页面,就说明已经开始训练了
注意的是,训练的时候比较吃内存,别手贱打开那么多页面什么的,不然会出现以下错误
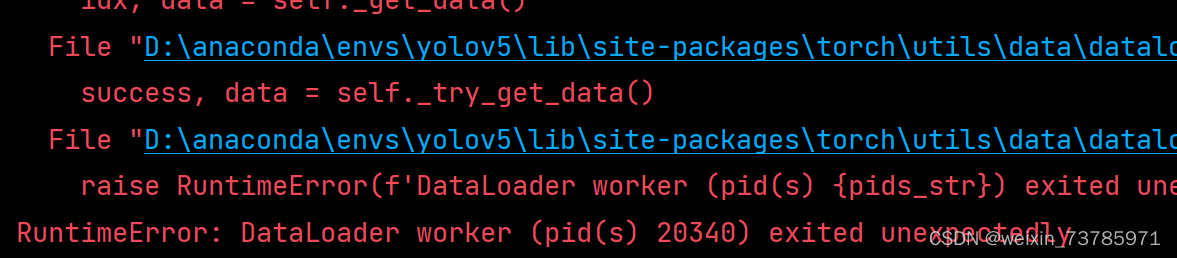
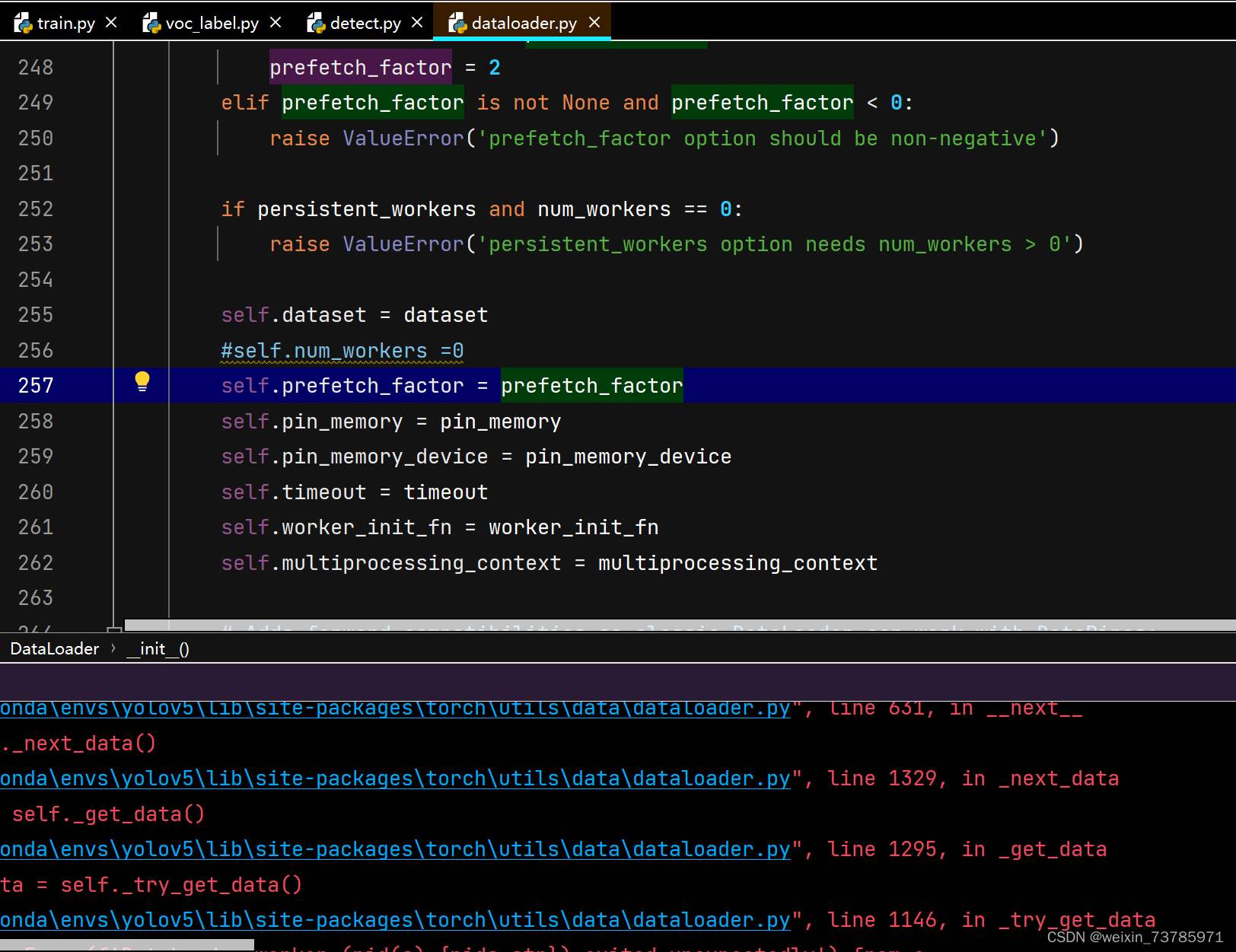
runtimeError是说明运行时间超时的意思,dataloader worker字面意思是装载工人,可以理解为工人数量太多了电脑内存不够,其实就是内存不够,这个num_workers是启用多线程的意思,我看了看站内的帖子,有的帖子说把num_workers 改成0就可以正常跑了,也就是下图(这个dataloader.py文件在安装目录:D:\anaconda\Anaconda3\Lib\site-packages\torch\utils\data\dataloader.py里)

原先这行代码是:num_workers = workers,现在改成num_workers=0,当然我这里是注释掉了,都可以,但是后面还是没跑起来,还是显示runtimeError
于是又去站内找办法,办法就是把虚拟内存扩大
点击高级系统设置--高级--性能--设置--高级--虚拟内存--更改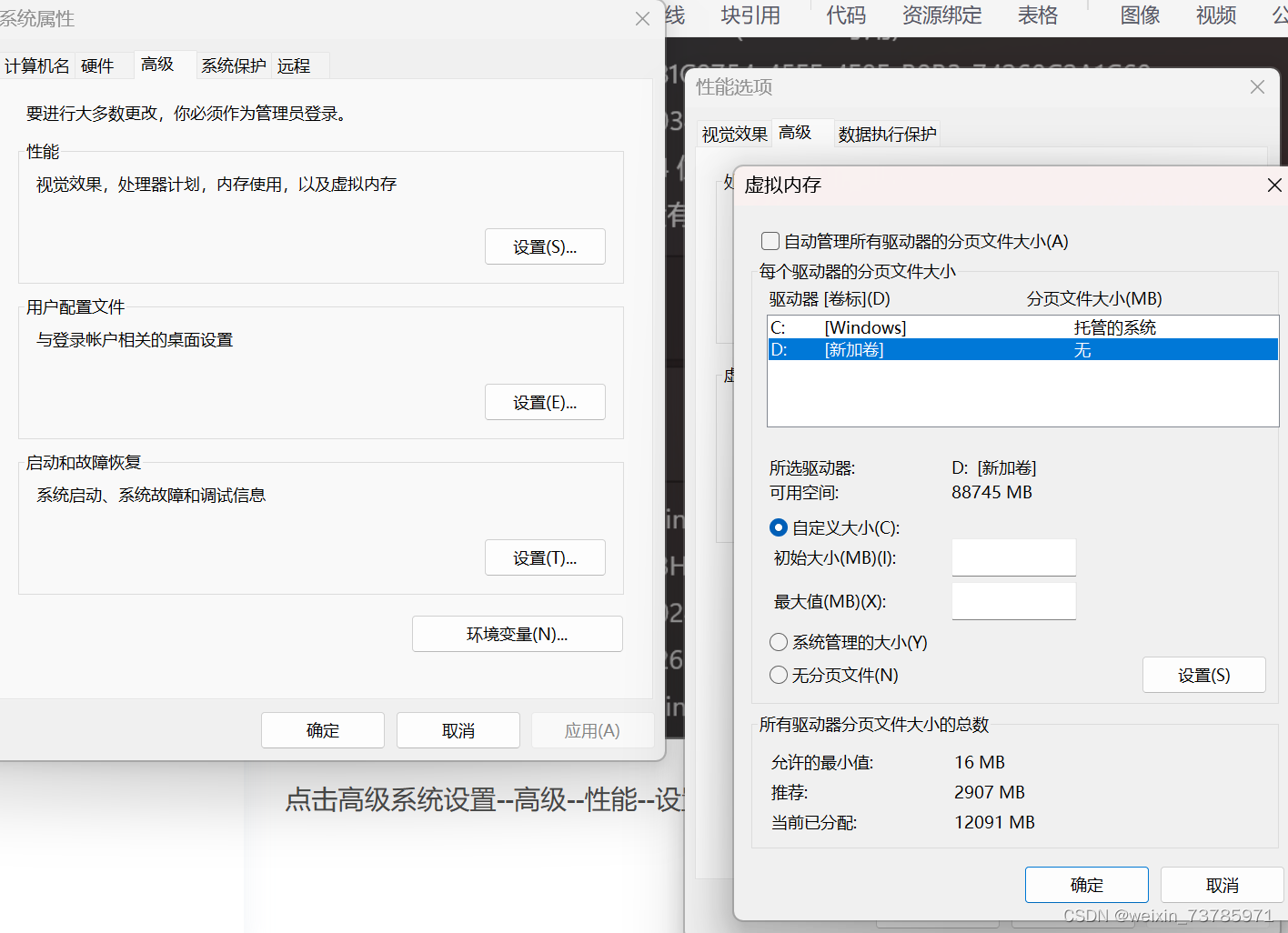
你的虚拟环境建在什么盘符,就选择那个盘,选择自定义大小,我最小给了1000m,最大给了2000m,然后一路点确定,修改完虚拟内存记得重启才能生效,然后再回去运行train.py即可
这里附上跑程序的图
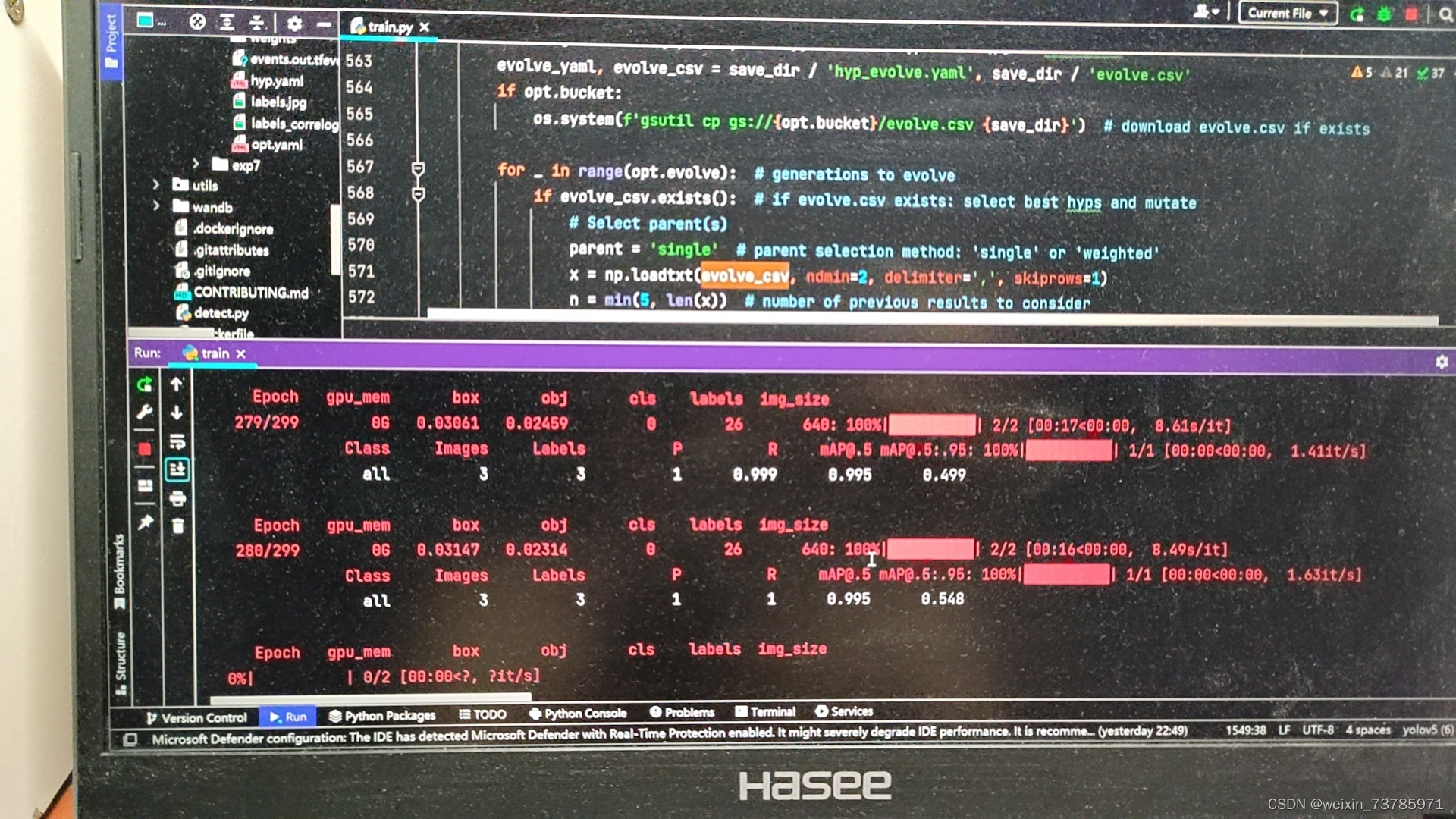
跑完之后,会在runs/train/exp/weights/下生成.pt文件,这个best.pt文件就是我们训练出来的权重文件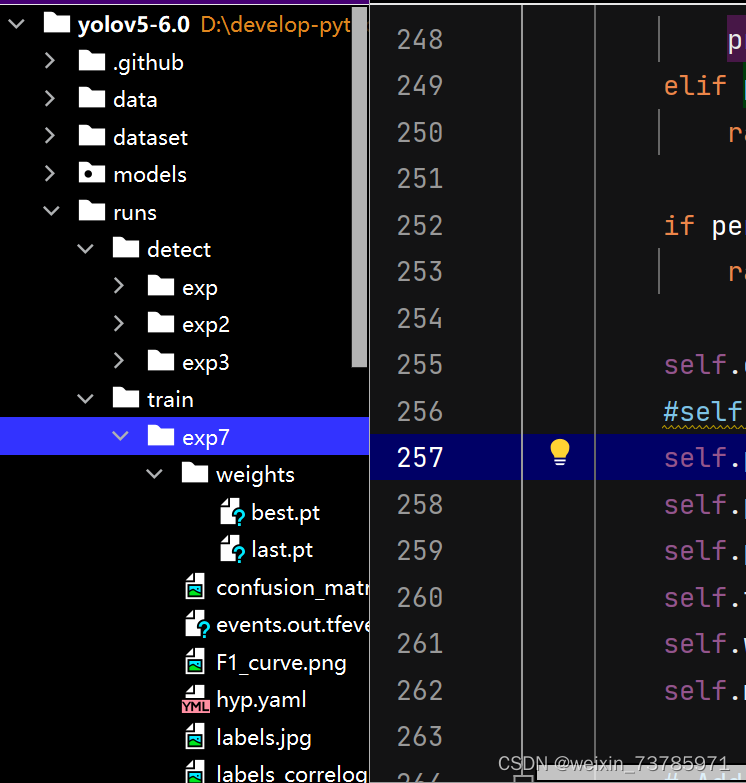
好了,然后再回去detect.py文件里,把权重文件换成我们自己训练的权重文件
 也就是weights这一行改成自己训练的权重文件的路径即可,把自己要检测的文件放到data/images里,然后运行detect.py即可开始识别所得结果会放在runs/detect文件夹内
也就是weights这一行改成自己训练的权重文件的路径即可,把自己要检测的文件放到data/images里,然后运行detect.py即可开始识别所得结果会放在runs/detect文件夹内
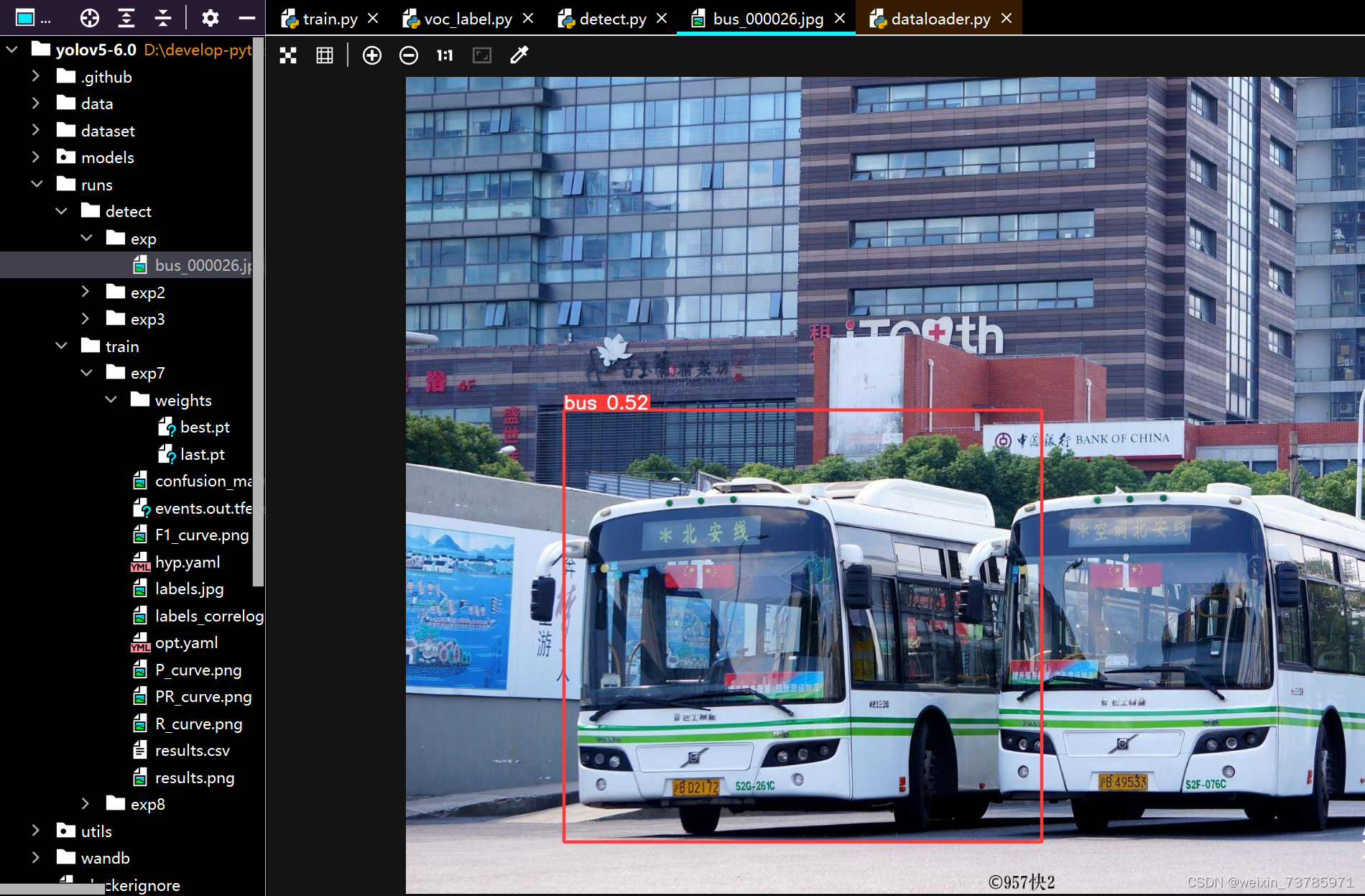
大功告成!















 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









