









1 文本分类概述
1.1 简介
给定文本D,将文本分类为预定义的N个类别中的一个或多个。
1.2 任务
根据文本的长度,可以分为:
- 短文本分类
- 长文本分类
根据标签,可以分为:
- 单标签分类
- 多标签分类
- 层次多标签分类
1.3 常用方法
可以分为传统机器学习和深度学习方法两类,主要区别在于传统机器学习方法需要额外的特征工程构建特征,深度学习方法直接使用神经网络提取特征。提取特征后把特征输入到分类器,得到输出。
1.4 常用数据集
1)英文数据集:
MR:影评数据,共有正面、负面两个类别。
SST-1/2:MR的扩展,对数据集进行了切分,标签更加精细,共有非常积极、积极、中性、消极、非常消极五个类别。
20News:新闻数据,共有四个类别。
Yelp:耶鲁大学数据集,分为五个类别。
IMDB:影评数据,共有十个类别。
Yahoo Answer:话题分类,共有十个类别。
Amazon:评价数据,共有五个类别。
AG:新闻数据,共有四个类别。
2)中文数据集
Fudan:复旦大学数据集,共有二十个类别。
Sogou:新闻数据,共有五个类别。
1.5 效果测评
一般采用精确率(precision)、召回率 (recall)和F1值进行测评。
2 论文笔记
================================================================================================
ACL 2014:Convolutional Neural Networks for Sentence Classification
================================================================================================

概述
文本针对基于词向量和卷积神经网络(CNN)的模型架构,在文本分类任务上做了一系列实验。
模型架构
设长度为n的句子的词向量表示为![]() 。
。
对于单个卷积核,使用该卷积核对单词![]() 及其周边单词的词向量进行一维卷积得到特征
及其周边单词的词向量进行一维卷积得到特征![]() 。得到某个卷积核对于该句子的特征
。得到某个卷积核对于该句子的特征![]() ,其中h是卷积核的大小。然后进行max pooling,得到该卷积核的输出
,其中h是卷积核的大小。然后进行max pooling,得到该卷积核的输出![]() 。当有多种类型的词向量时(如随机初始化的、预训练的),首先分别对各种词向量提取特征,然后把得到的特征相加。
。当有多种类型的词向量时(如随机初始化的、预训练的),首先分别对各种词向量提取特征,然后把得到的特征相加。
使用多个卷积核重复以上操作,可以得到一系列卷积核的输出,然后把所有输出拼接得到一个向量,并使用dropout进行正则化,最后输入到一个全连接层,再经过softmax,得到最终输出。
实验结果
本文分别测试四种方式的词向量的效果:
- 1)rand:随机初始化;
- 2)static:预训练并固定权重;
- 3)non-static:预训练并微调;
- 4)multichannel:两个通道的预训练词向量,一个固定,一个微调;

================================================================================================
AAAI 2015:Recurrent Convolutional Neural Networks for Text Classification
================================================================================================

概述
之前的文本分类模型依赖人工特征,本文提出一种不依赖人工设计特征的神经网络。模型采用RNN获取每个词的上下文信息,结合最大池化,自动捕获文本中的关键信息。
模型架构
设输入为由一系列词![]() 组成的文档
组成的文档![]() ,输出为
,输出为![]() 。
。
1)词表示
每个词的表示由该词的词向量、左上下文向量、右上下文向量三部分拼接组成:
![]()

然后通过线性变换,得到该词的最终表示:
![]()
其中词向量通过无标注文本预训练得到。
2)句子表示
对组成句子的所有词进行最大池化,得到该句子的表示:
![]()
然后对句子表示进行一次线性变换,并输入到softmax,得到最终输出:
![]()

实验结果


================================================================================================
NAACL 2016:Hierarchical Attention Networks for Document Classification
================================================================================================

概述
本文提出一个用于文档分类的层次注意力模型,模型对单词和句子两个层次使用注意力机制,对应提取文档的层次结构信息。
由于文档具有层次结构(单词构成句子,句子构成文档),本模型同样首先构建句子的表示,然后再将它们聚合成文档的表示。注意力机制可以用于提取每个单词和句子的重要性信息。
模型架构
设文档有![]() 个句子
个句子![]() 组成,每个句子包含
组成,每个句子包含![]() 个单词,
个单词,![]() 表示第i个句子中的第t个单词,
表示第i个句子中的第t个单词,![]() 。
。
1)句子表示
对于每个句子,首先把单词转换成词向量,然后使用双向GRU提取每个单词的上下文表示:

![]()
然后计算各个单词的注意力权重,最后结合单词的上下文表示和注意力权重,得到句子表示![]() :
:

2)文档表示
同理,首先使用双向GRU提取每个句子的上下文表示:

![]()
然后计算各个句子的注意力权重,最后结合句子的上下文表示和注意力权重,得到文档表示![]() :
:

3)文本分类
最后使用softmax得到分类结果:
![]()
损失函数使用负对数似然:
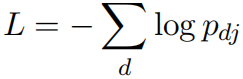
实验结果

================================================================================================
EACL 2017:Bag of Tricks for Efficient Text Classification
================================================================================================

概述
本文提出一个简单高效的文本分类器。在标准的多核CPU环境下,可以在不到十分钟的时间内训练超过10亿个单词,并在不到一分钟的时间内将50万个句子从312K个类中分类出来。
模型架构
首先把n-gram特征通过矩阵A转换成词向量,然后对所有的词向量取平均,转换成句子向量。然后把句子向量输入到一个线性分类器(乘以矩阵B),并通过softmax得到最后的分类结果。

1)Hierarchical softmax
当目标类别数量很多时,线性分类器的计算量很大,计算复杂度为![]() ,其中K是目标类别数量,h是隐藏层的维度。 为了提升运行效率,本文使用基于霍夫曼编码树的分层softmax,计算复杂度降至
,其中K是目标类别数量,h是隐藏层的维度。 为了提升运行效率,本文使用基于霍夫曼编码树的分层softmax,计算复杂度降至![]() 。
。
2)N-gram特征
词袋模型无法反映词序信息,本文使用n-gram特征作为辅助来捕获词序信息。
实验结果
1)情感分析



2)标签预测

================================================================================================
ACL 2017:Deep Pyramid Convolutional Neural Networks for Text Categorization
================================================================================================

概述
本文提出了一种用于文本分类的低计算复杂度的基于词级别的深度卷积神经网络结构,该结构能够有效地捕获文本中的长距离关联。相对于之前基于字级别的模型,虽然词级别的模型需要考虑规模更大的字典,但是其实只需要包含3万个常用词的字典就可以达到很好的效果。本文提出的模型可以在增加深度的情况下不增加计算复杂度,模型由卷积模块和下采样层堆叠组成,由于每次下采样都会让输入长度缩短一半,所以总的计算复杂度不会超过第一个卷积模块2倍。同时下采样也让模型更容易捕获长距离依赖。
模型架构
模型由Text region embedding、卷积块(两个卷积层加上短路连接)、下采样几部分组成。
1)Text region embedding
本文提出Text region embedding,对一个文本区域中的一个或者多个词进行embedding映射。对于每个词,通过![]() 计算region embedding,其中
计算region embedding,其中![]() 是词的及其周边词组成的区域表示。设
是词的及其周边词组成的区域表示。设![]() 是词典大小,
是词典大小,![]() 表示区域的窗口大小。这里分别考虑三种区域的表示形式:1)k个词的one-hot编码的拼接;2)v维的bag-of-word向量表示;3)包含n-gram的bag-of-word向量表示,这里考虑unigram,bigram,trigram三种。当k等于1时,退化成词向量。实验证明,第一种表示形式效果不好,第二种形式效果在不预训练的情况下效果最好,第三种形式在结合预训练的情况下效果最好。
表示区域的窗口大小。这里分别考虑三种区域的表示形式:1)k个词的one-hot编码的拼接;2)v维的bag-of-word向量表示;3)包含n-gram的bag-of-word向量表示,这里考虑unigram,bigram,trigram三种。当k等于1时,退化成词向量。实验证明,第一种表示形式效果不好,第二种形式效果在不预训练的情况下效果最好,第三种形式在结合预训练的情况下效果最好。
基于tv-embedding(tv表示two views)使用无监督学习对Text region embedding进行预训练,目标区域为view-1,其他区域为view-2。基于无标注数据,和传统的词向量训练方式类似。
本文针对多种区域大小和多种区域表示训练多个Text region embedding,得到多个![]() 。使用时,使用随机初始化的第二种形式的区域表示,加上多个预训练的Text region embedding的结果的求和,得到最终表示:
。使用时,使用随机初始化的第二种形式的区域表示,加上多个预训练的Text region embedding的结果的求和,得到最终表示:
![]()
![]()
Text region embedding后紧跟的是多个重复的卷积块和下采样的组合。
2)卷积块(短路连接、预激活)
在卷积块中使用短路连接,实现对深度网络的训练。设卷积块的输入为![]() ,则输出表示为
,则输出表示为![]() 。由于本模型的下采样在卷积块外,避免维度不匹配的问题,不需要额外的参数进行维度映射,整个网络会比较简单而且计算高效。
。由于本模型的下采样在卷积块外,避免维度不匹配的问题,不需要额外的参数进行维度映射,整个网络会比较简单而且计算高效。
实验发现,在卷积块中使用预激活效果更好。传统卷积计算方式为![]()
![]() ,预激活的计算方式为
,预激活的计算方式为![]() ,本文选择ReLU作为激活函数
,本文选择ReLU作为激活函数![]() 。
。
3)固定feature maps数量的下采样
在每个卷积块后面,使用宽度为3步长为2的最大池化,池化的输入长度为原来的一半。传统的池化会增加feature maps数量的数量,本文发现,增加feature maps数量增加了计算复杂度,但是对性能没有太大提升,所以选择固定feature maps的数量。
基于上述操作,模型能够保证总的计算计算复杂度等于第一层卷积块计算时间的两倍,而且可以不断使卷积块的效覆范围加倍,经过L次下采样操作后,卷积块可以提取相邻2L个输入之间的特征。所以模型可以在不增加计算复杂度的基础上,更好的捕获长距离的依赖关系。
实验结果


特征分析




================================================================================================
AAAI 2019:Graph Convolutional Networks for Text Classification
================================================================================================

概述
基于CNN和RNN的模型可以有效提取词的局部特征和顺序特征,但是无法很好的提取词与词之间、词和文档之间的全局特征。本文研究使用图神经网络进行文本分类,首先基于词共现、文档与词的关系把语料库转换为图,然后使用GCN提取特征,然后通过对节点进行分类实现文本分类。模型在少量标注数据的情况下仍然可以实现较好的分类表现,并且在学习文本分类的同时可以学习到词和文档向量。
模型架构
设图为![]() ,输入为
,输入为![]() ,其中n是节点的数量,m是特征的维度。
,其中n是节点的数量,m是特征的维度。![]() 为
为![]() 的邻接矩阵,
的邻接矩阵,![]() 为
为![]() 的度矩阵。
的度矩阵。
GCN每一层的计算方式为![]() ,其中
,其中![]() ,
,![]() 。
。
本文构建的图的节点包含词节点和文档节点两种,输入![]() 为词和文档的one-hot向量。边为词与文档的关系信息、词与词的共现信息,文档节点和词节点之间的边的权重为TF-IDF,词节点之间的边的权重为PMI。则邻接矩阵表示为:
为词和文档的one-hot向量。边为词与文档的关系信息、词与词的共现信息,文档节点和词节点之间的边的权重为TF-IDF,词节点之间的边的权重为PMI。则邻接矩阵表示为:

PMI的计算方式如下:

其中![]() 为词i出现在滑动窗口内的次数、
为词i出现在滑动窗口内的次数、![]() 为词i、j同时出现在滑动窗口内的次数、
为词i、j同时出现在滑动窗口内的次数、![]() 为滑动窗口的个数,只保留PMI为正的边。
为滑动窗口的个数,只保留PMI为正的边。
使用两层GCN提取特征:
![]()
损失函数为:

其中![]() 为带标签的文本节点,
为带标签的文本节点,![]() 为标签类别总数。
为标签类别总数。
实验结果

特征分析


















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









