







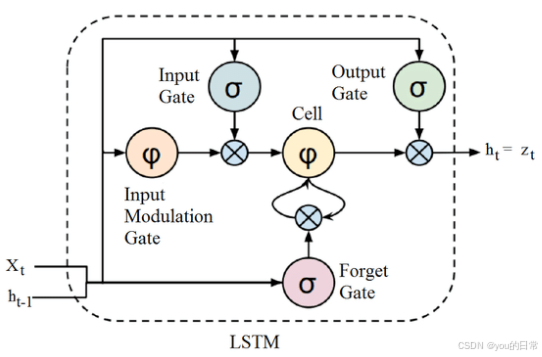
LSTM(长短期记忆网络)作为深度学习领域处理序列数据的革命性架构,通过创新性的门控机制解决了传统RNN模型的梯度消失问题,实现了对长距离依赖关系的有效建模。
其核心设计包含细胞状态和三个门控结构(遗忘门、输入门和输出门),这些组件协同工作,使LSTM能够在处理时间序列数据时既保持短期信息又保留长期记忆。
自1997年由Sepp Hochreiter和Jürgen Schmidhuber提出以来,LSTM已成为自然语言处理、时间序列预测等领域的基础模型,并衍生出多种变体,如GRU(门控循环单元)和Bi-LSTM(双向LSTM),进一步扩展了其应用范围。
一、LSTM的基本架构与工作原理
LSTM的核心结构由细胞状态(Cell State)和三个门控结构组成,这一架构设计使其能够有效处理长序列数据。细胞状态是贯穿整个LSTM单元的"记忆通道",通过线性操作(主要是加法)传递信息,避免了传统RNN中因非线性激活函数导致的梯度消失问题。在每个时间步,细胞状态会根据当前输入和上一时刻的隐藏状态进行更新,但更新过程受到三个门控结构的严格控制。
LSTM的三个门控结构各司其职,共同构成了其独特的信息筛选机制:
**遗忘门(Forget Gate)**负责决定哪些信息应该从细胞状态中被丢弃。它通过一个逻辑回归层(Sigmoid函数)生成一个介于0和1之间的向量,其中每个元素代表细胞状态中对应信息的保留权重。当某个位置的遗忘门值接近1时,表示保留该位置的旧信息;接近0则表示遗忘该信息。遗忘门的计算公式为:
f_t = σ(W_f ⋅ [h_{t-1}, x_t] + b_f)
**输入门(Input Gate)**控制新输入信息如何被写入细胞状态。它包含两个部分:一个Sigmoid层决定哪些值将要更新,以及一个Tanh层创建新的候选值向量。
输入门的计算公式为:
i_t = σ(W_i ⋅ [h_{t-1}, x_t] + b_i)
\tilde{c}_t = tanh(W_c ⋅ [h_{t-1}, x_t] + b_c)
**输出门(Output Gate)**决定细胞状态中的哪些信息将传递给隐藏状态,并最终输出。输出门通过Sigmoid函数生成一个权重向量,然后与Tanh激活的细胞状态进行逐元素乘法。输出门的计算公式为:
o_t = σ(W_o ⋅ [h_{t-1}, x_t] + b_o)
h_t = o_t ⊙ tanh(c_t)
细胞状态更新是LSTM最核心的操作,其公式为:
c_t = f_t ⊙ c_{t-1} + i_t ⊙ \tilde{c}_t
这一公式表明,当前时间步的细胞状态由两部分组成:一部分是通过遗忘门保留的旧细胞状态信息,另一部分是通过输入门筛选并添加的新信息。这种线性加法操作使细胞状态能够在长序列中稳定传递信息,成为LSTM解决梯度消失问题的关键创新。
二、门控机制的数学原理与梯度控制
LSTM的门控机制之所以能有效解决梯度消失问题,关键在于其独特的数学设计。每个门控结构都通过Sigmoid函数生成一个权重向量(0-1之间的值),然后通过逐元素乘法(Hadamard乘积)与相关向量结合,这种机制允许LSTM在反向传播过程中保持梯度的稳定流动。
遗忘门的Sigmoid输出决定了旧细胞状态c_{t-1}的保留比例。在反向传播时,遗忘门的梯度链会乘以f_t的导数,而Sigmoid函数的导数σ’(x)=σ(x)(1-σ(x))在0.25左右时达到最大值,这有助于保持梯度的规模。当LSTM需要保留长期信息时,遗忘门的输出会接近1,此时σ’(f_t)≈0.25,保证了梯度在反向传播时不会被过度衰减。
输入门的Sigmoid输出i_t控制新信息\tilde{c}_t的添加量。输入门与Tanh层结合,Tanh函数的导数tanh’(x)=1-tanh²(x)在输入为0时达到最大值1,这使得输入门在添加新信息时能够保持梯度的稳定性。当LSTM需要记住新信息时&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









