







零碎知识点
6.6日
1.copy() 复制
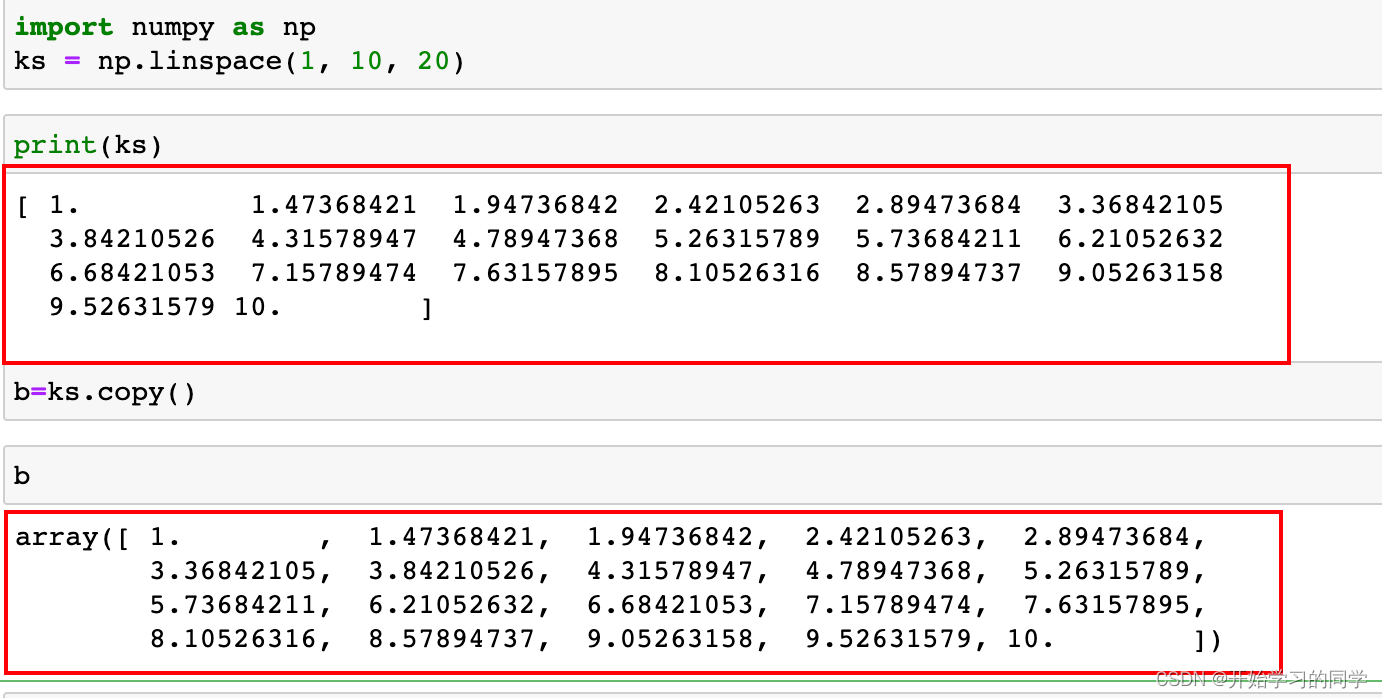
2.drop() 删除
首先import pandas as pd----pandas中的函数
drop([ ],axis=0,inplace=True)
针对索引进行删除
-
1.drop([行]),删除行, 默认情况下删除某一行;
-
2.如果要删除某列,需要axis=1;
-
3.参数inplace:默认情况下为False,表示保持原来的数据不变,True 则表示在原来的数据上改变;
没有带columns,所以要指出是哪个轴上的,需要axis参数
带有columns,所以不用加上axis参数
- 1和2合并举例
adult_data = adult.copy().drop(columns=[‘Name’, ‘SSN’])
1.原来的adult数据集样子

2.运行“ adult_data = adult.copy().drop(columns=[‘Name’, ‘SSN’])”

3.merge()
首先需要引入pandas函数
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=(‘_x’, ‘_y’), copy=True, indicator=False,
validate=None)
how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
left: 拼接的左侧DataFrame对象
right: 拼接的右侧DataFrame对象
on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
right_index: 与left_index功能相似。
how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)。
copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
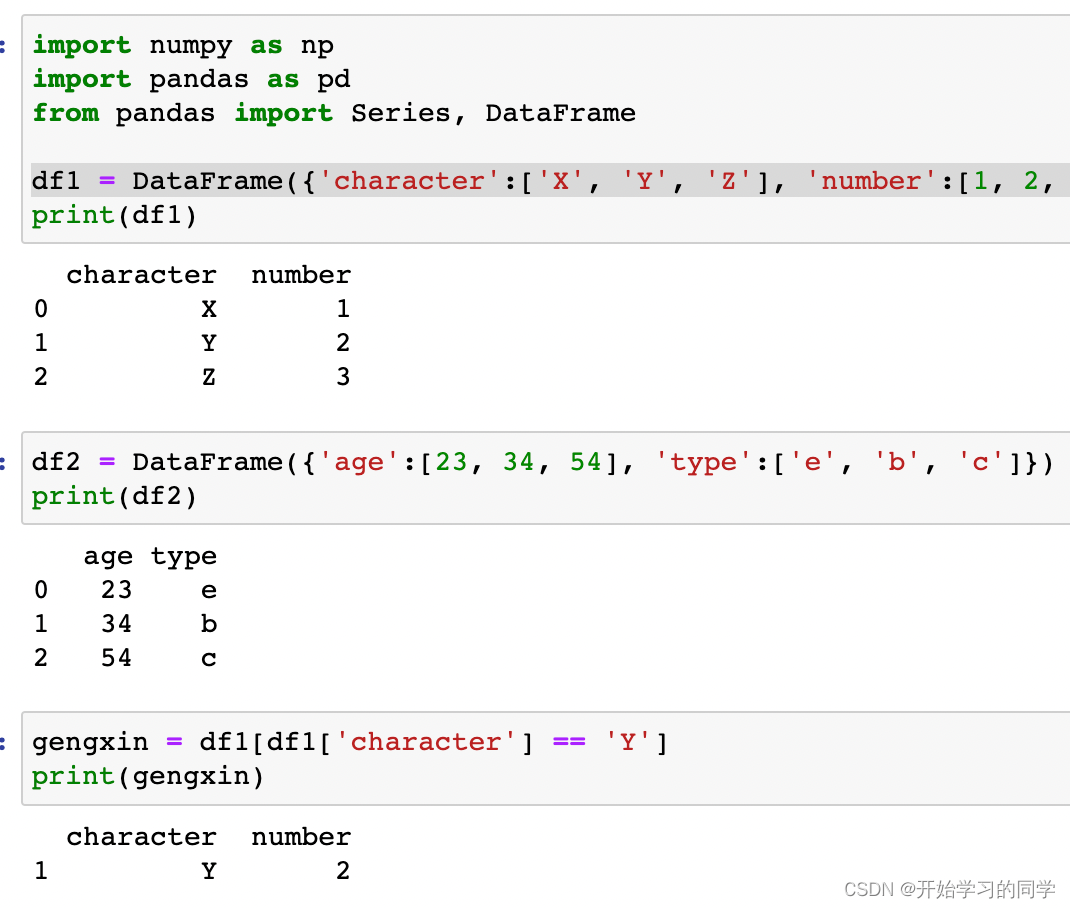
df1 = DataFrame({'character':['X', 'Y', 'Z'], 'number':[1, 2, 3]}) #列:值,列:值,.....
print(df1)

链接两个数据集需要共同索引列或行;
6.7日
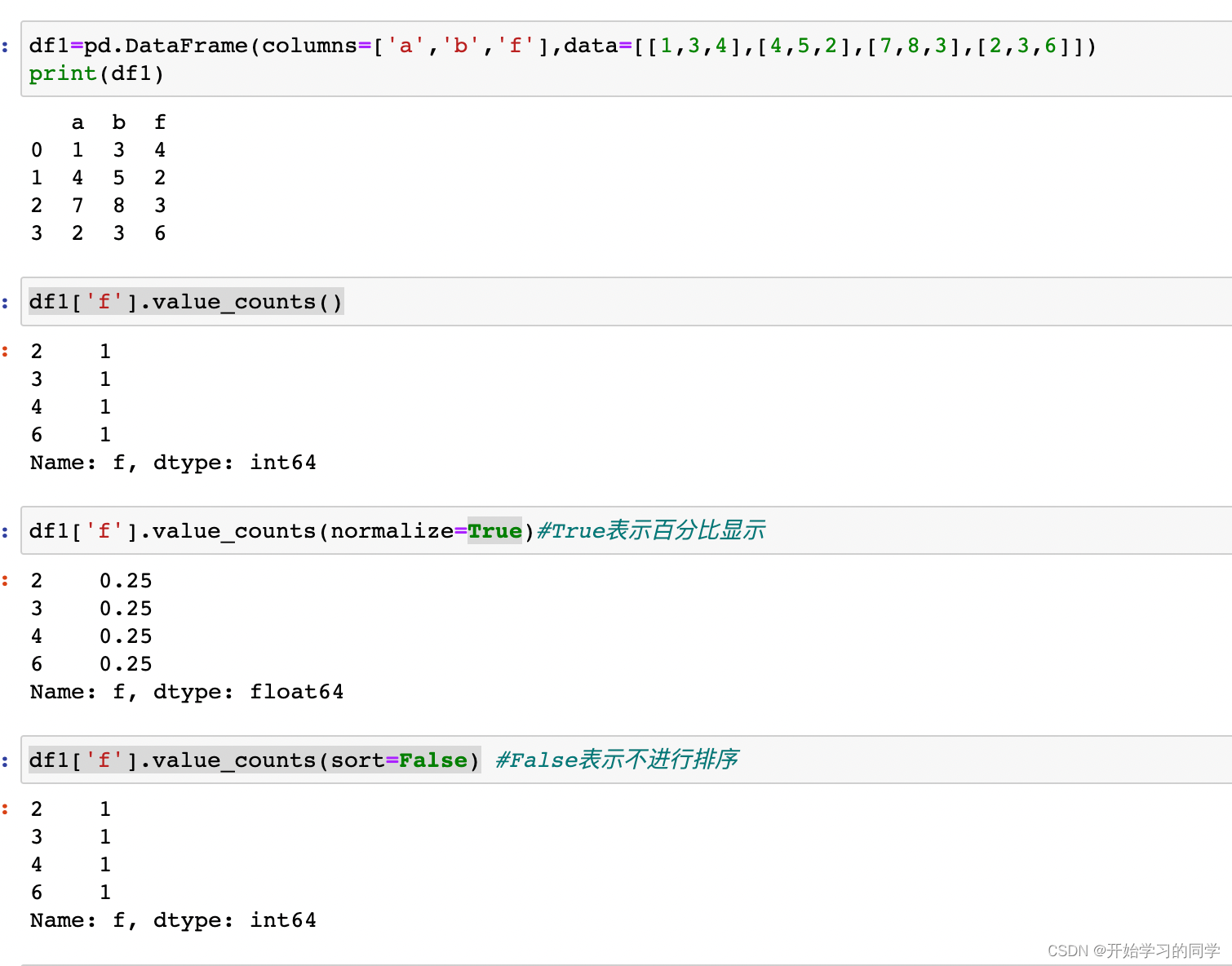
1.value_counts()
value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
- 1.normalize : boolean, 默认false,如为true,则以百分比的形式显示
- 2.sort : boolean, default True 默认为true,会对结果进行排序
- 3.ascending : boolean, default False 默认降序排序
- 4.bins : integer, 格式(bins=1),意义不是执行计算,而是把它们分成半开放的数据集合,只适用于数字数据
- 5.dropna : boolean, default True 默认删除na值
- value_counts()是默认显示数字形式,默认排序,默认降序,默认删除na
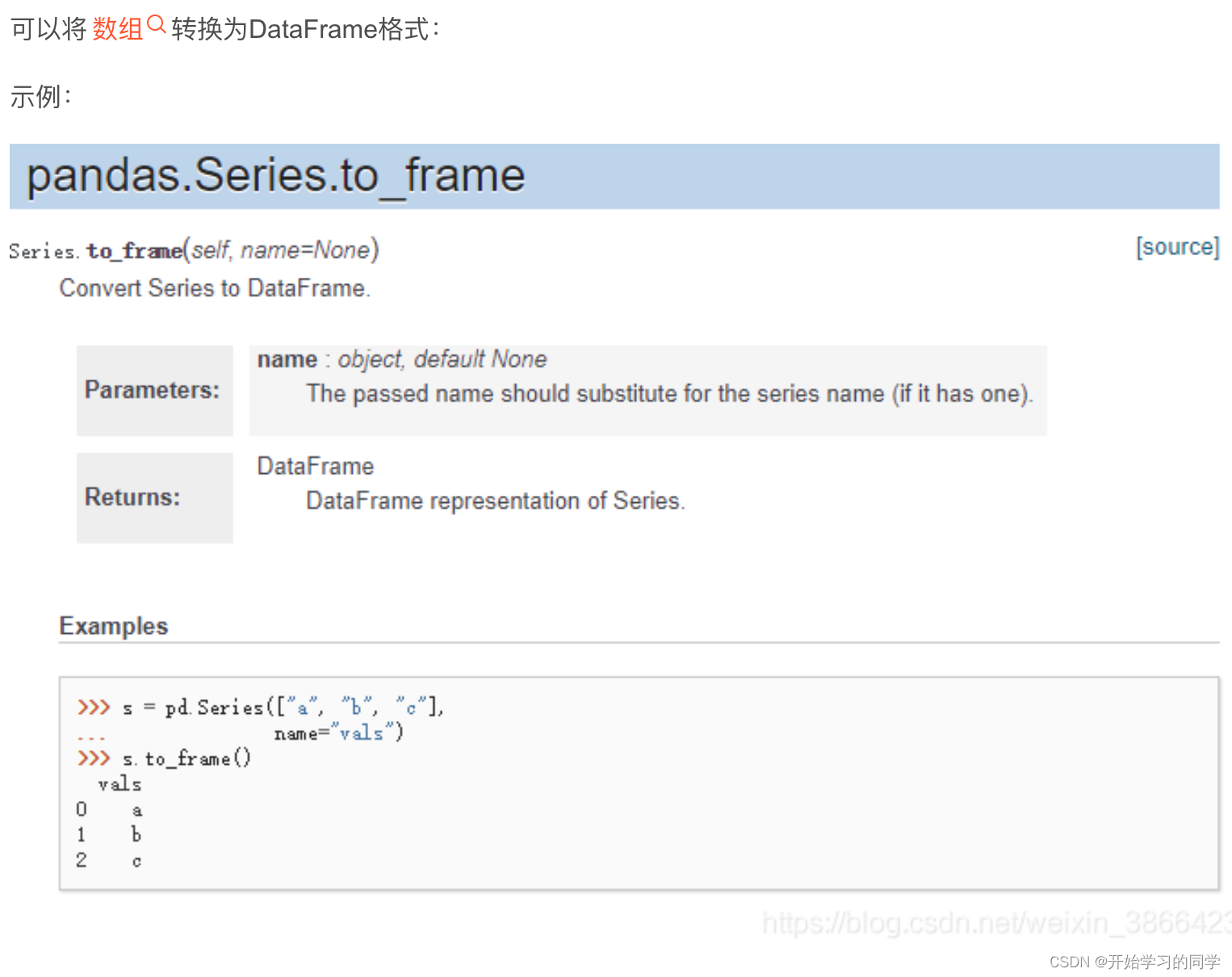
2.to_frame()
3.apply()
DataFrame.apply(func, axis=0, raw=False, result_type=None,
args=(), **kwargs)
参 数:
-
func : function 应用到每行或每列的函数。
-
axis :{0 or ‘index’, 1 or ‘columns’}, default 0 函数应用所沿着的轴。
0 or index : 在每一列上应用函数。
1 or columns : 在每一行上应用函数。 -
raw : bool, default False 确定行或列以Series还是ndarray对象传递。
-
False : 将每一行或每一列作为一个Series传递给函数。
-
True : 传递的函数将接收ndarray 对象。如果你只是应用一个 NumPy 还原函数,这将获得更好的性能。
-
result_type : {‘expand’, ‘reduce’, ‘broadcast’, None}, default None
只有在axis=1列时才会发挥作用。
expand : 列表式的结果将被转化为列。
reduce : 如果可能的话,返回一个Series,而不是展开类似列表的结果。这与 expand 相反。
broadcast : 结果将被广播到 DataFrame 的原始形状,原始索引和列将被保留。
默认行为(None)取决于应用函数的返回值:类似列表的结果将作为这些结果的 Series 返回。但是,如果应用函数返回一个 Series ,这些结果将被扩展为列。
- args : tuple 除了数组/序列之外,要传递给函数的位置参数。
- **kwds: 作为关键字参数传递给函数的附加关键字参数。

应用apply

4.applymap()
6.8日
1.describe()















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









