




文章目录
一、什么是对比学习
通过构造正例对和负例对,并减少正例对之间距离,增大负例对之间的距离,借此获得一个文本或者图片更好的表示向量。
对比学习的一个重要问题是如何构造正样本对,即通过 x 构造出 x+,有点类似数据增强。在图像领域这相对容易,通过对图像进行翻转、裁剪、加噪音、缩放等方式即可构造,而文本相对会难一些。常见的文本数据增强方式有删除词组、替换近义词、互译等方式。但是这些方式都是离散的,有时效果并不理想,因此 SimCSE 通过 Dropout 的方式构造正样本对。
二、对比学习为什么这么火
- 无监督的"对比学习"有效解决了机器学习中有监督学习所匮乏的数据标注难题。
- 众所周知,直接用BERT句向量做无监督语义相似度计算效果会很差,任意两个句子的BERT句向量的相似度都相当高,其中一个原因是向量分布的非线性和奇异性,前不久的BERT-flow通过normalizing flow将向量分布映射到规整的高斯分布上,更近一点的BERT-whitening对向量分布做了PCA降维消除冗余信息,但是标准化流的表达能力太差,而白化操作又没法解决非线性的问题,有更好的方法提升表示空间的质量吗?
丹琦女神的simcse论文提供了解决方案。而本篇论文就将对比学习的思想引入了SBERT,大幅刷新了有监督和无监督语义匹配SOTA,更让人惊叹的是,无监督SimCSE的表现在STS基准任务上甚至超越了包括SBERT在内的所有有监督模型。
三、Simcse是什么
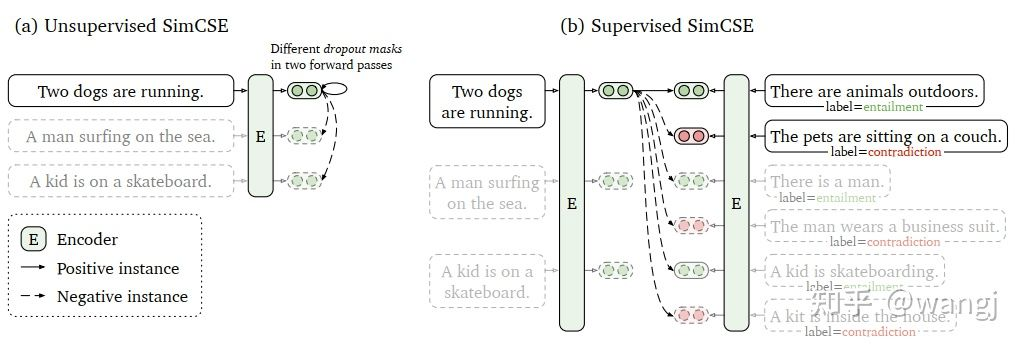
simcse是Simple Contrastive Learning of Sentence Embeddings的简称。它包含了两种方法:
1. 无监督SimCSE
正例对的获得有些巧妙,先将本句子输入到encoder中,这样会得到一个sentence embedding,然后再将该句子输入一遍到encoder,又会得到一个sentence embedding。将这两个sentence embedding组合到一起成为正例对。(由于dropout层在训练时会随机drop一些输入,所以同一个句子输入两遍得到的sentence embedding会有点区别。)而负例对的获得比较平淡无奇,就是从句子集合中挑一个句子,和本句子组合到一起,成为负例对。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









