







 本文介绍了如何利用GPU进行深度学习算法的加速,包括单GPU并行、多GPU卡的数据并行和模型并行计算,以及GPU集群的并行模式。详细探讨了CPU+GPU异构计算的优势,并通过Caffe和DNN的实际测试展示了性能提升。此外,还提到了CPU+FPGA协同计算在解决线上计算功耗问题上的潜力。
本文介绍了如何利用GPU进行深度学习算法的加速,包括单GPU并行、多GPU卡的数据并行和模型并行计算,以及GPU集群的并行模式。详细探讨了CPU+GPU异构计算的优势,并通过Caffe和DNN的实际测试展示了性能提升。此外,还提到了CPU+FPGA协同计算在解决线上计算功耗问题上的潜力。
1. 深度学习
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习典型应用为图像识别和语音识别。(由于本人不是深度学习专业人士,对深度学习理论知识不多介绍,说多了就班门弄斧了,后面主要介绍下这些深度学习算法如何进行并行化设计和优化)
2. CPU+GPU异构协同计算简介
近年来,计算机图形处理器(GPU,GraphicsProcess Unit)正在以大大超过摩尔定律的速度高速发展(大约每隔半年 GPU 的性能增加一倍),远远超过了CPU 的发展速度。
CPU+GPU异构协同计算模式(图1),利用CPU进行复杂逻辑和事务处理等串行计算,利用 GPU 完成大规模并行计算,即可以各尽其能,充分发挥计算系统的处理能力。
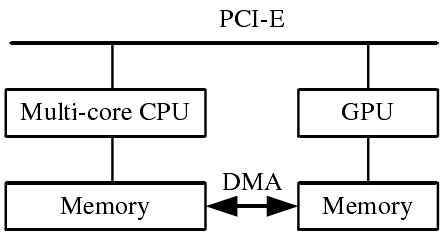
图1 CPU+GPU异构体系结构
目前,主流的GPU具有强大的计算能力和内存带宽,如图2所示,无论性能还是内存带宽,均远大于同代的CPU。对于GPU, Gflop/$和Gflops/w均高于CPU。

图2 GPU计算能力
3. 深度学习中的CPU+GPU集群架构
CPU+GPU集群工作模式(图3),每个节点内采用CPU+GPU异构模式,并且每个节点可以配置多块GPU卡。节点间采用高速InfiniBand网络互连,速度可以达到双向56Gb/s,实测双向5GB/s。后端采用并行文件系统。采用数据划分、任务划分的方式对应用进行并行化,适用于大规模数据并行计算。
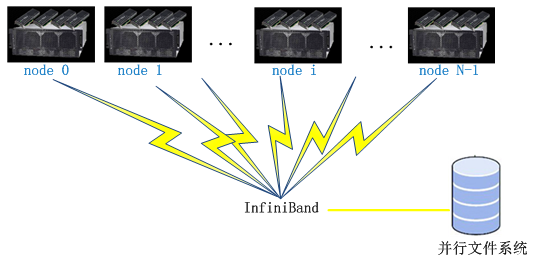
图3 CPU+GPU集群架构
4. 利用GPU加速深度学习算法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









