










这里源代码基本用的是tinycui的,tinycui的源代码下载地址是:http://download.csdn.net/detail/tinycui/4384750#comment。
为了运行上述的源代码,我主要参考的是Shizhixin的博客 《hadoop之测试KMeans(-):运行源码实例》,该博客地址是:http://blog.csdn.net/shizhixin/article/details/8968977。由于Shizhixin的所用的测试环境是eclipse,有些人可能还没装,所以这里我选择的是用命令行进行测试。说明从源代码和解释中可看出tinycui和Shizhixin使用的是伪分布的方式。而这里我用的是真实的集群,而不是伪分布。
这里附上我稍加修改过的代码,编译后的5个class文件我已经放于bin目录下,5个class文件打包生成的KMeans.jar文件我也放在了该目录下,5个java文件放在了src目录下。这些都是我通过下面的方法,通过命令行的方式编译出来的。这是下载地址:http://download.csdn.net/detail/zhang2010kang/8689941。
这里是我的hadoop的网络结点信息:
| IP | 主机名 | 结点信息 |
| 211.69.192.100 | hust.site | master/namenode |
| 211.69.192.101 | linux-o70w | slave/dtanode |
| 211.69.192.115 | linux-6gan.site | slave/datanode |
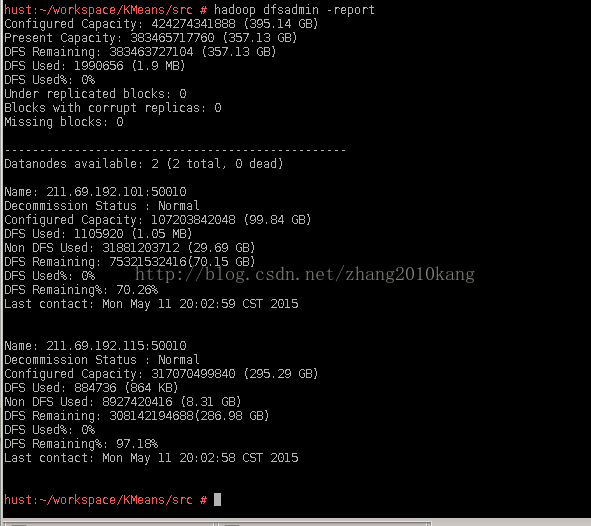
下图是使用 hadoop dfsadmin -report看到的结点信息:
下面是步骤:
1、从tinycui处下载得到KMeans源码。在src中会得到5个java文件,在bin中会得到已经编译好的class文件。这里我们准备自己进行编译和运行。
2、对java文件进行根据自己的实际情况进行适当的修改。这里我使用的是真实的集群,而不是伪分布的方式。
①修改KMapper.java中的
String centerlist = "hdfs://localhost:9000/KMeans/center/center";
String centerlist = "hdfs://hust.site:9000/user/root/center/center";②修改KMeans.java中的
conf.set("fs.default.name", "hdfs://localhost:9000");
conf.set("fs.default.name", "hdfs://hust.site:9000");其实就是你的hadoop的配置文件中的core-site.xml中的fd.default.name所指出的位置。
③修改CenterInitial.java中的k值为5。这里的k值是初始化时所随机选择的中心数目,由于是随机选择,即使编译好的代码完全相同的程序,最后的聚蔟也可能不同,算法的迭代次数也可能不同。理论上其它k值应该也可以,k值的范围选取是1到结点的数目。
④修改NewCenter.java中的k值为3,这里的k值是最后输出的聚蔟数。一般情况下,应该与CenterInitial.java中的k值设为相等。这里我有意设为不同,理论上其它k值应该也可以,这里的k值的范围选取是1到CenterInitial.java中k值。后面我会对结果进行分析。
之前没注意到k值的问题,这里感觉 luxialan的提醒。
3、下面进行Shizhixin所说的Step4,也就是在DFS上建立所需要的文件夹和文件。
①如果已经存在output需要将其删除,必须先删除执行以下的命令:
hadoop dfs -rmr output
hadoop dfs -mkdir center
touch center
hadoop dfs -put center center
vim cluster⑤在/user/root建立文件夹cluster,并将当前路径下的cluster上传到/user/root/cluster,上传完成后,检查是否成功输出。使用如下的指令:
vim cluster
cat cluster
hadoop dfs -mkdir cluster
hadoop dfs -put cluster cluster/
hadoop dfs -cat cluster/cluster
4、编译java文件。 由于KMeans.java文件中含有main函数,所以必须最后编译,并且KMeans.java会引用其它的4个类,它编译所引用的classpath会稍有不同。这里我的hadoop的安装路径是:/usr/lib/hadoop-1.2.1,你应该根据你的实际情况做相应的修改。
①利用如下命令编译CenterInitial.java、KMapper.java、KReducer.java、NewCenter.java这4个文件。
javac -classpath /usr/lib/hadoop-1.2.1/hadoop-core-1.2.1.jar CenterInitial.java
javac -classpath /usr/lib/hadoop-1.2.1/hadoop-core-1.2.1.jar KMapper.java
javac -classpath /usr/lib/hadoop-1.2.1/hadoop-core-1.2.1.jar KReducer.java
javac -classpath /usr/lib/hadoop-1.2.1/hadoop-core-1.2.1.jar NewCenter.java
javac -classpath /usr/lib/hadoop-1.2.1/hadoop-core-1.2.1.jar:.KMeans.java
jar -cvf KMeans.jar *.class
5、运行KMeans程序。使用如下的命令:
hadoop jar KMeans.jar KMeans cluster center output输出如下:注意具体输出与输入文件内容有关,由于初始化时是随机选取的k个结点,每次运行的结果与迭代次数可能不同。下面是运行的结果。
①第一次迭代。
由于CenterInitial.java中k设为了5,前5行中,每行的第一个点是随机选取的中心结点,这里可以看出初始时随机选取的5个中心结点是:(19,39) (20,30) (20,32) (50,61) (59,67)。
前5行中,每行的最后一个点是经过计算后所得到的新的中心结点,这里的中心结点的计算方法是取横纵坐标的均值, 比如第4行最后一个(20.8,32.2),(20+20+24+20+20+20)/5=20.8,(32+32+34+31+32)/5=32.2。可以看出计算出的5个新的中心结点是:(19.0,39.0) (20.0,30.0) (20.8,32.2) (50.0,64.2) (54.5,72.0)。
由于NewCenter.java中的k=3,所以这里算法只选择了5个新中心结点的前3个作为下一交迭代的中心结点。最后一行的3个点,就是下一次迭代的3的3个中心结点。(一般情况下,我们会使初始化时所选择的结点数与最后输出时的不聚簇数相等,在本算法中即是CenterInitial.java中的k与NewCenter.java中的k值设置成相等,本算法也能正确处理不相等的情况)。

②第二次迭代。
可以看出前3行的最左边的3个中心点是上一轮计算出来的。
本次迭代所使用的中心点前3行最左边点:(19.0,39.0) (20.0,30.0) (20.8,32.2)
本次计算所得的新的中心点,也就是下次迭代所使用的中心点前3行最右边,或最后一行:
(47.25,63.0) (20.0,30.333334) (21.0,32.5)

③第三次迭代。
可以看出前3行的最左边的3个中心点是上一轮计算出来的。
本次迭代所使用的中心点前3行最左边点:(20.0,30.333334) (21.0,32.5) (47.25,63.0)
本次计算所得的新的中心点,也就是下次迭代所使用的中心点前3行最右边,或最后一行:
( 20.0,30.333334 ) (20.6,33.8) (51.285713,66.42857)

④第四次迭代。
可以看出前3行的最左边的3个中心点是上一轮计算出来的。
本次迭代所使用的中心点前3行最左边点: (20.0,30.333334) (20.6,33.8) (51.285713,66.42857)
本次计算所得的新的中心点,也就是下次迭代所使用的中心点前3行最右边,或最后一行:
( 20.0,31.166666 ) (20.1.5,36.5) (51.285713,66.42857)

⑤第五次迭代。
显然第5次的结果与第4次进行对比可知,中心结点不变,每个聚簇不变,说明已经收敛,再计算下去结果也相同,可以停止。
所划分的3个聚簇是:
中心点(20.0,31.166666):(20,30) (20,32) (20,32) (20,30) (20,31) (20,32)
中心点(21.5,36.5):(19,39) (24,34)
足心点(51.285713,66.42857):(50,64) (50,65) (50,77) (50,61) (50,67) (50,64) (59,67)

下面附上我修改过的源码,可以直接在我第一部分提供的网址免费下载http://download.csdn.net/detail/zhang2010kang/8689941
①CenterInitial.java
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class CenterInitial {
public void run(String[] args) throws IOException
{
String[] clist;
int k = 5;
String string = "";
String inpath = args[0]+"/cluster"; //cluster
String outpath = args[1]+"/center"; //center
Configuration conf1 = new Configuration(); //读取hadoop文件系统的配置
conf1.set("hadoop.job.ugi", "hadoop,hadoop");
FileSystem fs = FileSystem.get(URI.create(inpath),conf1); //FileSystem是用户操作HDFS的核心类,它获得URI对应的HDFS文件系统
FSDataInputStream in = null;
ByteArrayOutputStream out = new ByteArrayOutputStream();
try{
in = fs.open( new Path(inpath) );
IOUtils.copyBytes(in,out,50,false); //用Hadoop的IOUtils工具方法来让这个文件的指定字节复制到标准输出流上
clist = out.toString().split(" ");
} finally {
IOUtils.closeStream(in);
}
FileSystem filesystem = FileSystem.get(URI.create(outpath), conf1);
for(int i=0;i<k;i++)
{
int j=(int) (Math.random()*100) % clist.length;
if(string.contains(clist[j])) // choose the same one
{
k++;
continue;
}
string = string + clist[j].replace(" ", "") + " ";
}
OutputStream out2 = filesystem.create(new Path(outpath) );
IOUtils.copyBytes(new ByteArrayInputStream(string.getBytes()), out2, 4096,true); //write string
System.out.println(string);
}
}
②KMapper.java
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.net.URI;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class KMapper extends Mapper<LongWritable, Text, Text, Text> {
private String[] center;
protected void setup(Context context) throws IOException,InterruptedException //read centerlist, and save to center[]
{
String centerlist = "hdfs://hust.site:9000/user/root/center/center"; //center文件
Configuration conf1 = new Configuration();
conf1.set("hadoop.job.ugi", "hadoop-user,hadoop-user");
FileSystem fs = FileSystem.get(URI.create(centerlist),conf1);
FSDataInputStream in = null;
ByteArrayOutputStream out = new ByteArrayOutputStream();
try{
in = fs.open( new Path(centerlist) );
IOUtils.copyBytes(in,out,100,false);
center = out.toString().split(" ");
}finally{
IOUtils.closeStream(in);
}
}
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens())
{
String outValue = new String(itr.nextToken());
String[] list = outValue.replace("(", "").replace(")", "").split(",");
String[] c = center[0].replace("(", "").replace(")", "").split(",");
float min = 0;
int pos = 0;
for(int i=0;i<list.length;i++)
{
min += (float) Math.pow((Float.parseFloat(list[i]) - Float.parseFloat(c[i])),2);
}
for(int i=0;i<center.length;i++)
{
String[] centerStrings = center[i].replace("(", "").replace(")", "").split(",");
float distance = 0;
for(int j=0;j<list.length;j++)
distance += (float) Math.pow((Float.parseFloat(list[j]) - Float.parseFloat(centerStrings[j])),2);
if(min>distance)
{
min=distance;
pos=i;
}
}
context.write(new Text(center[pos]), new Text(outValue));
}
}
}
③KMeans.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class KMeans {
public static void main(String[] args) throws Exception
{
CenterInitial centerInitial = new CenterInitial();
centerInitial.run(args);
int times=0;
double s = 0,shold = 0.0001;
do {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://hust.site:9000");
Job job = new Job(conf,"KMeans");
job.setJarByClass(KMeans.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(KMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(KReducer.class);
FileSystem fs = FileSystem.get(conf);
fs.delete(new Path(args[2]),true);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.waitForCompletion(true);
if(job.waitForCompletion(true))
{
NewCenter newCenter = new NewCenter();
s = newCenter.run(args);
times++;
}
} while(s > shold);
System.out.println("Iterator: " + times);
}
}
④KReducer.java
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class KReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key,Iterable<Text> value,Context context) throws IOException,InterruptedException
{
String outVal = "";
int count=0;
String center="";
int length = key.toString().replace("(", "").replace(")", "").replace(":", "").split(",").length;
float[] ave = new float[Float.SIZE*length];
for(int i=0;i<length;i++)
ave[i]=0;
for(Text val:value)
{
outVal += val.toString()+" ";
String[] tmp = val.toString().replace("(", "").replace(")", "").split(",");
for(int i=0;i<tmp.length;i++)
ave[i] += Float.parseFloat(tmp[i]);
count ++;
}
for(int i=0;i<length;i++)
{
ave[i]=ave[i]/count;
if(i==0)
center += "("+ave[i]+",";
else {
if(i==length-1)
center += ave[i]+")";
else {
center += ave[i]+",";
}
}
}
System.out.println(center);
context.write(key, new Text(outVal+center));
}
}
⑤NewCenter.java
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class NewCenter {
int k = 3;
float shold=Integer.MIN_VALUE;
String[] line;
String newcenter = new String("");
public float run(String[] args) throws IOException,InterruptedException
{
Configuration conf = new Configuration();
conf.set("hadoop.job.ugi", "hadoop,hadoop");
FileSystem fs = FileSystem.get(URI.create(args[2]+"/part-r-00000"),conf);
FSDataInputStream in = null;
ByteArrayOutputStream out = new ByteArrayOutputStream();
try{
in = fs.open( new Path(args[2]+"/part-r-00000"));
IOUtils.copyBytes(in,out,50,false);
line = out.toString().split("\n");
} finally {
IOUtils.closeStream(in);
}
System.out.println(out.toString());
for(int i=0;i<k;i++)
{
String[] l = line[i].replace("\t", " ").split(" ");
String[] startCenter = l[0].replace("(", "").replace(")", "").split(",");
String[] finalCenter = l[l.length-1].replace("(", "").replace(")", "").split(",");
float tmp = 0;
for(int j=0;j<startCenter.length;j++)
tmp += Math.pow(Float.parseFloat(startCenter[j])-Float.parseFloat(finalCenter[j]), 2);
newcenter = newcenter + l[l.length - 1].replace("\t", "") + " ";
if(shold <= tmp)
shold = tmp;
}
OutputStream out2 = fs.create(new Path(args[1]+"/center") );
IOUtils.copyBytes(new ByteArrayInputStream(newcenter.getBytes()), out2, 4096,true);
System.out.println(newcenter);
return shold;
}
}














 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









