







CPU缓存一致性
CPU缓存一致性主要解决的是多核CPU之间同时缓存一个变量的副本,当一个CPU核进行修改后其它核不能获取到最新数据的问题。
可以通过基于总线嗅探的MESI协议来保证CPU缓存一致性。
总线嗅探
当某个CPU核更新了Cache中的数据后,要通过总线把这个事件广播给其它所有的CPU核,然后每个CPU核会监听总线上的事件广播,如果发现自己的Cache中有对应的数据副本,则进行相应的操作。
MESI
**M:已修改;E:独占;S:共享;I:已失效;**用这4个状态来标记Cache中缓存行的状态。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-shWE4G33-1641471135761)(C:\Users\86151\AppData\Roaming\Typora\typora-user-images\image-20220104114129741.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sM2bXmt0-1641471135762)(C:\Users\86151\AppData\Roaming\Typora\typora-user-images\image-20220104114147712.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0eJjIv2q-1641471135762)(C:\Users\86151\AppData\Roaming\Typora\typora-user-images\image-20220104114203838.png)]
伪共享
①. 最开始变量 A 和 B 都还不在 Cache 里面,假设 1 号核心绑定了线程 A,2 号核心绑定了线程 B,线程 A 只会读写变量 A,线程 B 只会读写变量 B。
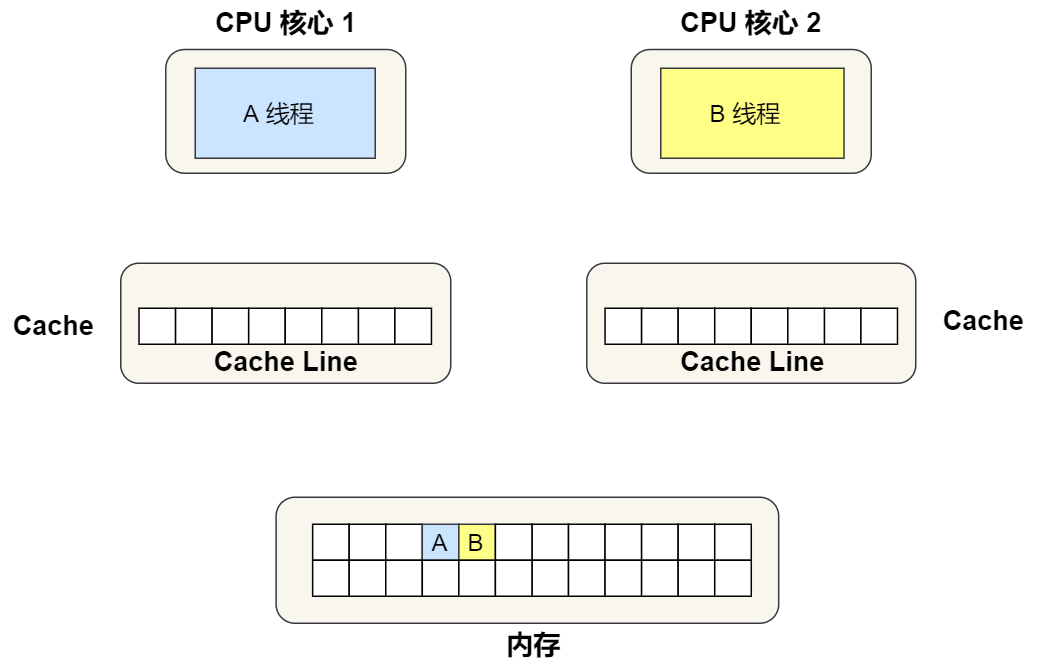
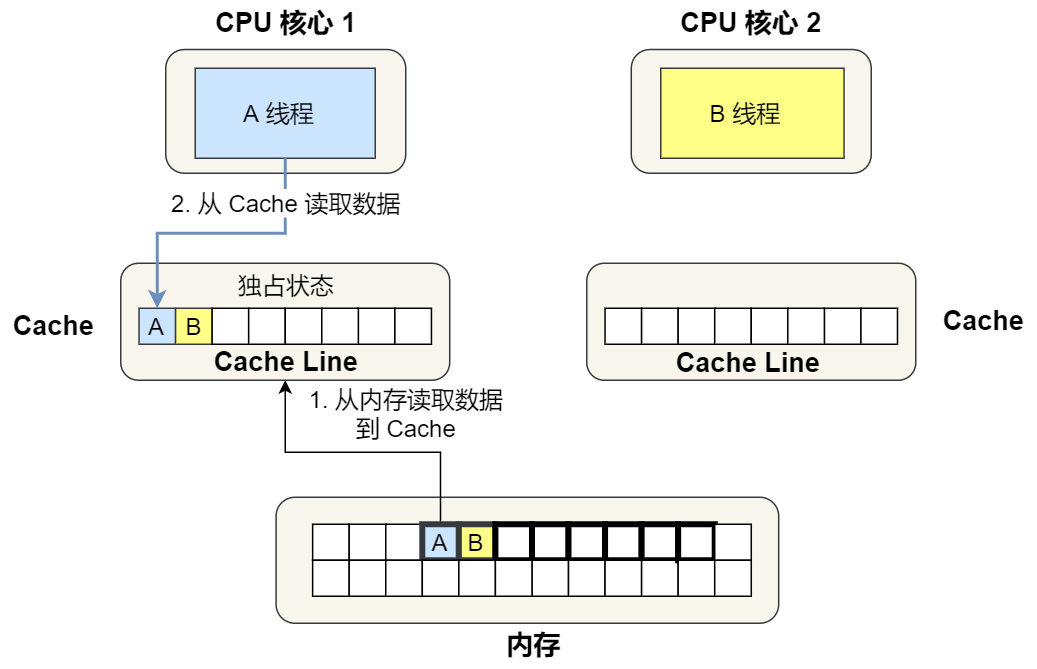
②. 1 号核心读取变量 A,由于 CPU 从内存读取数据到 Cache 的单位是 Cache Line,也正好变量 A 和 变量 B 的数据归属于同一个 Cache Line,所以 A 和 B 的数据都会被加载到 Cache,并将此 Cache Line 标记为「独占」状态。
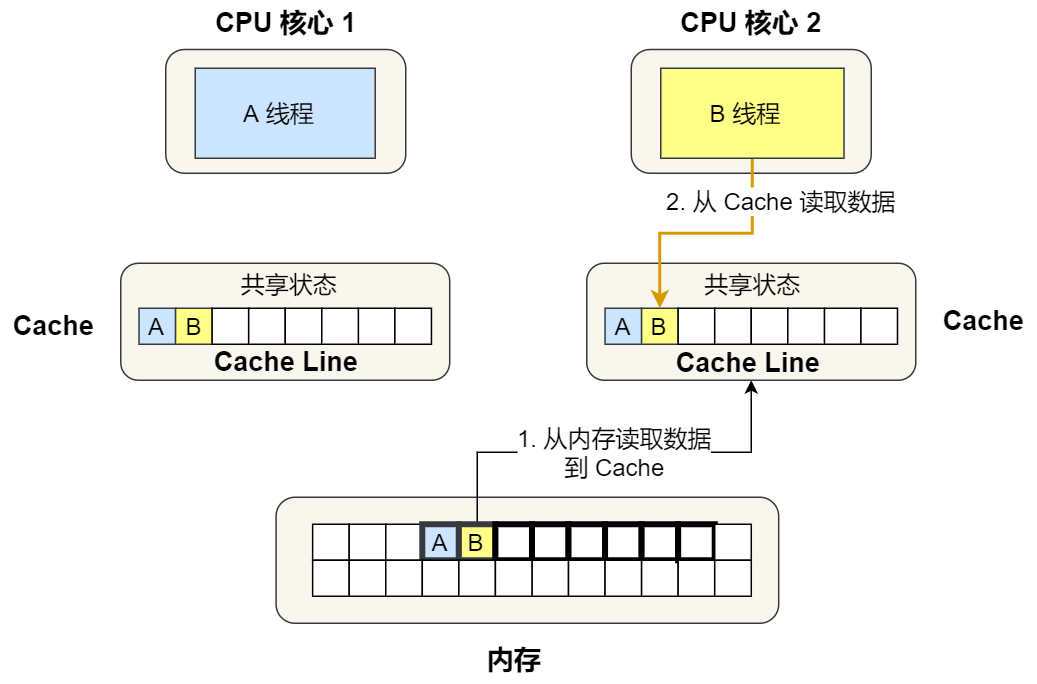
③. 接着,2 号核心开始从内存里读取变量 B,同样的也是读取 Cache Line 大小的数据到 Cache 中,此 Cache Line 中的数据也包含了变量 A 和 变量 B,此时 1 号和 2 号核心的 Cache Line 状态变为「共享」状态。
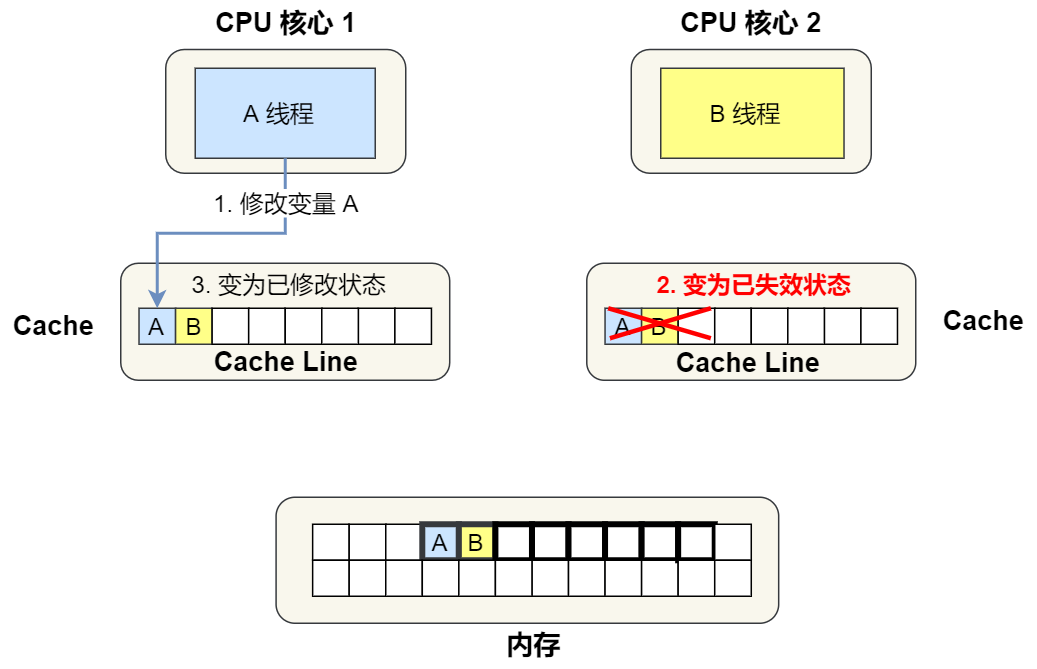
④. 1 号核心需要修改变量 A,发现此 Cache Line 的状态是「共享」状态,所以先需要通过总线发送消息给 2 号核心,通知 2 号核心把 Cache 中对应的 Cache Line 标记为「已失效」状态,然后 1 号核心对应的 Cache Line 状态变成「已修改」状态,并且修改变量 A。
⑤. 之后,2 号核心需要修改变量 B,此时 2 号核心的 Cache 中对应的 Cache Line 是已失效状态,另外由于 1 号核心的 Cache 也有此相同的数据,且状态为「已修改」状态,所以要先把 1 号核心的 Cache 对应的 Cache Line 写回到内存,然后 2 号核心再从内存读取 Cache Line 大小的数据到 Cache 中,最后把变量 B 修改到 2 号核心的 Cache 中,并将状态标记为「已修改」状态。
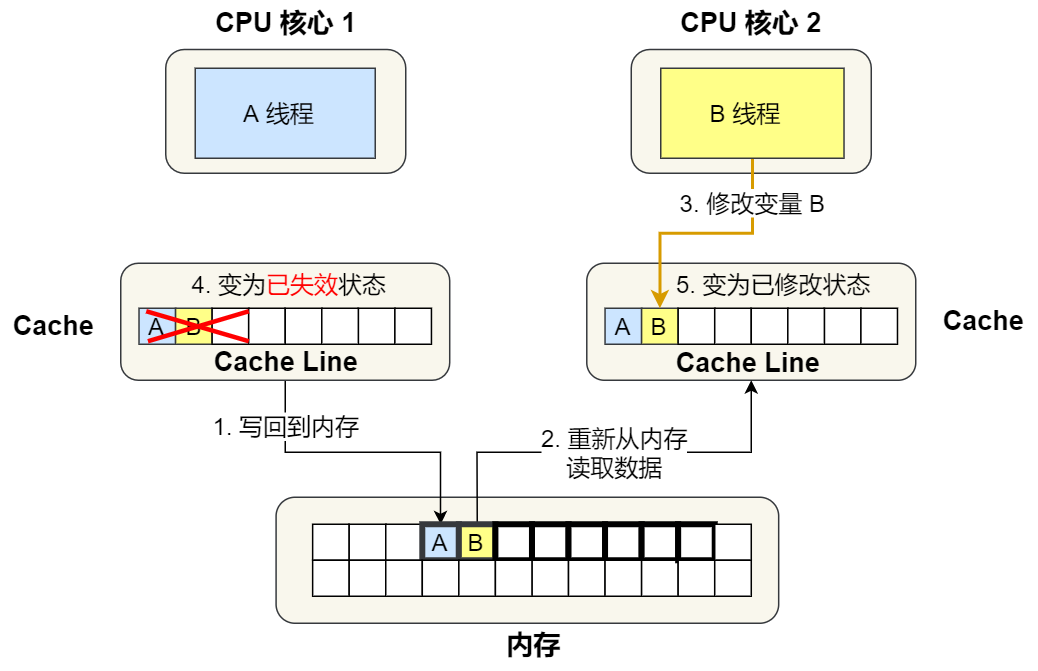
可以发现在这个过程中,缓存并没有发挥作用,这种因为多个线程交替读写同一个Cache Line的不同变量,而导致CPU Cache失效的现象称为伪共享问题。
解决方法:可以采用用空间换时间的思路,用无效数据来填充缓存行,使得一个变量独占一个缓存行,从而避免为共享问题。
内存管理机制
虚拟内存
虚拟内存是对物理内存的一层抽象,使得应用程序认为它拥有连续的可用的内存空间。在虚拟内存中,每个进程都有各自独立的地址空间。虚拟地址空间的页被映射到物理内存,这些页不一定连续并且并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,会发生缺页中断,然后执行页面置换算法,将该页从磁盘置换到内存中。
作用:
- 通过虚拟内存可以将不同进程的地址空间分离开,使得一个进程的操作不会影响到另一个进程;
- 让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存;
- 基于局部性原理,在程序载入时,将程序的一部分页面载入内存,而将其余部分留在外存,就可以启动程序执行;
- 虚拟内存也是段页式管理的核心,将程序编译后形成的不同的段(代码段.text、初始化数据段.data、未初始化数据段.bss、堆、栈)加载到虚拟内存不同的位置,然后再将虚拟内存中的段切分成页,映射到物理内存当中;
块式管理(malloc在堆中动态内存分配)
如何组织空闲块:
- 隐式空闲链表:每一个块分为3部分,①头部,记录块大小、是否已分配;②有效载荷;③填充,用于块对齐,使得块的首地址为8的倍数。这样通过块的头部信息就可以遍历所有的内存块并判断它是否为空闲块;
- 显式空闲链表:在隐式空闲链表的基础上只要在最后加上一个头部的副本即可构成一个双向链表,不过该链表址维护空闲块的信息即可,而不是所有的块。这样首次适配的时间复杂度就从隐式链表的块总数的线性降到了空闲块总数的线性;
- 分离空闲链表:维护多个空闲链表,每个链表中的空闲块的大小一样或者在某个区间范围内。当一个链表为空时,可以向空闲块更大的链表申请一个块,然后将其拆分为更小的空闲块添加到链表中;
如何分配空闲块:
- 首次适配:从头开始查找,将第一个满足其大小的空闲块分配给它。该算法使得低地址会出现大量的内存碎片,并且高地址部分的大空闲块会空闲。
- 循环首次适配:不是从头开始查找,而是从上一次的位置继续向后查找,直到找到第一个满足要求的空闲块。该算法能使空闲中的内存分区在低地址和高地址处分布得更加均匀。
- 最佳适配:将所有满足要求的空闲块中最小的那个空闲块分配给它。为了加速查找,该算法会将所有的空闲块按其大小排序,所以每次分配后必须重排序,时间开销大,并且还会产生大量无法利用的内存碎片;
- 最差适配:该算法按空闲块大小递减的顺序排序,分配时将最大的那个块分配给它。该算法会得到大小比较均匀的空闲块,但是会使得系统中没有大内存块。
段页式管理
分段
程序经过编译汇编链接后形成的可执行文件是按段来组织的。当我们在shell中运行这个可执行文件时,shell会通过fork()函数创建一个子进程,然后内核为该子进程分配虚拟内存,并将父进程虚拟内存中的内容复制一份。然后子进程调用execve函数,此时会将虚拟内存中的段删除掉,然后在虚拟内存中为该程序的各个段分配空间,分配好后将各个段的基址到填写段表中去。
分页
如果只有分段的话,很可能会出现两个段之间有较大内存空间,但是却不足以放下其它任何一个段的情况,因此会产生大量的内存碎片。为了减少对内存空间的浪费,我们用分页机制来管理物理内存。将虚拟地址中的段划分为多个页,然后将这些页映射到物理内存不同的页面上,当然这些页面不一定连续,完成映射以后填写页表。
如果将页表全部都放在内存中,则会占用非常多的内存,比如说:虚拟内存为4GB,页大小为4KB,则会有1M个页表项,并且每个进程都有自己的页表,所以内存开销很大。但是对于每个进程来说,许多地址空间都是没有使用到的,所以可以使用多级页表来减少页表占用的内存,在多级页表中,未使用到的地址空间不会有下一级页表,所以会节约空间。
但是每增加一级页表,就会增加一次访存开销,为了提高页表的查询速度,我们可以使用快表TLB来缓存页表项,TLB实质就是一个组相联的Cache。当需要查页表时,先去查TLB,如果有则直接返回,如果没有则去查多级页表并将查到的页表项缓存到TLB当中。
可以发现,虚拟内存是段页式内存管理的核心。程序员眼中的内存空间其实就是虚拟内存,我们将具有特定含义的可执行文件中的段加载到虚拟内存中一段连续的地址空间中,完成段式管理;然后通过虚拟内存,可以为程序员屏蔽掉真实物理内存是如何使用的,事实上会将虚拟内存中的段分割为页,然后将其映射到物理内存的页上,这个过程对程序员是不可见的。使用虚拟内存会给程序员一种假象,好像程序独占地使用内存。这是因为操作系统会为每个新创建地进程都分配一个4GB大小的虚拟内存空间,地址从0到4GB,高地址为操作系统内核,低地址为用户空间。但是不同进程间地虚拟地址空间相互独立,这是由于每个进程都有自己的段表和页表,所以即使在两个进程中虚拟地址相同,但是由于被映射到了不同的物理页面上,会使得它们的物理地址不同,因此一个进程的操作不会影响到另一个进程。
可执行文件代码中的地址是逻辑地址,因为不知道该段会被加载到虚拟内存中的那个位置,所以代码中的位置是相对于段的偏移,而不是真正的位置。所以在运行的时候要执行地址翻译,将逻辑地址变成虚拟地址,这个功能是由MMU来完成的。首先在每个进程的PCB中包含着段表和页表,当进程被调度到CPU中执行时,会将其段表基址和页表基址分别加载到寄存器LDTR和CR3当中,从而可以访问到段表和页表。具体的翻译过程如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zaMU3sLK-1641471135766)(C:\Users\86151\AppData\Roaming\Typora\typora-user-images\image-20220106200943870.png)]](https://img-blog.csdnimg.cn/e9ed9c5ab565417b9e0553b46c937f38.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Z2S5LqR5YWI55Sf,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RMWP6cq7-1641471135767)(C:\Users\86151\AppData\Roaming\Typora\typora-user-images\image-20220106195708043.png)]](https://img-blog.csdnimg.cn/aa0f963aa0e841b7b7d809dec1ebf3ef.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Z2S5LqR5YWI55Sf,size_20,color_FFFFFF,t_70,g_se,x_16)
页面置换算法
当执行地址翻译查页表时发现该页表项在物理内存中没有映射,则会触发缺页中断,然后中断处理程序会从磁盘中读取并将其放到内存的空闲页中,然后更新页表。如果内存中没有空闲页,就需要通过页面置换算法淘汰一个页面,将其换出到磁盘当中。
先进先出FIFO
优先淘汰最早进入内存的页面,即在内存中驻留时间最久的页面。该算法会将那些经常被访问的页面换出,导致缺页率升高。
最佳页面置换算法
淘汰最远将使用到到的页,缺页率最低。但是需要知道未来发生的事,无法实现。
LRU算法
为了实现 LRU,需要在内存中维护一个由所有页面构成的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。因为每次访问都需要更新链表,因此 LRU 代价较高。
Clock算法
其实质是LRU的近似算法,但是执行效率高。
具体来说,对每一个页设置一个访问位,每一次访问一个页时,将该位修改成1。当需要淘汰一个页面时,循环扫描该位,如果为1则将其置为0,如果为0则说明距上次扫描该页后,该页没有被访问过,所以淘汰该页。
但是如果缺页很少,即很长时间才会去执行一次扫描,则可能这段时间内所有的访问位都变成1了,这时就会退化成FIFO算法,缺页率升高。所以为了避免访问位累积太长时间的历史信息,可以定期清除访问位。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BRtE4KYi-1641471135767)(C:\Users\86151\AppData\Roaming\Typora\typora-user-images\image-20220106011407419.png)]](https://img-blog.csdnimg.cn/998dbe6bc1424a1ba9ea2dbc42de34ae.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6Z2S5LqR5YWI55Sf,size_20,color_FFFFFF,t_70,g_se,x_16)














 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









