







链接:GitHub - thunlp/OpenPrompt: An Open-Source Framework for Prompt-Learning.
Overview
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries. For more resources about prompt-learning, please check our paper list.
Prompt-learning 是将预训练语言模型 (PLM) 应用于下游 NLP 任务的最新范式,它使用文本模板修改输入文本并直接使用 PLM 执行预训练任务。 该库提供了一个标准、灵活和可扩展的框架来部署prompt-learning管道。 OpenPrompt 支持直接从 Huggingface Transformer 加载 PLM。 将来,我们还将支持其他库实现的 PLM。 有关快速学习的更多资源,请查看我们的论文列表。
What Can You Do via OpenPrompt?
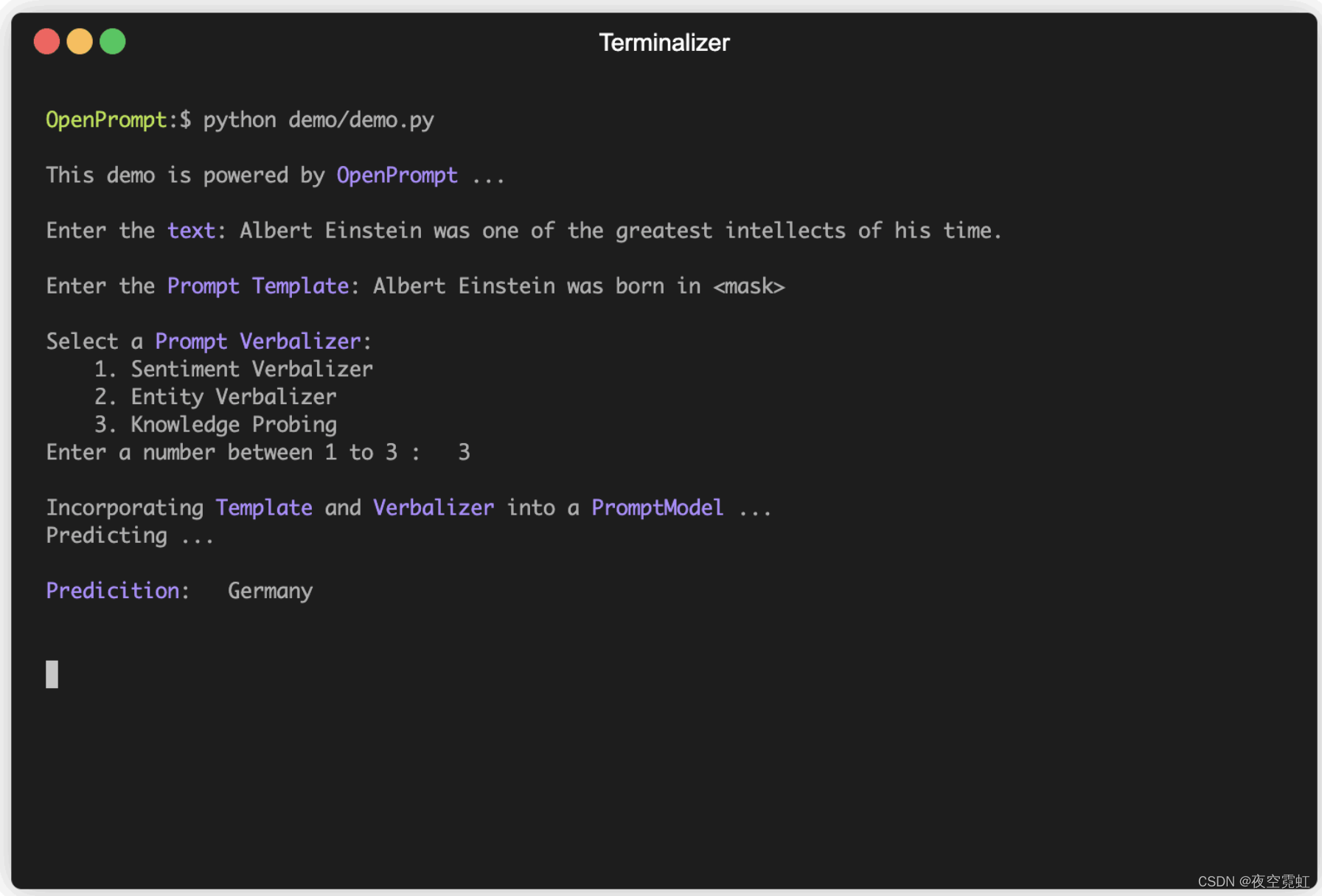
intellects:智力
prompt verbalizer(语言表达器):
sentiment(情绪) verbalizer
entity(实体) verbalizer
knowledge probing(知识探索)
Use the implementations of current prompt-learning approaches.
* We have implemented various of prompting methods, including templating, verbalizing and optimization strategies under a unified standard. You can easily call and understand these methods.
* Design your own prompt-learning work. With the extensibility of OpenPrompt, you can quickly practice your prompt-learning ideas.
使用当前即时学习方法的实现
* 我们在统一标准下实施了多种提示方式,包括模板化、语言化和优化策略。 您可以轻松调用和理解这些方法。
* 设计您自己的prompt-learning作品。 借助 OpenPrompt 的可扩展性,您可以快速练习prompt-learning的想法。
Installation
Using Pip
Our repo is tested on Python 3.6+ and PyTorch 1.8.1+, install OpenPrompt using pip as follows:
pip install openprompt

To play with the latest features, you can also install OpenPrompt from the source.
Using Git
Clone the repository from github:
git clone https://github.com/thunlp/OpenPrompt.git cd OpenPrompt pip install -r requirements.txt python setup.py install
Modify the code
python setup.py developUse OpenPrompt
Base Concepts
A PromptModel object contains a PLM, a (or multiple) Template and a (or multiple) Verbalizer, where the Template class is defined to wrap the original input with templates, and the Verbalizer class is to construct a projection between labels and target words in the current vocabulary. And a PromptModel object practically participates in training and inference.
PromptModel 对象包含一个 PLM、一个(或多个)模板和一个(或多个)Verbalizer,
其中模板类被定义为用模板包装原始输入,
Verbalizer 类用于构建当前词汇表中标签和目标词之间的映射。
PromptModel 对象实际上参与了训练和推理。
Introduction by a Simple Example
With the modularity and flexibility of OpenPrompt, you can easily develop a prompt-learning pipeline.借助 OpenPrompt 的模块化和灵活性,您可以轻松开发prompt-learning管道。
Step 1: Define a task
The first step is to determine the current NLP task, think about what’s your data looks like and what do you want from the data! That is, the essence of this step is to determine the classses and the InputExample of the task. For simplicity, we use Sentiment Analysis as an example. tutorial_task.
第一步是确定当前的NLP任务,想想你的数据是什么样子的,你想从数据中得到什么! 也就是说,这一步的本质是确定任务的类和 InputExample。 为简单起见,我们以情绪分析为例。 教程_任务。
from openprompt.data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly made.",
),
]
Step 2: Define a Pre-trained Language Models (PLMs) as backbone.将预训练语言模型 (PLM) 定义为主干。(不知道翻译为主干对不对)
Choose a PLM to support your task. Different models have different attributes, we encourge you to use OpenPrompt to explore the potential of various PLMs. OpenPrompt is compatible with models on huggingface.
选择一个 PLM 来支持您的任务。 不同的模型具有不同的属性,我们鼓励您使用 OpenPrompt 来探索各种 PLM 的潜力。 OpenPrompt 与 Huggingface 上的模型兼容。
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")
Step 3: Define a Template.定义模板。
A Template is a modifier of the original input text, which is also one of the most important modules in prompt-learning. We have defined text_a in Step 1.
模板是原始输入文本的修饰符,也是提示学习中最重要的模块之一。 我们在第 1 步中定义了 text_a。
from openprompt.prompts import ManualTemplate
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
Step 4: Define a Verbalizer 定义语言器
A Verbalizer is another important (but not neccessary) in prompt-learning,which projects the original labels (we have defined them as classes, remember?) to a set of label words. Here is an example that we project the negative class to the word bad, and project the positive class to the words good, wonderful, great.
Verbalizer 是提示学习中另一个重要的(但不是必需的),它将原始标签(我们已经将它们定义为类,记得吗?)投影到一组标签词。 这是一个示例,我们将负面类别投影到单词 bad,并将正面类别投影到单词 good、wonderful、great。
from openprompt.prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)Step 5: Combine them into a PromptModel 将它们组合成一个 PromptModel
Given the task, now we have a PLM, a Template and a Verbalizer, we combine them into a PromptModel. Note that although the example naively combine the three modules, you can actually define some complicated interactions among them.
鉴于任务,现在我们有一个 PLM、一个模板和一个 Verbalizer,我们将它们组合成一个 PromptModel。 请注意,尽管示例简单地组合了三个模块,但您实际上可以在它们之间定义一些复杂的交互。
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
Step 6: Define a DataLoader 定义数据加载器
A PromptDataLoader is basically a prompt version of pytorch Dataloader, which also includes a Tokenizer, a Template and a TokenizerWrapper.
PromptDataLoader 基本上是 pytorch Dataloader 的提示版本,其中还包括 Tokenizer、Template 和 TokenizerWrapper。
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset = dataset,
tokenizer = tokenizer,
template = promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
Step 7: Train and inference 训练和推理
Done! We can conduct training and inference the same as other processes in Pytorch.
完毕! 我们可以像 Pytorch 中的其他过程一样进行训练和推理。
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim = -1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'
使用带提示的预训练 MLM 进行零样本推理
运行结果:
positive
negtive
There are too many possible combinations powered by OpenPrompt. We are trying our best to test the performance of different methods as soon as possible. The performance will be constantly updated into the Tables. We also encourage the users to find the best hyper-parameters for their own tasks and report the results by making pull request.
OpenPrompt 支持的可能组合太多了。 我们正在尽最大努力尽快测试不同方法的性能。 性能将不断更新到表中。 我们还鼓励用户为自己的任务找到最佳超参数,并通过发出拉取请求来报告结果。
另一篇论文:《Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification》

















 1858
1858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









