







网络爬虫
一般我们在网络上抓取数据时,都会想到要使用网络爬虫,那我们就来看看一般网络爬虫的实现思路。
设计模式
爬虫的中心思想就是以最初一个Url为注入点,从这个Url抓取更多Url,并从这些网页中获取自己想要的数据。所以,我们可以使用一个队列来存储这些Url,然后使用 生产者消费者模式来对这个队列进行维护。
Queue<string> urlQueue=new Queue<string>();
public void AddUrl(string url)
{
lock(this)
{
urlQueue.Enqueue(url);
}
}
public string GetUrl()
{
lock(this)
{
string url="";
if(urlQueue.Count>0)
{
url=urlQueue.Dequeue();
}
return url;
}
}使用多线程能够更有效率的抓取数据,但是容易互相抢资源,所以要上锁。
目前我想到的多线程模式有两种,一种是 spider从队列中获取一个Url,然后从对应的网页获取其他Url和数据。另一种是分成专门生产Url的spider和专门从网页中抓取数据的spider。这里选第一种举例。
我们可以使用一个SpiderManager来管理所有的Spider,每一个Spider专门开一条线程来工作。
public class SpiderManager
{
List<Spider> spiders;
Queue<string> urlQueue=new Queue<string>();
public void AddUrl(string url)
{
lock(this)
{
urlQueue.Enqueue(url);
}
}
public string GetUrl()
{
lock(this)
{
string url="";
if(urlQueue.Count>0)
{
url=urlQueue.Dequeue();
}
return url;
}
}
public void Stop()
{
foreach(Spider spider in spiders)
{
spider.Stop();
}
}
}public class Spider
{
int restTime=1000;休眠间隔
Thread workingThread;
SpiderManager spiderManager
public Spider(SpiderManager sm)
{
this.spiderManager=sm;
}
pubclic void Start()
{
workingThread=new Thread(Work);
workingThread.Start();
}
private void Work()
{
while(true)
{
string url=sm.GetUrl();
if(url=="")
{
Sleep(restTime);
Continue;
}
//抓取数据
}
}
public void Stop()
{
if(workingThread!=null)
{
workingThread.Abort();
workingThread=null;
}
}
}URL查重
一般来说我们不想重复的抓取同一张网页,这个时候就需要查重技术了。
我们可能会使用hash表来存储对应的url,这的确能够解决一部分问题。但如果我们要抓取的数据量非常大的话,hash表就满足不了我们的需求了,这个时候我们就可以使用布隆过滤器来进行查重。
布隆过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量和一系列随机映射函数组成,布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(假正例False positives,即Bloom Filter报告某一元素存在于某集合中,但是实际上该元素并不在集合中)和删除困难,但是没有识别错误的情形(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
布隆过滤器实际上一个很长的二进制和随机映射函数。首先,将这个二进制中的数据全设为0,然后将我们url使用随机映射函数映射到这个二进制中的随即八个位置,将他们设为1。如果要查看url是否重复,可以就可以查看对应的位置是否均为1。这样就能节省非常多的空间,对于5000w级的url,只占用200mb的空间,缺点是有可能会误判。不过误判的几率非常低,如果在意的话可以建立白名单来补救。
优化
如果我们进行大量并发的抓取数据的话,可能在一条队列中会阻塞很久,我们可以多开几条队列,并使用标志位来分流。
如果抓取大量数据的话,可能还会使用分布式的架构来抓取,那分布式的话应该是怎样呢。分布式的话就需要考虑到不同机器之间的通信,以及容错。通信的话可以使用Socket来进行网络间的通信。
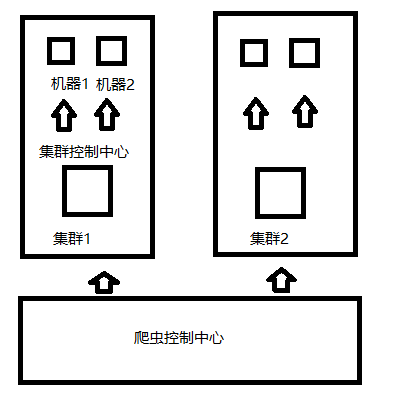
- 爬虫控制中心:控制整个爬虫系统
- 集群控制中心:控制整个集群,集群中的每个机器都和集群控制中心通信
集群中心将任务分派给不同机器,并且与机器进行心跳连接。如果机器连接超时,则认为机器宕机,将该机器上的任务取回分派给其他机器。















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









