







YOLO:实时快速目标检测
https://zhuanlan.zhihu.com/p/25045711?refer=shanren7
YOLO详解
https://zhuanlan.zhihu.com/p/25236464
传统目标检测系统采用deformable parts models (DPM)方法,通过滑动框方法提出目标区域,然后采用分类器来实现识别。近期的R-CNN类方法采用region proposal methods,首先生成潜在的bounding boxes,然后采用分类器识别这些bounding boxes区域。最后通过post-processing来去除重复bounding boxes来进行优化。这类方法流程复杂,存在速度慢和训练困难的问题。
YOLO采用单个卷积神经网络来预测多个bounding boxes和类别概率;YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
===
直接画一张图吧:不过 YOLO出了第二版了,亲测很牛逼!地址:YOLO: Real-Time Object Detection

个人觉得,分析比较Faster Yolo SSD这几种算法,有一个问题要先回答,Yolo SSD为什么快?
个人觉得,分析比较Faster Yolo SSD这几种算法,有一个问题要先回答,Yolo SSD为什么快?最主要的原因还是提proposal(最后输出将全连接换成全卷积也是一点)。其实总结起来我认为有两种方式:1.RPN,2. 暴力划分。RPN的设计相当于是一个sliding window 对最后的特征图每一个位置都进行了估计,由此找出anchor上面不同变换的proposal,设计非常经典,代价就是sliding window的代价。相比较 yolo比较暴力 ,直接划为7*7的网格,估计以网格为中心两个位置也就是总共98个”proposal“。快的很明显,精度和格子的大小有关。SSD则是结合:不同layer输出的输出的不同尺度的 Feature Map提出来,划格子,多种尺度的格子,在格子上提“anchor”。结果显而易见。还需要说明一个核心: 目前虽然已经有更多的RCNN,但是Faster RCNN当中的RPN仍然是一个经典的设计。下面来说一下RPN:(当然你也可以将YOLO和SSD看作是一种RPN的设计)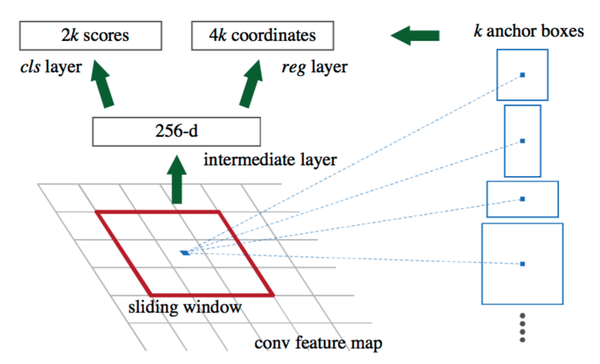 在Faster RCNN当中,一张大小为224*224的图片经过前面的5个卷积层,输出256张大小为13*13的 特征图(你也可以理解为一张13*13*256大小的特征图,256表示通道数)。接下来将其输入到RPN网络,输出可能存在目标的reign WHk个(其中WH是特征图的大小,k是anchor的个数)。实际上,这个RPN由两部分构成:一个卷积层,一对全连接层分别输出分类结果(cls layer)以及 坐标回归结果(reg layer)。卷积层:stride为1,卷积核大小为3*3,输出256张特征图(这一层实际参数为3*3*256*256)。相当于一个sliding window 探索输入特征图的每一个3*3的区域位置。当这个13*13*256特征图输入到RPN网络以后,通过卷积层得到13*13个 256特征图。也就是169个256维的特征向量,每一个对应一个3*3的区域位置,每一个位置提供9个anchor。于是,对于每一个256维的特征,经过一对 全连接网络(也可以是1*1的卷积核的卷积网络),一个输出 前景还是背景的输出2D;另一个输出回归的坐标信息(x,y,w, h,4*9D,但实际上是一个处理过的坐标位置)。于是,在这9个位置附近求到了一个真实的候选位置。
在Faster RCNN当中,一张大小为224*224的图片经过前面的5个卷积层,输出256张大小为13*13的 特征图(你也可以理解为一张13*13*256大小的特征图,256表示通道数)。接下来将其输入到RPN网络,输出可能存在目标的reign WHk个(其中WH是特征图的大小,k是anchor的个数)。实际上,这个RPN由两部分构成:一个卷积层,一对全连接层分别输出分类结果(cls layer)以及 坐标回归结果(reg layer)。卷积层:stride为1,卷积核大小为3*3,输出256张特征图(这一层实际参数为3*3*256*256)。相当于一个sliding window 探索输入特征图的每一个3*3的区域位置。当这个13*13*256特征图输入到RPN网络以后,通过卷积层得到13*13个 256特征图。也就是169个256维的特征向量,每一个对应一个3*3的区域位置,每一个位置提供9个anchor。于是,对于每一个256维的特征,经过一对 全连接网络(也可以是1*1的卷积核的卷积网络),一个输出 前景还是背景的输出2D;另一个输出回归的坐标信息(x,y,w, h,4*9D,但实际上是一个处理过的坐标位置)。于是,在这9个位置附近求到了一个真实的候选位置。
===
简单明了
作者:X.Zhao
链接:https://www.zhihu.com/question/35887527/answer/223595715
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简明一些的解释
R-CNN估计候选位置信息,针对所有候选区域的二维特征图,逐一执行CNN推演得到类别信息。
Fast R-CNN(重复 R-CNN)估计候选位置信息,基于候选区域的特征图生成一维特征向量,逐一执行FC推演同时得到类别和位置信息。
Faster R-CNN基于所谓的区域选择网络估计候选区域,(重复Fast R-CNN)基于候选区域的特征图生成一维特征向量,逐一执行FC推演同时得到类别和位置信息。
FPN与其它模型只用单层特征相比,FPN将高层特征图融合至多个低层特征图。即提供具有强壮语义的多层特征图,进而增强模型对小目标的处理能力。Faster R-CNN 加入 FPN 后,显著提升了检测能力。
SSD不同于其他模型提取候选区域,SSD 使用所谓的锚箱替代区域选择网络,同时估计目标的类别信息和位置信息。
评价这一系列方法
观察 R-CNN -> Fast R-CNN -> Faster R-CNN + FPN -> SSD 的发展过程,由直观但繁琐的 R-CNN 逐渐发展至可端到端训练的 Faster R-CNN 和 SSD,算法精度的持续上升 或 提高检测速度的过程中,新算法弥补了上一种算法中的显著弱势。发展趋势合情合理,却又让人觉得精妙称赞。作为总结,静心分析已有算法,有利于了解研究现状,站在巨人的肩膀上更会产出优秀的成果。
1. [Fast R-CNN]
2. [Faster R-CNN] Towards Real-Time Object Detection with Region Proposal Networks
3. [FPN] Feature Pyramid Networks for Object Detection
4. [SSD] Single Shot Multibox Detectior
===
知乎笔记:
RCNN-将CNN引入目标检测的开山之作
SPPNet-引入空间金字塔池化改进RCNN
Fast R-CNN
Faster R-CNN
图解YOLO
SSD
YOLO2
晓雷机器学习笔记
参考:
[1] R-CNN: Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C], CVPR, 2014.
[2] SPPNET: He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C], ECCV, 2014.
[3] Fast-RCNN: Girshick R. Fast R-CNN[C]. ICCV, 2015. [4] Fater-RCNN: Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]. NIPS, 2015.
[5] YOLO: Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. arXiv preprint arXiv:1506.02640, 2015.















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









