







基本思想:通过tesseract_ocr完成一项字符识别任务,和paddle_ocr做了对比后,分析本项目后试试tesseract_ocr效果
1、安装tesseract
Ubuntu
sudo apt-get install tesseract-ocrMac
brew install tesseractWindows
tesseract 下载地址:https://digi.bib.uni-mannheim.de/tesseract/
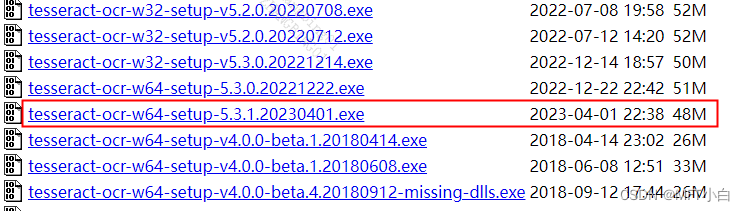
1.1 在安装的过程中,安装的路径一般是:
C:\Program Files\Tesseract-OCR,可以按照自己熟悉路径修改
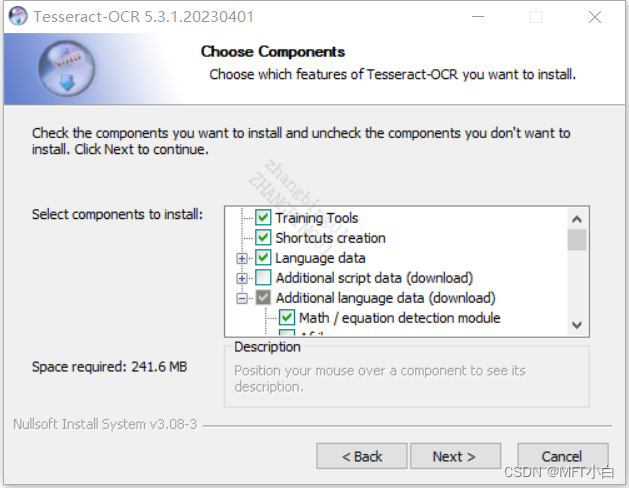
2.2 然后一直点击next,直到下面下面这张图。此时可以勾选 Additional language data(download) 选项来安装OCR识别支持的语言包,这样OCR便可以识别多国语言,比如可以选择math,英文,中文等。然后一路点击Next按钮即可
2、配置环境变量
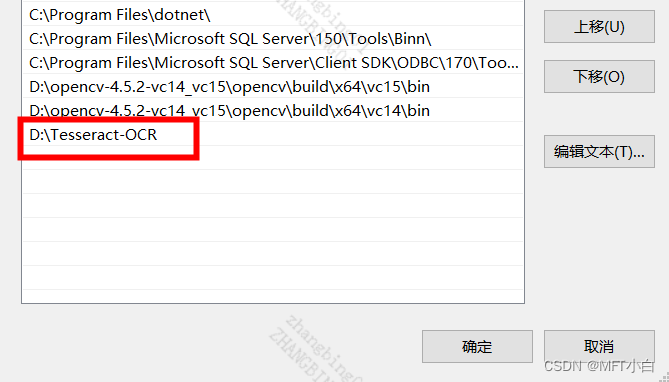
2.1 为了在全局使用方便,比如安装路径为:
D:\Tesseract-OCR,将该路径添加到环境变量的path中。
2.2 路径:高级系统设置——>环境变量——>系统变量中path路径——>将 D:\Tesseract-OCR 添加进去。
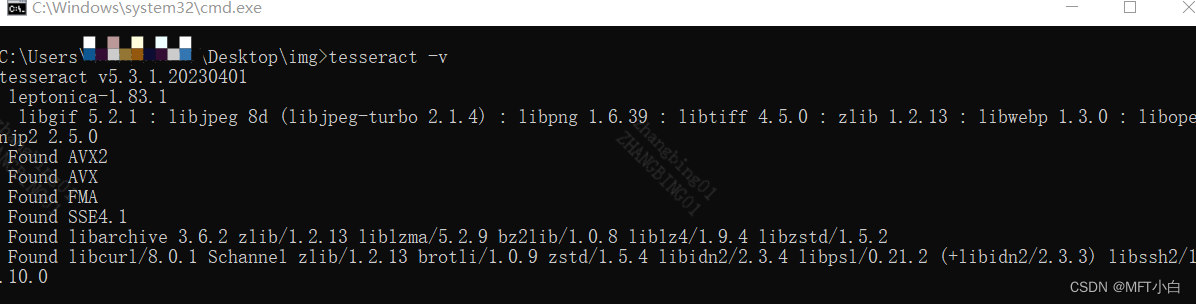
2.3 配置完成后在cmd中输入 tesseract -v,如果出现如下图所示,说明环境变量配置成功。
3、 终端出现的报错问题及解决方法
3.1 测试图片 test01.jpg

3.2 使用cmd 先到图片当前路径,然后使用tesseract命令进行测试
tesseract test.jpg result这里我们调用了tesseract命令,其中第一个参数为图片名称,第二个参数result 为结果保存的目标文件名称。
3.3 输入上述代码回车后,出现了以下的报错提示.
Error opening data file \Program Files (x86)\Tesseract-OCR\tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
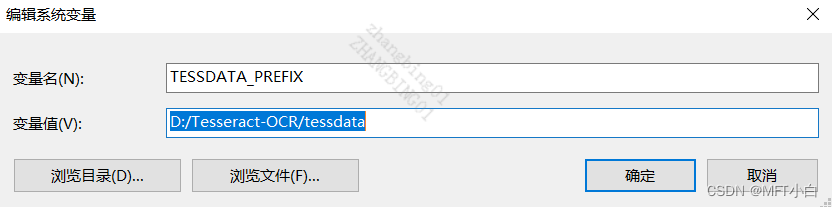
Could not initialize tesseract.3.4 报错是意思是缺少环境变量 TESSDATA_PREFIX,导致无法加载任何语言,就不能初始化tesseract。解决的方法也很简单,在环境变量——>系统变量中添加TESSDATA_PREFIX,如下图:
注(地址复制时是右斜杠 “\”,但是需要改成 左斜杠"/" 符号,如下图划红线处)
3.5 配置完成后,重新打开cmd,重新运行。

3.6 测试数字识别

tesseract example.jpg stdout digits 















 4508
4508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









