






软考中级软件设计师备考笔记
考试分为两部分(已改革):240分钟,科目一科目二连着考,机考。分值如下:
科目一:
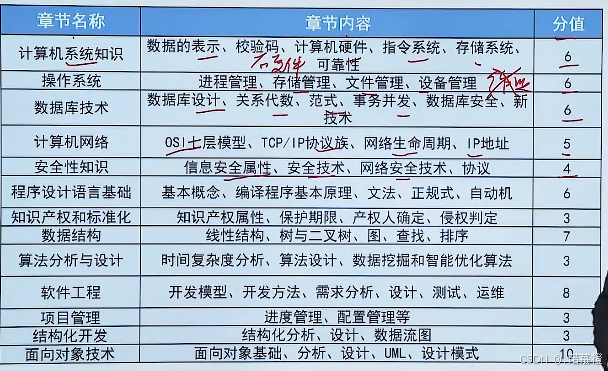
计算机组成原理6;操作系统6;数据库6;
计算机网络5;网络安全4;法律法规3;
程序设计基础
16(编译原理+数据结构+算法6+7+3);
软件工程开发生命周期
24(软件工程
开发8+项目
管理3+结构化
开发3+面向对象UML设计
开发10);
专业英语5;
科目二:
第一章 计算机组成原理
1.1数值转换、进制、数据表示
1.进制缩写:
二进制B(bin)、八进制O(Oct)、十进制D(dec)、十六进制H(hex)
2.R进制→十进制:
R上每一位的数乘R对应权重的和
如:
251.5(O)
=2*64+5*8+1*1+5*0.125 =
169.625(D)
3.十进制→R进制:
短除法
4.真值:符合人类习惯的数字
5.机器数:
数字在计算机内的表示形式,0正1负。
6.机器数分类:
无符号数(都是正数,无符号位)和有符号数(机器字长n+1位符合占1位)
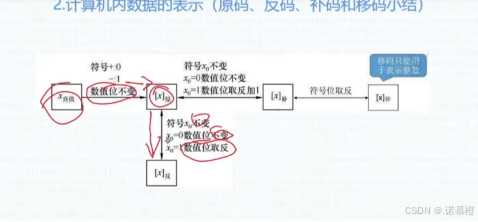
7.(重难点)原反补移码:
1)原码:
符号位(0正1负)+数值位。
2)特别的原码:
0,有﹢0和-0。表示:0,000000和1,0000000
3)原码字长n+1位。数值位n位,符号位1位。
4)原码表示的数的范围:x∈[-(2^n-1),^2^n-1]
5)反码:符号位0:反码=原码;符号位1:反码=原码数值位全部取反
6)特别的反码:0,+0和-0,表示:0,0000000和1,11111111
7)反码字长n+1位。数值位n位,符号位1位。
8)反码表示范围:x∈[-(2^n-1),^2^n-1]
9)补码:符号位0:原反补一样;符号位1:反码+1
10)注意:0的补码只有一种:+0和-0都是00000000
11)字长一样,范围一样
12)范围:x∈[-(2^n),^2^n-1],多一个 -2^n!!!!
13)移码:只能表示整数!!!
14)注意注意:符号位
0负1正
,反过来了,一定要当心!!!
15)移码:补码 符号位 取反。不管正数负数都要取反
16)特别的移码:+0和-0 有1000000和0000000
17)范围:x∈[-(2^n),^2^n-1],多一个 -2^n!!!!
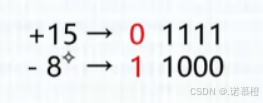
练习:1.[x]补 = 1,0000 000 . 则x = ?(-128)
答:通过补求原:注意溢出了
2. x= -20,求原反补移码
8. 计算机内的数据除了上述原反补移,还有
定点数和浮点数。
9.
定点数:有
定点整数和
定点小数
10.
定点整数:小数点在最后一位有效位之后的
纯整数,
例如:机器字长5位。5(D) = 0,0110.
11. 定点小数:小数点在首位有效数字之前的
纯小数
例如:机器字长5位。0.5(D) = 0, .1000
12.
浮点数:小数点不固定的数。
13.
注意:浮点数有原反补移码。数有定点数浮点数,码是数的码。
14. 格式

N = M * R^E(浮点数 = 尾数 * R进制数^码阶)
其中,阶符就是0和1,原反补0正;移码1正
码阶决定浮点数大小,尾数决定浮点数精度
15. 举例:
(类比科学计数法)3.14×10³ = 31.4×10²
3.14是尾数M
10是R进制数R
3是码阶
阶符为0
16.
校验码:因为数据传输可能会出错,为了保证不出错,引入校验码。
17.
(考纲要求三种校验码) :CRC、奇偶校验、海明码
18.
奇偶校验只能发现错误
不能纠错。
19.
CRC可以发现并
可以纠错。
20.
海明码可以发现并
可以纠错。>=3位

21.逻辑表达式的
后缀式
基本概念:略
举例:有逻辑表达式:a∧b∨c∧(b∨x>0),(其中∨或、∧与),求其后缀式:(注:一般考客观,用选项代入验算即可)
a∧b∨c∧(b∨x>0) = ab∧cbx>∨∧∨
1.2计算机组成、指令系统
1. 冯诺依曼计算机组成:
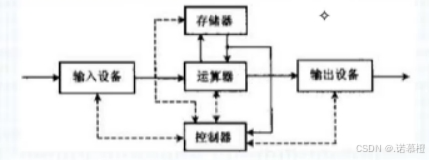
2. 冯诺依曼计算机特点:
(1)
组成:由五个部件组成:I、O、存储器、运算器、控制器
(2)
核心:运算器为中心
(3)
指令与数据都是二进制表示
(4)
指令和数据以同等地位存储在存储器,可以按地址寻访
(5)
指令构成:操作码+地址码
(6)
存储程序
3. I / O与存储器之间的数据传输由控制器完成。
4. 现在的计算机会把
运算器和控制器集成,成为CPU(中央处理单元)
5. 各部件功能:
输入设备把信息转化为0和1;
输出设备把结果转换为人能看懂的东西;
主存储器(主存:ROM和RAM。ROM主要用于存储基本指令和硬件驱动程序,而RAM则是用于暂时存储计算机程序运行所需的数据和指令。)存数据和程序的。
运算器:算逻运算。
控制器:指挥各部件工作运行。
6. 主存:
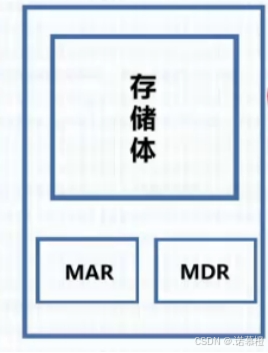
7. 存储元:可存一个二进制位1bit
存储单元:(放代码的单元楼)每个存储单元放一串二进制代码 (8个=8bit)
存储字(word)(代码本身):存储单元中二进制代码的组合
存储字长:存储字的位数
[区别]机器字长:指计算机进行一次整数运算所能够处理的二进制的位数
8. MDR
数据寄存器 标记存储单元可以存放的位数(决定单人上限)
计算方法: MDR16位=存储字长16位
9. MAR
地址寄存器 标记存储单元的个数,个数信息放入MAR(决定个数上限)
计算方法:MAR 4位 = 2^4个存储单元
10. 运算器:

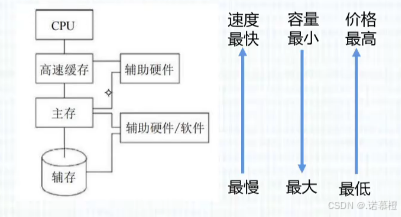
11. 运行速度(快→慢)(容量小→大):CPU>CPU旁边的通用寄存器X>cache>主存>辅存
13. 计算机体系结构(Flynn分类法):SISD单指令流单数据流、SIMD、MISD(不实际)、MIMD
14. 指令:计算机工作的最小单位。是机器语言的一个语句,是一组有意义的二进制代码。本质上就是00101101.步骤是点击软件播放音乐按钮,然后计算机生成指令,给硬件读,硬件处理指令开始播放音乐。
15. 指令系统:又称指令集。指所有指令的集合。
16. 指令构成:操作码 O P + 地址码 A。
(1)
操作码:用户要干什么?(听音乐)操作类型是什么?(加减乘除)
(2)
地址码:谁来干这事?(播放器)操作对象是谁?(操作数)
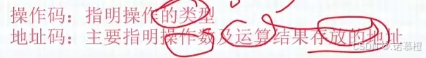
17. 指令系统有
寻址方式
。因为要寻找指令中操作数有效地址
(1)
立即寻址:操作数作为指令的一部分直接写在指令中,这个操作数称作立即数
(2)
寄存器寻址:指令所需的
操作数
已经存储在CPU周围大量的X通用的
寄存器中,或把目标操作数存入寄存器。
(3)
直接寻址:指令所要的操作数存放在
内存
中,在指令的地址码会给出操作数的有效地址。
(4)
寄存器间接寻址:


后面几种:略,直接背、记就行
考的比较简单,
全背。
客观题会选就可以
18.
指令系统
分类:CISC、RISC
(1)各自特点
(背)
:
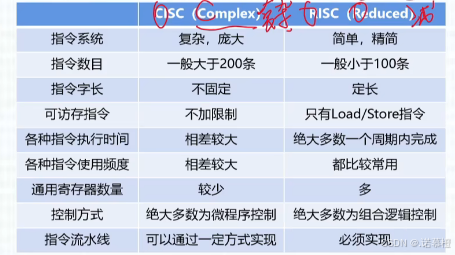
(2)特点补充:
CISC不适合指令流水、RISC适合指令流水。RISC寄存器多、CISC寄存器少、指令执行时间RISC在一个周期内完成、CISC不规定
19.
指令流水(考相关计算)
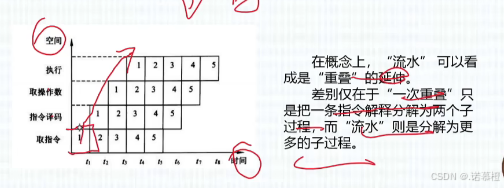
(1)指令的控制方式有顺序、重叠、流水三种
(2)指令流水就是把指令分解为多个子过程,在同一时间计算机
并行
执行不同指令的某一个子过程。
20.
指令流水相关计算:
若把一条流水指令分为取指令、分析、执行三个步骤,所需时间分别为2ns、2ns、1ns。则求解下列问题:
(1)
流水线的周期
是多少?
流水线的周期 = 分解的步骤里最长的一段MAX
∴流水线的周期 = 2ns
(2)
100条指令全部执行完成所需要的时间是多少?
n条流水线时间计算公式 = 1条指令执行时间 + (n条指令条数 - 1)*流水线周期
∴100条指令时间 = (2+2+1)+ 99 * 2 = 203ns
(3)指令流水线的
吞吐率TP
:

∴TP = 100 / 203
(4)
流水线的加速比 S :
∴ S = 100 * 5 / 203
21.I/O技术(特指
CPU
与
外设
的
数据传输方式
)
CPU与外设的数据传输方式:
(1)直接程序控制方式:
必须在CPU的程序控制下完成
。
分为两种:无条件传送和程序查询传送。前者顾名思义,后者是CPU先查询外设状态,等外设准备好以后再与CPU交换数据。
(2)中断方式:
也需要CPU完成,但CPU无需等待,
也无需查询外设状态
。
需要CPU的时候触发中断让CPU与外设交换数据,其余时间CPU可以干别的事,
系统效率很高
。
(3)DMA方式:即直接存储器存取方式。
让
主存与外设直接传输
,
与CPU无关
。
(4)IOP方式:
专门安排一个IOP处理机
完成外设与主机的数据交换。不常考。
1.3存储系统、总线系统、磁盘列阵技术及可靠性
1.
存储系统(层次结构):
2.层次结构中的
两套系统:
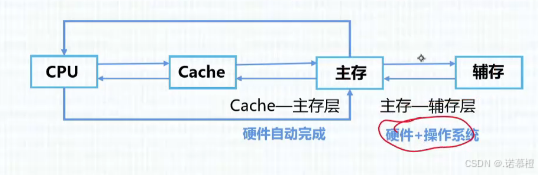
主存——辅存:
实现虚拟存储系统。
解决了主存容量不够的问题。在这个系统中,
操作由
硬件+OS
完成。
Cache——主存:
解决主存与CPU速度不匹配的问题。
意思就是主存太慢了,CPU太快了。所以主存的读取跟不上CPU读取速度为此诞生了Cache,Cache速度更快,把CPU要用的主存里的一部分数据先装入Cache,CPU要用的时候不直接访问主存,而是访问Cache。操作由
硬件自己
完成。
(重点,后面还会讲)
3.存储系统的
分类
:
(1)按
位置
分类:分为
内存(主存)
和
外存(辅存)。内存放要用到的数据和程序,外存存用不到的数据。
(2)按材料分类:磁存储器(磁盘磁带磁芯磁炮)、半导体存储器(根据所用元件分为双极型和mos型、根据是否需要刷新分为静态和动态)、光存储器(磁盘存储器)
(3)按工作方式:RAM(R/W)可读可存数据、和ROM(R)只读
(4)按写入方式(都是只读的):
ROM(放BIOS和微程序控制,只读)
PROM(可编程ROM,一次性写入不能修改)
EPROM(可擦可写入,
紫外线擦除
)
EEPROM(可读可写可修改,上电不丢失,
电擦除
)
flash(速度介于eprom与eeprom之间,可以
电擦除
)
4.
(重头大戏,必考)
Cache
(1)
Cache的组成:
存储器部分
和
控制部分
。
第一部分:存储器部分。
存放主存中
部分信息
(
不是主存的扩展,没有新内容!
)
第二部分:控制部分。
用来判断CPU要访问的信息是否在cache中。若在,则为命中。反之没有命中。
(2)
Cache的地址映像:是
主存
的信息进入
Cache
的办法。
通过把主存中的地址
映射
到Cache存储器中的地址,
映射有
三种
方法。
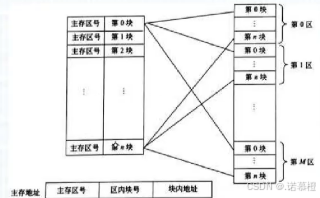
第一种:直接映像
地址变换简单,但不灵活
第二种:全相联映像
非常灵活,但地址变换复杂,速度慢
第三种:组相联映像 (第一种和第二种的折中)
5.
Cache的性能分析
关于命中与没有命中,CPU命中Cache,则缩短了访问时间,没有命中,则CPU需要自己去访问主存,时间相对较长。现在设命中率为H,Tc为 CPU到Cache的存取时间,Tm为CPU到主存的访问时间。试求
等效时间Ta和
使用Cache与不适用Cache提高的速度比r?
访问等效时间 Ta :
H * Tc + (1-H) * Tm = Ta
使用Cache与不适用Cache提高的速度比 r :
r = Tm / Ta
6.
主存的扩展(计算要会)
现有一片 8 * 4 的存储器,8指的是容量/个数,4指的是4位。8*4就是指8个4位。可以进行
位扩展
和
字扩展

多少K个地址单元:
内存地址差值:C7FFFH-AC000H
+1 = 1C000H = 114688D
地址单元个数:114688D / 1K(1K就是1024D) = 112D
因为地址按字编制 ,所以内存大小是114688D *16 bit = A(记这个值为A)
28 * 16 * 1024 * 每个芯片存储单元存储位数 = A → 位数= 4
7.
虚拟存储器(实际内存空间 > 内存物理空间)
(1)组成:
是一个存储系统。
由主存、辅存、存储管理单元、OS中的存储管理软件
(2)意义:虚拟存储器使得存储系统
既大又快
(大如外存,快如内存)
8.
磁盘存储器
好久没考过了
(1)有磁头磁盘,磁盘有扇区和磁道。
(2)
寻道时间 = 磁头摆到磁道的时间+磁盘转到相应扇区的时间
(3)可以组成
磁盘列阵
9.总线系统
分类:分为片内总线(内部总线)、通信总线(外部总线)和系统总线。
(1)片内总线:是芯片内部的总线。是CPU内部
寄存器与寄存器
、
寄存器与ALU
之间
的公共连接线。
(2)通信总线:
计算机 与 其他设备
的总线。如USB接口
(3)系统总线:CPU、IO、主存 之间的总线。
按系统总线传输信息的不同又可分为:
数据总线、地址总线 和 控制总线
。
10.磁盘列阵技术 RAID
会考RAID的等级(背)
(1)定义:RAID是外存子系统
(2)组成:多个磁盘存储器组成
(3)等级(背):

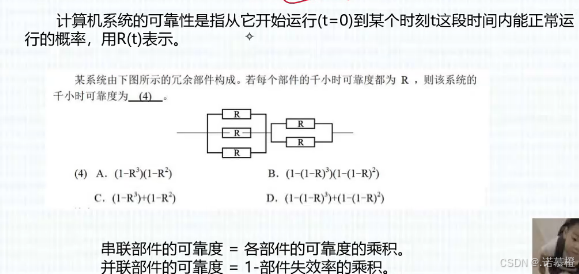
11.计算机可靠性
就是考公式
(1)定义:计算机可靠性是指从t=0运行到某个时刻能正常运行的概率R(t)。
(2)计算:一张图秒杀↓
第二章 数据结构与算法基础
1.考点囊括:

2.注意:这一张考的比较多,下午题也会考一道的,下午题比较难
2.1数据结构与算法 基本概念
1.什么是
数据结构
?
答:要先回答这个问题,需要先了解以下几个名词的释义
(1)
数据:
是信息的载体,计算机加工的原料。
(2)
数据元素:
是
数据的基本单位
,一个数据元素由多个
数据项
组成
(3)
数据项:
是
数据元素
不可分割的
最小单位
(4)
数据结构:
数据结构是相互之间存在一或多种特定关系的
数据元素的集合
。
举例:
学生信息是数据元素,每一个数据元素包含身高、体重、性别、生日等不可分割的最小单位。学生信息是数据元素,包含的身高体重等是数据项。一个班的学生信息按特定关系,如按照学号顺序排列,这样的一个数据元素之间按某种特定关系组合的学生信息的集合,被称为数据结构。
2.数据结构三要素
(1)
数据结构三要素是指
:逻辑结构、物理结构(存储结构)、数据的运算。
(2)
逻辑结构
是数据与数据之间的关系,是抽象的。
物理结构
是数据如何在计算机中存储的,是具体的。
数据的运算
顾名思义,数据需要经过处理(运算)。
(3)
逻辑结构(数据元素的逻辑结构):集合、线性结构、树形结构、图结构(网结构)
(4)
物理结构(存储结构):顺序存储、链式存储、索引、散列(哈希hash)
3.什么是算法?
程序 = 数据结构 (数据的预处理:把数据排成一排、串成一串)+ 算法(按需求对数据增删改查)
算法的特性:有穷性、确定性、可行性、输入(可以是0个)、输出(必须至少有一个输出)
4.算法效率的度量
算法有好有坏,有的算法效率极低,算的又慢,还占存储空间,所以用两个指标度量算法的好坏:
时间复杂度和空间复杂度
时间复杂度:
忽略最高项系数

空间复杂度:只需关注存储空间大小与问题规模相关的变量
Sn = On空间复杂度=递归调用深度
2.2线性表、栈与队列、串、数组、矩阵、广义表
1.
线性表:(逻辑结构)相同
数据类型的数据元素的
序列
(
学习一种数据结构,主要以三个方面进行学习,分别是逻辑结构、存储结构和数据的运算
)
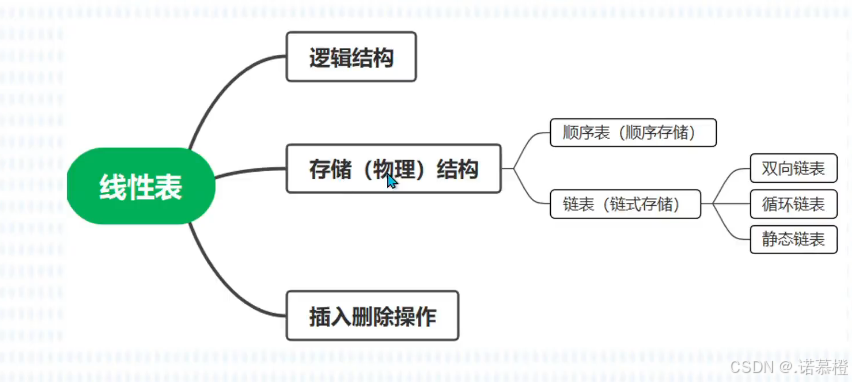
2.
线性表的存储结构
(1)顺序表:顺序存储结构,类似数组
(2)链表:单链表、循环链表、双向链表
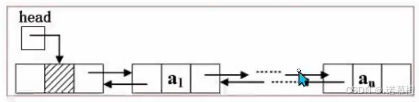
读:顺序表
优
;
增删改:链表
优
;
查:一样
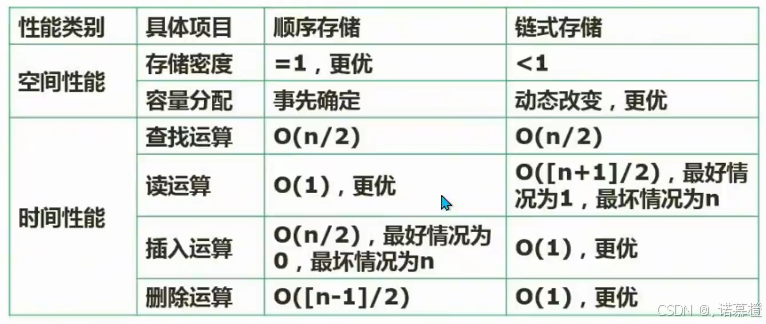
第三章 操作系统
操作系统软考考点分为四个管理:
进程管理、存储管理(内存)、设备管理(主要是IO)、文件管理(外存)




3.1进程管理
1.OS概述:
- 定义:有效组织、管理、分配系统中的软硬件资源,合理组织计算机工作流程,控制程序,并且向用户提供一个良好的工作环境和友好的接口。
- 三大作用:
2.OS分类
- 批处理OS:分单道批处理和多道批处理。就是一个一个做。工业有应用,如炼钢厂。
- 分时OS:普遍应用,CPU分时处理。
- 实时OS:嵌入式应用,需要实时的数据反馈。如买机票。
- 网络OS:便于共享网络资源,如客户端服务端。
- 分布式OS:现在比较火,意思就是物理位置在天南地北,但是逻辑上是一个整体。
- 微型计算机OS:Windows、Linux(糅合上述OS特征)
3.进程组成与状态
- 进程:运行着的程序。程序是静止的,进程是动态的。
- 进程的组成:数据、代码、PCB(系统给进程的唯一标识,也叫ID)
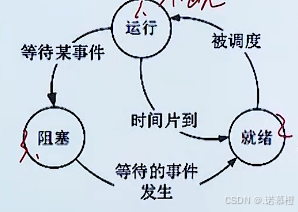
- 进程三态图:
- 运行:什么都有,在工作;
- 就绪:资源准备好了,缺CPU等CPU到来;
- 阻塞:资源没有准备好,缺CPU+资源
- 三态转换:因为现在的计算机OS大都采用分时OS,有很多个进程需要轮流执行,当运行的进程结束时(时间片到),需要让出CPU给下一个进程,这时刚刚结束的进程从运行态→就绪态,下一个进程从就绪态→运行态。所以运行和就绪可以相互转化。如果在某个进程运行的过程中需要键盘的输入,此时会触发一个中断,CPU不会等你,它会跑去执行下一个进程,那产生中断的那个正在运行的进程会从运行态→阻塞态。当键盘输入以后,这个进程的资源准备就绪,就差CPU了,就会从阻塞态→就绪态。排队等待CPU。
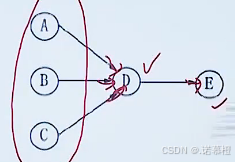
4.前驱图:一种依赖关系。
如下图:ABC可以同时执行,只有当ABC同时执行完成才能执行D进程。
5.进程资源图:
反应
资源个数和进程
之间的分配和请求。
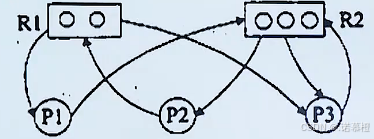
直接看考题:

[分析]
资源R箭头出去的,表示资源已经分配出去了,要减去。资源R箭头进来的,表示某个进程在申请资源。如果有资源,则分配出去,R减一。但如果申请不到,就是R资源为空时,进程无法满足运行条件,产生阻塞。如果系统中每个进程都处于阻塞,此时整个系统发生死锁。当某个非阻塞节点满足运行的条件时,也就是就绪状态,那么当该进程运行后,会释放。
6.进程的同步与互斥(难点)
- 临界资源(独占资源,只能互斥访问。指同一时间只能被一个进程调用):是各进程之间互斥访问的资源。
- 临界区:是一段代码。是进程对临界资源操作的那段代码。
- 互斥:临界资源在同一时间只能由一个任务单独使用。如打印机
- 同步:多个任务并发执行,但有速度的差异。在一定情况下需要等待。如三个人同时从北京到上海去,一个人骑自行车、一个人走过去、一个人开汽车过去。先到的要等待晚到的。
- 互斥信号量:使用互斥信号量后其他进程无法访问,初值为1
- 同步信号量:对共享资源的访问控制,初值为共享资源的数量
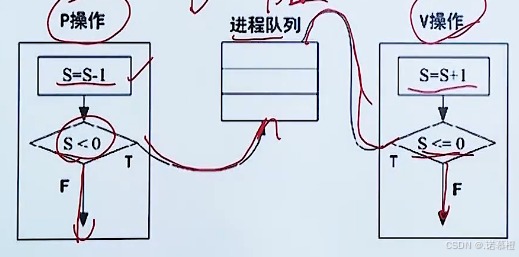
- PV操作:波兰源语,迪杰斯特拉提出。
- P:申请资源。P操作后(设信号量为S):S = S-1;当S≥0时,表示资源数量;当S<0,进程阻塞。S表示阻塞资源的个数。注意:P操作后资源必须 -1 ,表示执行了P操作。执行完S=S+1后判断是否S<0,如果成立证明有阻塞进程,把阻塞进程放入进程队列。如果不成立,则P操作end。
- V:释放资源。S = S+1;然后判断是否S≤0.如果成立表明有阻塞进程,则把一个阻塞进程从进程队列中取出。如果不成立,V操作end
6-1.生产者消费者问题(PV经典问题1)
- 仓库是互斥资源,同一时间只能被生产者或消费者之一使用。
- 现有三个信号量:
- 仓库使用权(互斥资源,“仓库钥匙”):互斥信号量S0;
- 仓库空闲个数(针对生产者,“空货架”):同步信号量S1;
- 仓库商品个数(针对消费者,“消费品”):同步信号量S2
注意:互斥信号量必须
成对使用
。在同一个进程中执行多少个P就要释放多少个V。
生产者流程:
P(S0);P(S1);生产;V(S2);V(S0)
消费者流程:
P(S0);P(S2);取走;V(S1);V(S0)
7.进程调度
- 定义:指当有更高优先级的进程到来时对CPU的仲裁,分为可剥夺和不可剥夺。可剥夺是指:当优先级高的进程来了,CPU立即停止正在运行的进程转而执行高优先级进程。
- 三级调度:高级调度(作业调度到)、中级调度(进程调度到内存,以便参与竞争)、低级调度(进程调度,在内存中的哪一个进程占用CPU)
- 调度算法:FCFS、时间片轮转、优先级调度、多级反馈调度(FCFS+时间片)
- 死锁:一个进程在等待永远不可能发生的事件(进程死锁),如果进程死锁多了,那么系统就会死锁(系统死锁:指不可化简)
- 死锁的四个必要条件:资源必须是互斥的、每个进程都占有资源并且在等待别的资源、系统不可剥夺进程资源、进程资源图不可化简(成环)
- 死锁的解决办法(破坏四大条件):
- 死锁预防(事前):限制进程对资源的请求
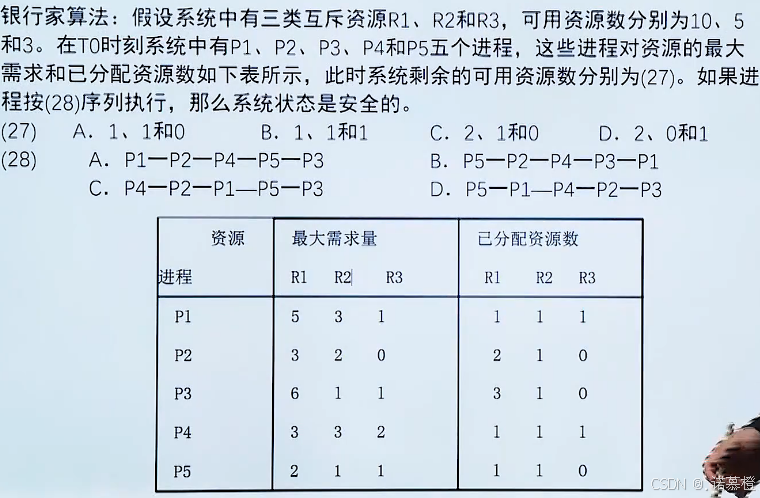
- 死锁避免(银行家算法):通过习题来认识
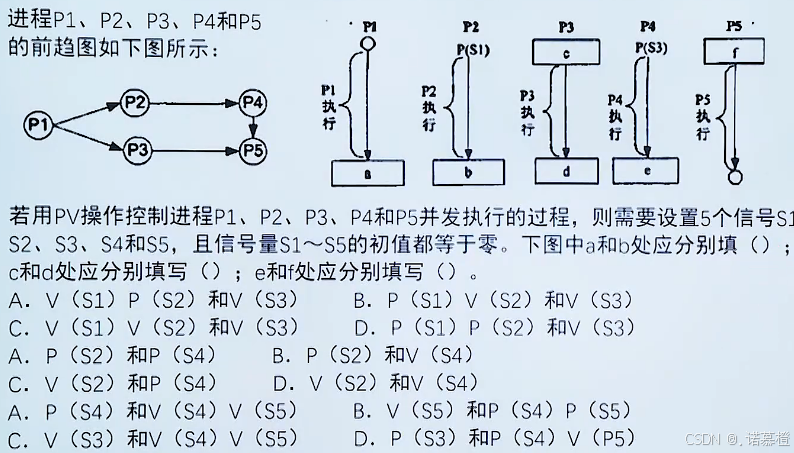
8.线程
(1)线程和进程区别?
进程:
可以被调度的最小单位、有资源
线程:
可以背被调度,但
没有共享资源(只有自己的一点寄存器、栈、PC等必不可少的资源、TCB线程控制块)
一个进程可以创建多个线程并共享进程的资源。此时需要加
锁机制,避免数据变乱
3.2存储管理
1.存储管理(对内存的管理)
:分区式存储、
分页式存储
、分段式存储、段页式存储
2.分区式存储(整存)
(固定分区——内部碎片;可变分区——外部碎片;可重定位分区——没有碎片)
缺点:内存空间不够分、有碎片
3.分页式存储(部分存取)
把接下来需要用到的程序拷贝到内存,用完了再拷贝出去。
(1)分页式存储:
把物理块号和逻辑页号
等分成大小相同的页。
软件的逻辑地址分页,每一页叫
页
;内存的物理地址分页,每一页叫
页框、物理块。
所以分页式存储就是
逻辑地址(软件自动分页、编号)和物理地址的
转换
(2)页的结构:设页内地址有n位,则2^n表示
页的大小。
(因为n位页内地址可以表示2^n个地址).页号有m位,则
2^m表示一共有 2^m
页

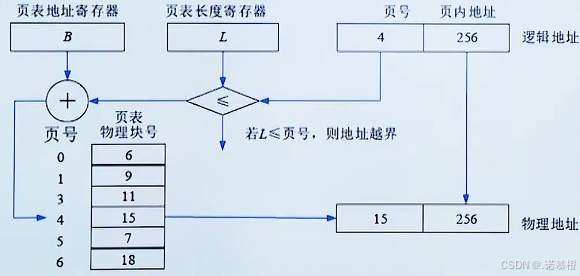
逻辑地址→物理地址:
页内地址不变(因为页和页框大小相等);页号要变(因为软件逻辑地址是自己自动编号的,但是放到内存中去不一定一样),要查
页表
。
注:页表(记录页和物理块的对应关系,题目会给出)
(3)页面置换算法
(当页表被装满,需要置换一部分物理块号)
LRU算法:最近最少未使用
OPT最优算法:理论上完美,实际无法执行
FIFO算法:先进先出,有可能页表越多,缺页率越高
淘汰原则:(1)最近最少未使用(2)最近未修改
(4)快表(在Cache里)
:页表(在内存中)里访问最多的页号提取出来放快表里
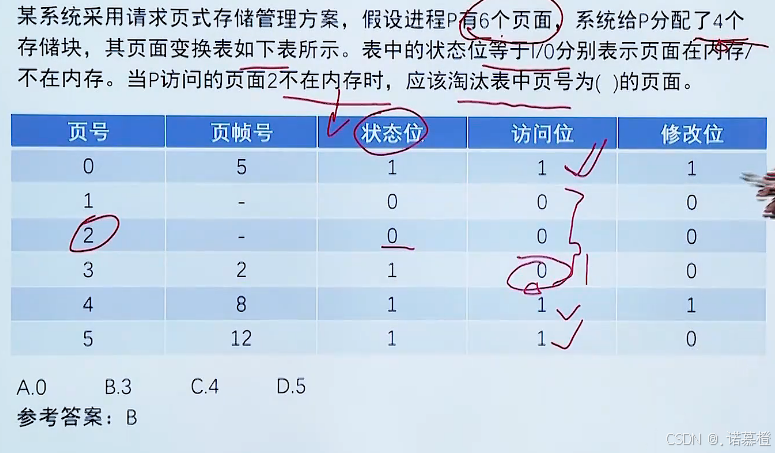
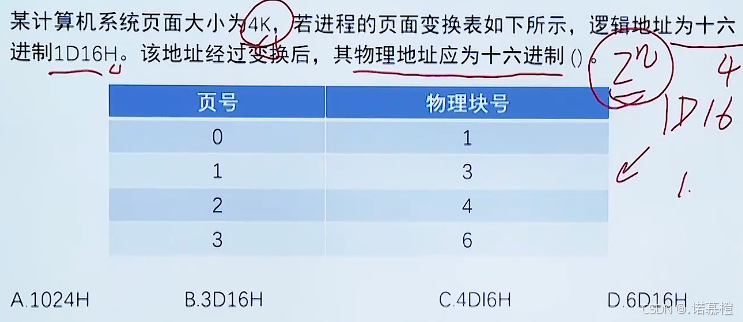
习题:
4.分段式存储(部分存取,按段分,
段大小不相等
)
因为分页式存储可能
导致统一程序被分在不同的页。
所以会频繁调取页。分段式存储是
按逻辑分段
(同一程序放在同一段)
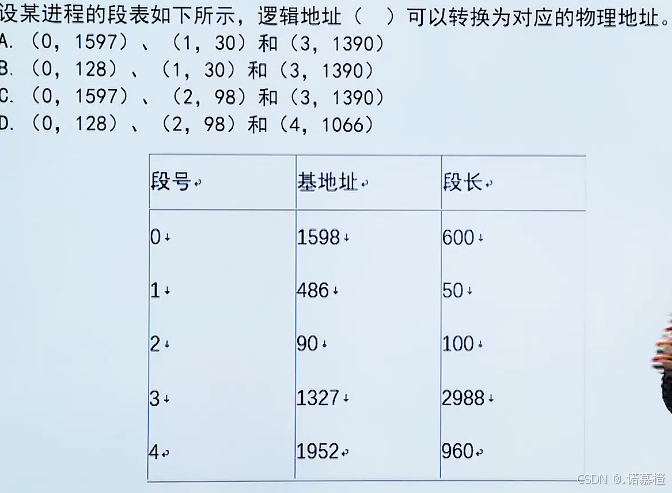
5.段页式存储:先分段后分页,了解了解 不考
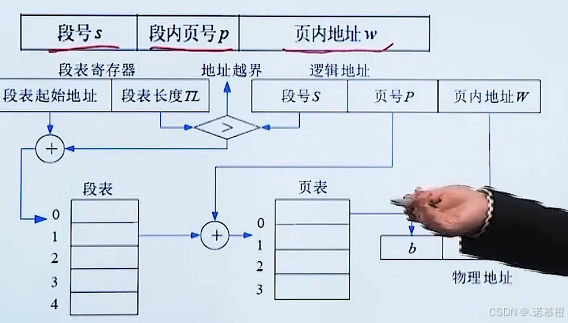
3.3设备管理
1.设备:io设备
2.spooling技术:独占设备→转化为共享设备
3.4文件管理
1.文件管理(针对外存,如word、execl)
2.(考点 考计算)索引文件结构
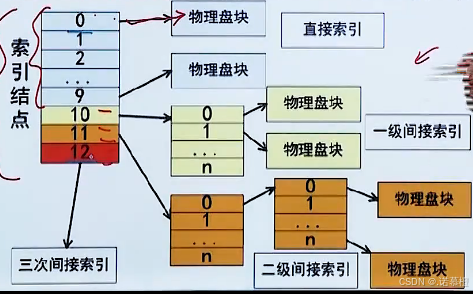
设物理盘块大小4KB,有13个
索引
,也称
地址项
(里面放内容),0-9直接索引。索引的集合成为
索引节点
直接索引:所有直接索引共计可存
4KB * 10 = 40KB
数据
一级间接索引:一级间接索引的索引阶段存放的不是直接的数据,而是存放
链接到物理盘块的地址
。设每个地址占4B,则一级索引节点共有4KB/4B = 1024个地址,对应1024个物理盘块,共计可存入
1024 * 4KB =4096KB
数据
二级间接索引:可存入
1024 * 1024 *4KB
的数据
三级间接索引:以此类推

3.文件目录
(1)路径要知道(
文件的路径不带文件名
)
绝对路径:从根目录开始的路径
相对路径:从当前开始的路径
全文件名 = 绝对路径+文件名
4.文件存储空间管理
规划哪些物理块可以被使用或不能被使用。考
位示图:
在外存建立
位示图
0空闲1占用。位示图的大小 (bit) = 物理块个数

第四章 数据库
分三块:基本概念、规范化并发、新技术(案例)
1.(常考)三级模式-两级映像
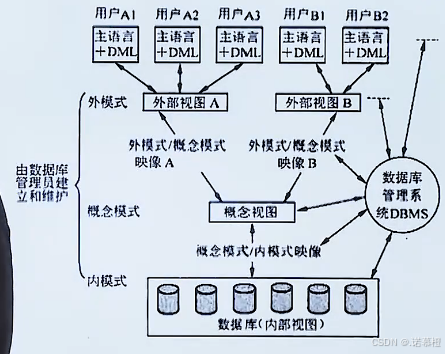
内模式 (1个):数据在内盘如何存储(数据结构)
概念模式 (1个):
又称概念模式,
基本表(可以crud)
外模式 (多个):
视图
(虚拟表,表的一部分,用来展现的,
无法修改
,人-计算机交互)
内模式-模式
映像:物理逻辑独立性
模式-外模式
映像:保证逻辑独立性
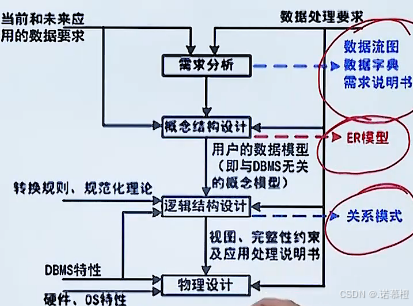
2.数据库设计
每一步对应
产出
如图所示
需求分析产出:
数据字典、数据流图、需求说明书
概念结构设计产出:
E-R模型
逻辑结构设计产出:
关系模型
物理结构设计产出:
数据库
3.数据模型三要素:
数据结构、数据操作crud、数据约束
4.数据模型(2种)
(1)E-R图
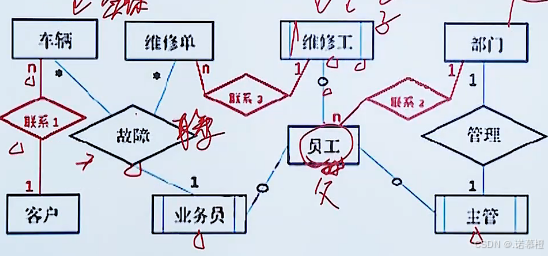
注:①矩形是实体E;菱形是联系R;椭圆是属性;
②实体有双竖线,表
子实体,没有则是
父实体。有父才有子,父子直接用带圆圈的线连起来。
③
强实体用一个矩形表示;
弱实体用矩形套着一个矩形表示;弱实体必须依赖于强实体的存在而存在。如学生是强实体,学生家长手机号是弱实体。没有学生,学校就不会存你父母手机号

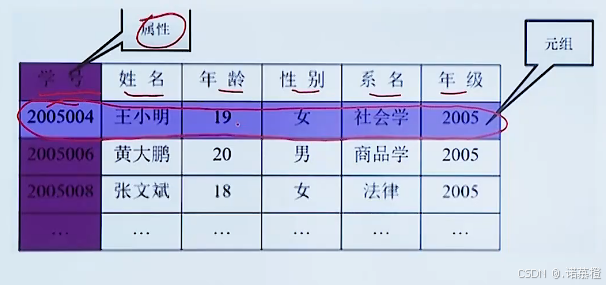
(2)关系模型(二维表)主流如oracle、MySQL,占90%
属性:学生的学号、姓名、性别、年级
元组:一组数据:(202211、蔡徐坤、男、22篮球2班)
关系就是表!!!
注意:
当E-R图转换为关系模型时,也就是实体联系图→二维表,(概念结构设计→逻辑结构设计)
有如下规则:
(1)一个实体
都必须对应
一个关系模式(学生表)
(2)联系:1:1联系
,可以放在任意一端实体中作为一个属性
1:N联系
,联系可单独建表,或在N端加入1端
主键
M:N联系
,必须新建一张表,主键是M与N的联合主键
解释:
1:N联系中,
如员工-部门联系,员工建一张表,部门建一张表。其中员工有几百个所以员工表有几百行,但是部分只有三个所以只有三行。现在他们之间有
部门(key为部门号)
这样一个联系,这个联系应该加在N端,即在几百行的员工信息的后面都加上一个部门号,而不是在1端后加N端,这样会导致从3行变成几百行。
M:N联系中,
如外卖小哥-外卖联系,其中外卖小哥key为姓名,外卖key为外卖单号。除了各自单独建表,因为他们的关系是多对多的,所以必须新建一张
送餐表
,包含各自的key,也就是
送餐表(
姓名,送餐单号
)
5.关系代数(
二维表S1
与
二维表S2
的运算)
交并差运算前提:列相同
代数运算:
①并(记录合并的)
②交(记录都有的)、
③差(S1-S2;记录S1与S2中
S1有但S2没有的;我-你 = 我有你没有的
)、
④笛卡尔积(S1 * S2):
不需要列数相同。
结果:列相加;行相乘
。用S1的第一行乘S2每一行并相加
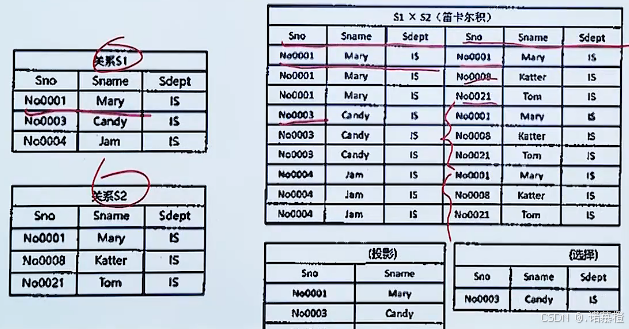
⑤投影(显示某表某列):
π
1,2
(S1)
,显示表S1的第一二列
⑥选择(显示某表某行):
σ
1='No0001'
(S1)
⑦自然连接(表与表操作):R⋈
S,
列取并;行取(
两张表中属性相同的属性 且 属性对应值相同的元组
)
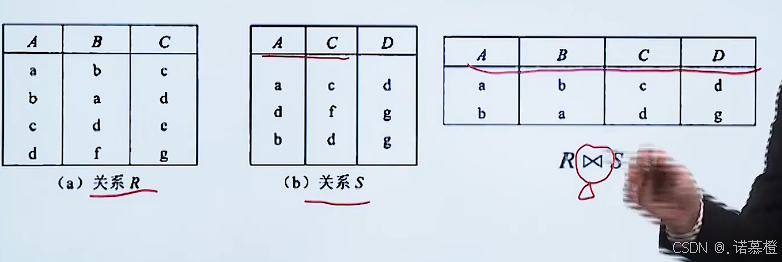
难点:笛卡尔积→自然连接的转换(要通过对笛卡尔积投影、选择 转换为自然连接)R⋈
S = f(π,
σ
)R*S
找效率高的:
对R × S里 R与S加单独的数据约束
6.函数依赖:
X确定Y(Y依赖于X):X→Y
部分函数依赖:
A或B或(AB一起)可以决定C,则部分函数依赖
传递函数依赖:
有A不等价于B,且A→B→C,则A→C,称为传递函数依赖
7.公理:要记忆

8.键与约束
- 候选键(多个):唯一标识的属性的集合(注意:这个属性可以是联合属性)选一个作为主键。
- 主键(一个):候选键之一
- 外键:其他表的主键
- 主属性:候选键属性的主属性的并集
- 实体参照完整性(主键约束):规定主键不能为空,不能重复
- 参照完整性约束(外键约束):可以为NULL
- 用户自定义完整性约束(自定义约束,如年龄大于18岁)
9.范式(描述 表/关系 的规范化程度)
- 核心:拆表
- 现有一张表:
- 学生(学号,学生姓名,系名,系主任,成绩,课程号)
- 有依赖关系:学号→姓名;学号→系名;系名→系主任;(学号,课程号)→成绩
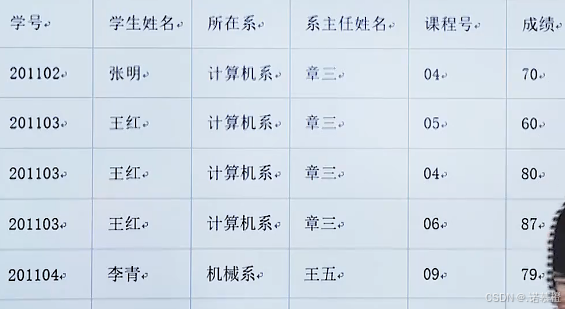
- 第一范式1NF:表中每个分量必须不可分
- 第二范式2NF:消除部分函数依赖。每一个非主属性完全依赖于任何一个候选码。也就是说表里面的依赖关系只有单函数依赖或传递函数依赖。没有譬如 AB→C,且A→C 这样的部分函数依赖。所以单属性作为主键的表至少是2NF。(因为在上述表中有(学号,课程号)→成绩,其中非主属性:成绩,由学号和课程号共同决定,但是成绩并不是完全依赖于候选码,所以他是部分函数依赖,不符合2NF。再举个例子:有关系模式R(E,N,M,L,Q),有函数依赖集F{E→N,EM→Q,M→L},根据候选键求法求出候选码是:(E,M)组合,而其中E和M又部分决定了N和L,不是共同决定的N和L,所以存在部分函数依赖。提一句:如果不存在部分函数依赖,则EM→Q,EM→L,EM→N,消除了部分函数依赖)
- 第三范式3NF:2NF基础上,消除非主属性对其他属性的传递函数依赖。如表:学生(学号,姓名,系名,系主任),其中非主属性系名决定了系主任,存在非主属性的传递函数依赖。所以要拆表,把系名系主任拆成一张表:系(系名,系主任)
- BC范式:3NF基础上,进一步消除主属性对码的部分函数依赖和传递函数依赖。所有的依赖关系的左边都必须包含候选键。举例:若有T→J;SJ→T,且候选键可能为(S,T)与(S,J)。显然第二种情况下T→J不满足BC范式的要求,需要改为ST→J才是BC范式。
- 候选键(候选码)求法:根据候选键可以推导出所有非主属性的性质,1.找不在右边的属性2.用右边没有出现的属性依次推导所有属性,如果能成功推导/遍历,则改属性集就是候选键。
- 保持函数依赖分解:大表拆成小表,保持眼来的依赖不变。举例:现有关系模式R(A,B,C),依赖集F={A→B;B→C;A→C},先有分解p={R1(A,B),R2(B,C)}。因为R1有AB,R2有BC,所以肯定A→B,C→B的依赖被保持了,但是A→C的依赖保没保持不知道,要通过算法计算。但是在软考中,一定选A→C不保持。再举个例子:

- 无损分解(两张表用定理,三张表用表格)就是表拆了以后还能拼成原来的。
- 定理法:当分解为两个关系模式时,如果R的分解为p={R1,R2},则p具有无损分解性的充分必要条件为:R1∩R2可以→(R1-R2)或(R2-R1)。注:相交就是相同的,相减就是前面有但后面没有的。
- 表格法:如果右边的表某一行全打钩,就说明是无损分解
并发控制:略,自学
- 封锁协议:略,自学
- 加锁原则:
- 读加读锁
- 写加写锁
- 读写之间加了读锁还能加读锁,但不能加写锁
- 读写之间加了写锁也不能加写锁和读锁
例题:

数据库的备份与恢复:
备份
有
静态转储
(要转储必须关闭服务,如任何对数据库的操作都被终止)和
动态转储
(你存你的,我修改我的——可以并发执行)、
海量转储
(全部转储)、
增量转储
(只转储更新后的数据)。
恢复
有
日志文件
(每次crud后的操作都被保存到日志里,需要恢复就借助日志回退操作)
(新概念1-2分)多媒体、数据仓库、数据挖掘:
数据仓库:
第五章 计算机网络&网络安全&知识产权
1.计算机网络
2分
+网络安全+多媒体=5-6分
2.出题点1:七层网络体系结构

3.TCP/IP(出题角度)
- 四层结构:应用层、传输层、网际层、网络接口层
- ARP与PARP的辨析:地址解析协议(将IP地址转换成物理地址) 与 反地址解析协议(物理地址→IP地址)
- TCP与UDP对比(记忆):
- TCP传输控制协议:是可靠的、面向连接的。
- UDP用户数据报协议:是不可靠的、无连接的。
- TCP有助于可靠性,UDP有助于传输的高速率性
- TCP保证数据到达,UDP不保证
- TCP面向字节流;UDP面向报文,没有拥塞控制。
- TCP只能点到点,UDP可以一对一多对多一对多
- TCP开销大,UDP开销小
4.IP地址和IPv6
1.域名:计算机主机名.本地名.组名.最高层域名(.com/.cn)
2.IP地址:主机地址用IP地址进行唯一标识
- IP地址长度:32位 两部分组成,分为4段每段8位。一部分位网络地址,另一部分位主机地址。举例一个IP地址:128.0.28.56 注:每段都在0~255中。
- IP地址分类:ABCDE类。A类第一个字段为网络地址,后三段为主机地址。B类前两段网络地址,后两段主机地址。以此类推。E类特殊:以1111开始,用于试验开发用的。注:以上分类称为IPv4网络。
- IPv6:解决了IPv4不够用的情况。
- IPv6长度:128位
- 记住一个地址:127.0.0.1
3.Internet服务(出题角度,记忆)
DNS域名服务:用UDP端口,端口号53
Telnet远程登录服务:用TCP端口,端口号23
e-mail电子邮件服务 POP3(收)和SMTP(发):都用TCP端口,POP3端口号110,SMTP端口号25
WWW服务:用TCP端口,端口号80
文件传输服务:控制连接
TCP端口21;数据连接
TCP端口20
第六章 软件工程
1.分值:8-10分
2.(贯穿整章)软件工程阶段:
需求分析→开发&设计&实施→测试→运行→维护
本章要点:生命周期、CMM、开发模型、开发方法、产品线、软件复用、逆向工程
3.(贯穿整章)信息系统生命周期:
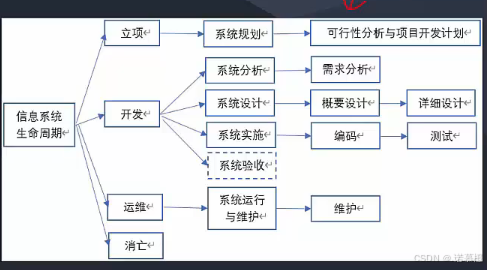
4.(考点)软件工程基本要素:
方法(面向对象等)、工具、过程
5.(考点)软件生存周期:
五阶段。系统规划、系统分析、系统设计、系统实施、系统验收、系统运维
- 需要达到的标准:每阶段定义是什么?产出是什么?
- 系统规划阶段:(能不能做)做初步调研,做可行性分析。输出:可行性分析报告、系统设计任务书
- 系统分析阶段:(做什么)也称逻辑设计阶段,是整个系统建设的关键。输出:系统说明书
- 系统设计阶段:(怎么做——做个沙盘出来)也称物理设计。分为详细设计和概要设计。输出:系统设计说明书(概要设计、详细设计说明书)
- 系统实施阶段:(真正做出来——把沙盘真正做出来)输出:进展报告、系统测试分析报告、程序员周报
- 系统运行、维护阶段:(查bug)产品不可能一直没问题,所以需要后期的维护
6.能力成熟度模型(CMM):衡量组织(公司)的能力级别

- CMM1级(初始级):多见于初创公司。软件开发依赖员工加班和英雄式的核心人物。成功不可复制(没有关键过程区域)
- CMM2级(可重复级):建立基本的管理过程与实践。可重复成功,按照准则来复制(关键过程区域:有项目管理最基本的监督、跟踪、策划、管理)
- CMM3级(已定义级):定性。管理与工程开发已经标准化、有文档有体系。(关键过程区域:同行评审、培训大纲、组件协调等趋于成熟的定性的管理)
- CMM4级(已管理级):定量。已定量管理,不但制定规则,还有详细量化度量标准了。(关键过程区域:质量管理、定量过程管理)
- CMM5级(优化级):没有最高,只有更高!越来越高!(关键过程区域:改革、革新、缺陷预防)
7.能力成熟度模型模型集成(CMMI):
适用于不仅仅软件的多工程学科和领域的框架。分为两种:阶段式和连续式。只说阶段式。


8.软件过程模型
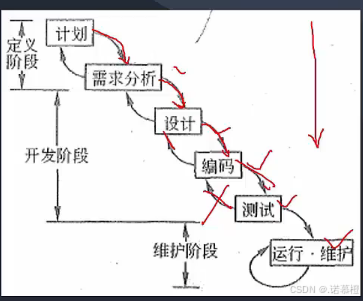
- 瀑布模型:(考点)需求明确、时间紧迫用这个
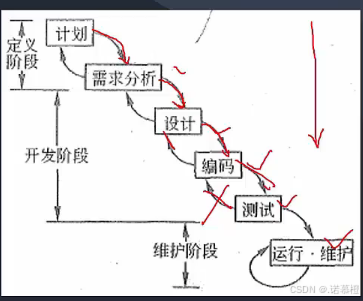
- 螺旋模型:(考点)风险分析。只要出现某某项目xxx...只要出现风险就选螺旋模型。适合大型软件开发
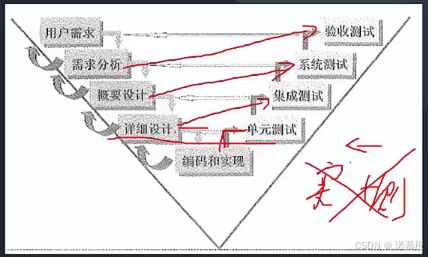
- V模型:强调测试重要。贯穿于系统开发的整个周期。
- (考点)强调测试、软件开发生命周期的阶段对应V模型的哪个阶段。主机关键字:单编、集详、系概、验需。(注:意思是生命周期的编码对应v模型的单元测试。)
- 原型化模型:(考点)适用于需求不明确的情况。比如用户要开发一款电商平台,但不清楚要什么样的,这种情况公司可以用PS等软件先画个界面出来给用户看看是不是要这个样子的软件。如果是就确定了需求。
- 增量模型:(考点)适用于时间、成本的制约。一般是先做个demo出来,再交付一下看看要改什么。然后在做个demo plus交付一下,循环往复最终敲定项目。(注:每次出demo,都是完成了一次软件开发的周期)
- 喷泉模型:(考点)出现面向对象就选喷泉模型
- 基于构件的开发模型(CBSD):(考点)事先包装好的控件直接拿来用,降低开发时间。选CBSD
- 形式化方法模型:基于数学基础。生成形式化的数学规格模型
9.信息系统开发方法

- 结构化方法(生命周期法):自顶向下、逐步求精、模块化设计、阶段化。
- 结构:系统由模块构成。模块之间的联系叫结构。
- 构成:由SA、SD、SP构成。S是structured;A是analysis;D是design;P是programming
- 对应生命周期:结构化方法的结构化分析对应信息系统生命周期的系统分析阶段;结构化设计对应系统设计;结构化编程对应系统实施。
- 特点:面向过程、面向数据流、设计时自顶向下(先设计大厦再打地基一层层做)、阶段化、模块化设计、逐步求精,类似瀑布模型,必须把需求敲定再做。是全局设计模块化实现
- 缺点:开发周期长(因为要按顺序一步步走,不能回头,做完了第一步才能做第二步)、难以适应需求变化、很少考虑数据结构不适合大规模
- 常用工具:数据流图、数据字典、结构化语言、判定树等
- 面向对象方法(Object-Oriented,OO):认为万物皆对象。自行车是对象,汽车也是对象。自行车、汽车的归类,也就是交通工具,归为一类,称为类(class)。
- 面向对象也分阶段:系统设计系统实施系统分析()但没有界限
- 面向对象方法的特点:复用性(定义的对象,以后大家可以重复使用)、普适性(仅面向对象方法具有。适用于各类信息系统开发)
- 缺点:单独一个面向对象不适用于大型软件开发,大型项目一般用面向对象和结构化方法一起开发
- 快速原型法:简称原型法,其实不是一种方法,而只是一种思想,只在系统分析阶段使用,适用于需求不明确。先搭建一个原型给用户看看是不是你想要的。必须与别方法结合使用
- 特点:周期短、成本低、风险低、以用户为中心、快速敲定需求
- 缺点:对管理水平要求较高(需要与用户反复交流)
- 敏捷开发:注重与客户交流,省略部分文档等与技术开发无关的东西。强调沟通,频繁发布demo,并且不断更新。适用于中小型企业开发。
- 敏捷开发的考点列举:
- 结对编程:一个人敲代码一个人审查
- 自适应方法:强调适应性(概念有点抽象,就不列举了,只需记得关键字会选就行)
- 水晶方法:不同项目不同策略,具体问题具体分析
- 特性驱动方法:快速迭代,简化、易用。适用于需求不断变更。
- 极限编程XP:人员沟通胜过文档
- 并列争球法SCRUM:把每次demo的迭代叫“冲刺”
- 统一过程RUP:
- 阶段:初始阶段→细化阶段→构建阶段件→交付阶段→初始阶段...
- 特点:用例驱动(根据真实的场景来指导编程)、以架构为中心、迭代增量(类似敏捷开发)

注:适用于大型软件开发的方法有:
螺旋模型、面向对象方法
10.软件产品线:是
产品集合
。
比如银行有很多业务,如信用卡业务、贷款业务等。为了信用卡这个业务,把很多功能集合在一起,如APP、小程序,都是为了这个业务而聚在一起的,有针对性。
就是给某个业务领域建立产品线。
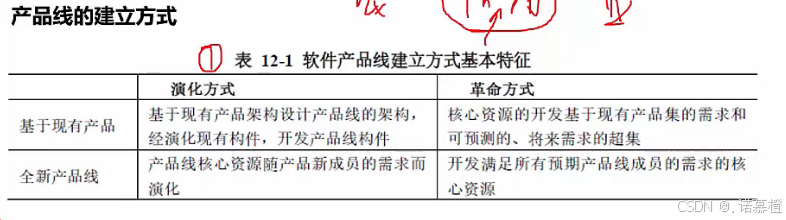
注:
关于上图,展示了某个业务建立产品线的四种方法,举个例子:基于现有产品的革命方法,有银行的一些业务系统,最开始是基于C语言开发的,但是随着时间的推进业务慢慢变多,代码也慢慢变多了,这时候C语言代码可能有千万行代码,比一个操作系统代码都多,这时候产品线需要用Java语言重构,需要革命。革命就是推倒重来,演化就是改革、修改。
11.逆向工程(下面的都会考)
软件复用:
已经有的软件拿来复用,有代码的复用(狭义),也有囊括开发经验、文档、设计、体系结构等一切有关的方面,都可以复用(广义复用)。
- 逆向工程:将软件的某种形式转换为更高级的抽象表现形式。比如给一个二进制bin文件,看看能不能debug一下变成C语言文件。就是看最终的可执行文件能不能还原出源代码。(现在逆向工程技术已经成熟,可以通过逆向工程推测出某个软件产品有没有抄袭的嫌疑。法律上规定超过45%的复用率被认定为抄袭,要吃官司)
- 逆向工程不仅仅可以用于还原源代码,还能还原出更高层次的建立程序的表示过程,逆向工程是设计的恢复过程。
- 实现级:反应程序咋写的。代码级,完备性高,抽象级低
- 结构级:反应程序依赖关系、数据结构、结构图
- 功能级:反应数据与控制流模型
- 领域级:甚至可以反应出E-R模型,完备性最低,抽象级最高
- 重构:在逆向工程的基础上(因为逆向工程可以还原,并且还原可以分等级)通过还原出的产物,如代码,通过重构我重新写一遍。
- 设计恢复:对已有程序抽象出数据设计、总体结构设计等信息
- 再工程:再工程是逆向工程后,再重构后的新版本
- 正向工程:在现有系统中恢复设计信息再用该信息修改或重构已有系统,改善质量(内心ps:这tm的都要拎出来讲?)


软件开发工具:从需求分析到实施都是
软件维护工具:东西已经做出来了,包括
逆向工程、版本控制、再工程
软件管理工具:
评价、选择
12.需求分析阶段
系统规划→
系统需求分析(逻辑设计)→系统设计→系统开发→系统验收→系统维护
- 软件需求定义:不考,略。
- 软件需求分类(考点,易混):
- 业务需求(不是技术上的需求。不是技术人员提出的,是项目投资人、营销、策划提出的)比如做一个在线教育网站,要一个刷题库,要一个VIP充值入口。这些不涉及具体的实现,都是业务上的需求。如银行的信用卡业务。这些需求抽象层次较高
- 用户需求(用户具体需求,描述了用户希望系统干什么)一般通过问卷调查、访谈等方法确定需求
- 系统需求(技术人员能看懂的需求,又细分为三类):
- 功能需求:具体的软件功能,如每月15日定时通过数据库显示每个人的应发工资来陆续发工资
- 非功能需求:比如性能需求,如1s必须打开网页
- 设计约束:敲代码不能无拘无束的,比如显示的数字必须达到小数点后两位(精度要求)、系统必须可以在unix上跑
- 用一个例子阐明三种需求:
- 业务需求:做一个能发工资的APP
- 用户需求:做一个APP,可以发工资,每月15日核对好账目后,陆续发工资
- 系统需求:开发一款APP,三个界面,第一个界面是发工资界面,点击第一个界面的按钮自动初始化三个数据,第一个数据是日期,第二个数据是工资发放情况显示,第三个数据是实发工资(精确到小数点后两位)...第二个界面....
- 真题:答案ABCA

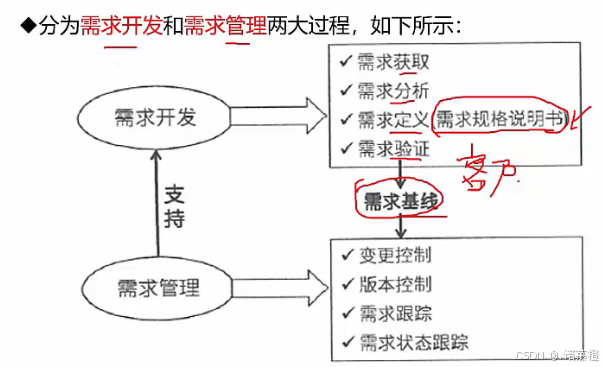
- 软件需求分为:需求开发 + 需求管理
- 需求开发包括:
- 需求获取(问卷调查、用户访谈、联合需求计划(各个代表组织开会)、采样(数学概念)、需求记录技术(记录))
- 需求分析(把杂乱无章的用户要求、期望转化为无二义性的、完整的、正确的用户需求)
- 需求分析这一阶段的任务:建立需求模型、创建数据字典、创建界面原型、QFD容错措施
- 分类:(重点)结构化需求分析,面向对象需求分析
- 结构化需求分析:
- 定义(需求规格说明书)、验证(用户过来评审)→需求基线→需求管理
- 真题:答案ADC

- 需求管理:如图
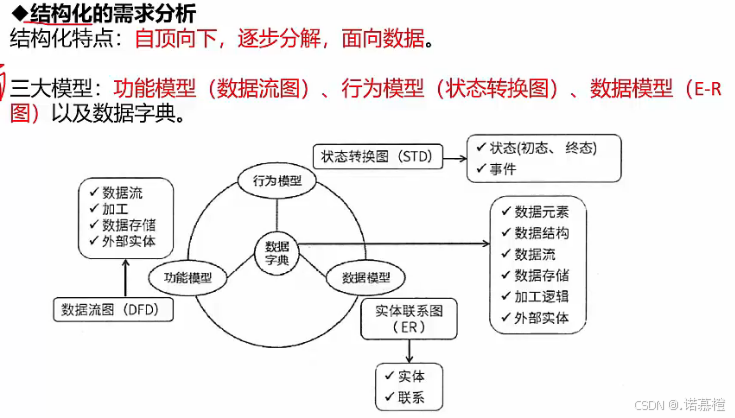
- 结构化方法的需求分析:
- 需求定义:产出软件需求规格说明书SRS。
- 需求定义的方法:严格定义法(预先定义法)和原型方法。
- 需求验证:也叫需求确认,和用户一起评审、确认需求准确无误。主要是评审SRS,要用户签字确认。
- 需求管理:略。见图
- 需求变更:主要考点:各步骤要注意顺序!
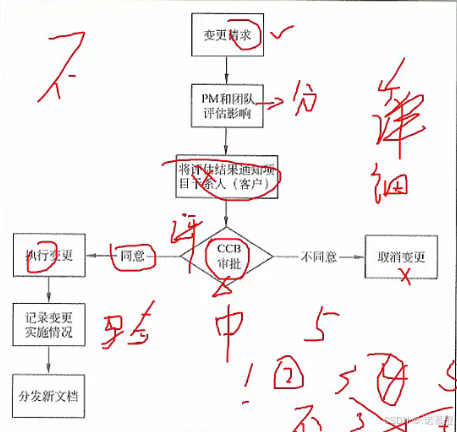
注意:
1.步骤可以少但不能颠倒顺序
2.核心是CCB,这个东西是一个委员会由公司骨干领导组成,一起审批。任何变更都有权决定
- 需求跟踪:双向跟踪(正向+反向。
- 正向跟踪(追溯):看看有没有少做需求。用户需求是否全部实现。
- 反向需求(回溯):看看最后的产品有没有多实现功能。
- 例题:答案:DBA

14.系统设计阶段
系统规划→系统需求分析→
系统设计(物理模型设计)→系统开发→系统验收→系统维护
- 考点:流程表示工具(常考)
- PFD图 (程序流程图):常写的复杂的结构图
- IPO图 描述输入输出数据加工的,类似与数据流图
- N-S图 :不适合复杂的
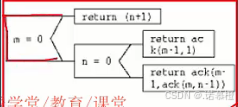
- (不常考,记个原则就行)业务流程重组BPR(是改革 相对不温柔):全部从头再来,相当于重新设计一个软件,走一遍软件设计的流程。基本原则要记:以人为本、以流程为中心、以客户为导向
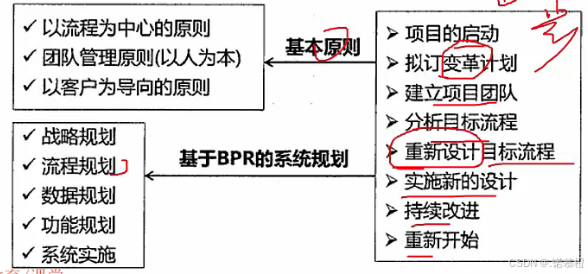
- (不常考)业务流程管理BPM(是改进 相对温柔)
答案ABA

- 系统设计(考点)
- 设计方法:结构化设计、面向对象设计
- 设计内容:概要设计(总结构设计)、详细设计(填充细节:数据库物理设计、UI界面设计、代码算法怎么写)
- 产出:概要设计说明书、详细设计说明书
- 系统设计原理:抽象化;自顶向下逐步求精;信息隐蔽;模块独立(要求模块内部高度联系;模块直接尽量独立)
- 系统设计原则:
- 模块不要过大过小,要适中
- 尽可能减少调用深度
- 多扇入,少扇出(扇入就是别人调用你;扇出你调用别人)扇入越多越好,说明你价值大;并且要少调用别人
- 例题:答案ABD

- 人机界面三大黄金原则:(考点)
- 置于用户控制之下
- 保持界面一致性
- 减少用户记忆负担
15.系统实施阶段——测试(找bug)
- 软件测试方法分为:静态测试、动态测试
- 静态测试:不运行程序来测试代码找bug。分为桌面检查、代码审查、代码走查
- 动态测试:运行程序后进行测试。黑盒测试(看不见代码,只是根据设计、测试软件bug。是功能性测试)+白盒测试(看得见代码,结构性测试)
- 测试阶段
- 单元测试1:测试模块。依据是软件详细设计说明书
- 集成测试2:测试模块之间的关系。依据是概要设计阶段
- 确认测试4:依据需求文档,一条条的需求是否都做好了。
- Alpha测试:用户在开发环境下测试
- Beta测试:完全真实测试
- 验收测试:走流程的,其实beta测试已经很详细地测试过了
- 系统测试3:自己内部测试的,测试性能的
- 回归测试:多见于发现bug后改正bug的阶段,测两个东西,第一个是测错误有没有改对;第二个还要看改完这个bug是不是影响到别人的功能了
例题:答案:CCAC

- 测试用例(考前两种)
- 黑盒测试
- 等价类划分:如学生成绩输出系统中,有优(90,100)良(80,90)及格(60,80)不及格(0,60)。只需输入几个数字测试几个就行不需要全部测试。如果输入-1就有bug这个bug称为无效等价类。测试需要把所有的无效等价类全部覆盖。
- 边界值划分:边界值是最大值最小值加上最大值最小值之外的最近的两个值。如年龄范围0-99.边界值就是-1,0,99,100
- 白盒测试用例:按照覆盖级别分级。
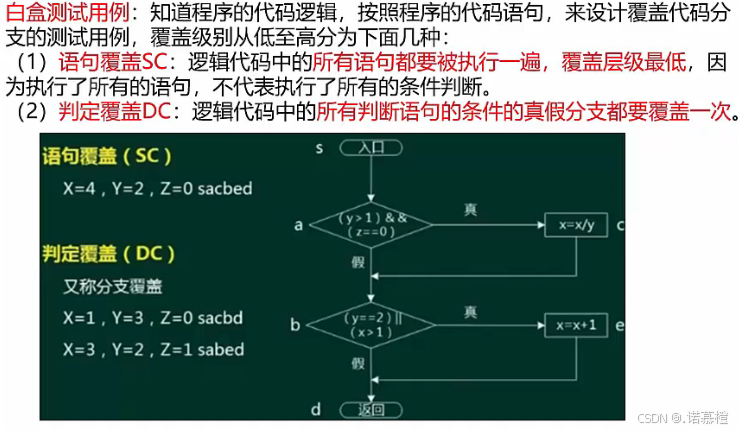
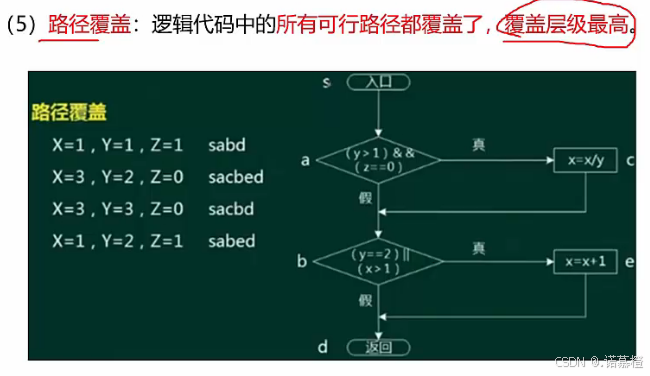
- 白盒测试笔记:
- 用一个案例说明一下覆盖:设True=1;False=0;

- 语句覆盖:所有语句都执行一遍(不代表执行了判断语句。走了真就肯定没走假)所以必须让A=1;B=1;C或D=1才能让两个if和两个Action全部执行。
- 判定覆盖(分支判断):所有判断的真假至少都要经历一次。注意到案例有两个if,所以会有00 01 10 11四种结果。因为只要让所有的判断都执行一次,所以只取两个if分别为真假(10)和假真(01)就能全覆盖。
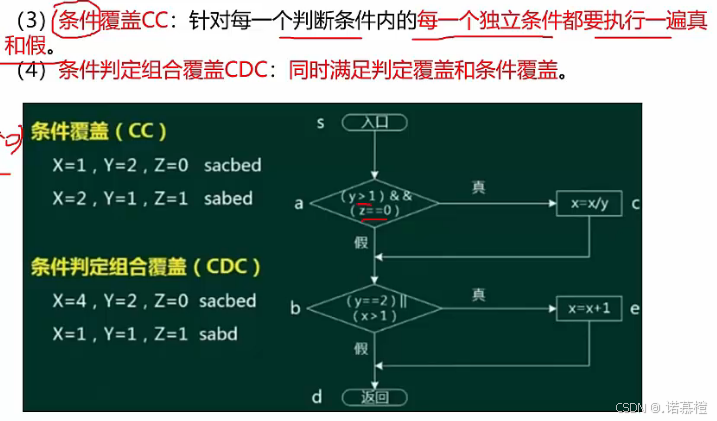
- 条件覆盖:每个判定的每个条件都要取真值假值。所以有ABCD8种取值。因为只需要保证每个判定里的每个条件都取一次真假。所以只要取ABCD=0000和ABCD=1111两种用例就可全覆盖。
- 判定条件覆盖: 每个if都要取真假;并且每个条件都要取真假。所以取:ABCD=1111和ABCD=0000即可满足。
- 路径覆盖:所有的路径都要走。(全覆盖)所以用例会取好多好多种
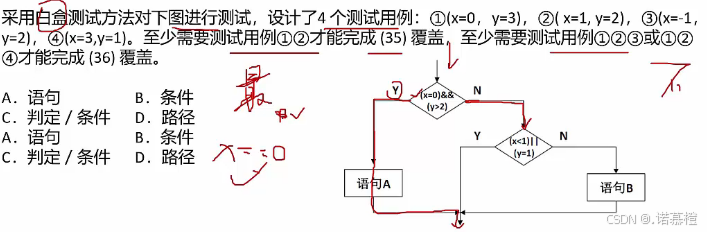
答案:AD
16.调试(找bug)
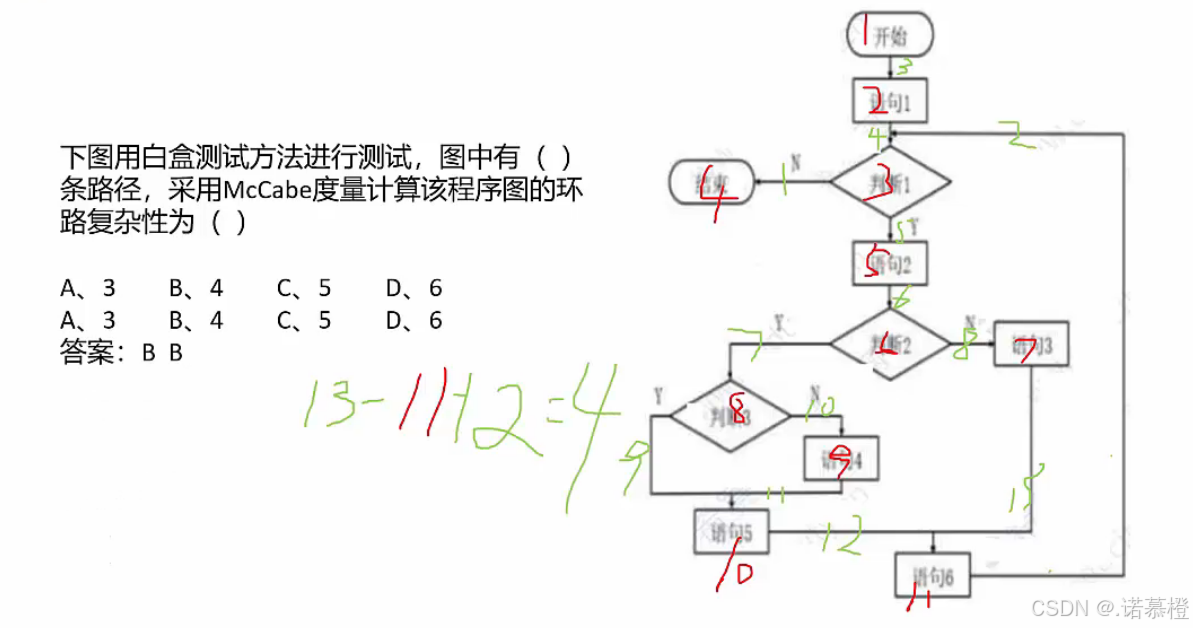
- 考点:软件度量中的McCabe度量法
- McCabe用来求环路复杂度,设有向图边数为m,节点数为n,则复杂度=m-n+2
软件维护补充知识:
1.软件维护需要投入的时间成本大,金钱成本也大,工作量也大
2.软件维护是开发各个阶段的关键目标
3.软件维护并不比开发简单
4.软件维护要解决软件从交付到消亡的所有问题
5.软件维护的完善性:对代码执行加个监控、加个小功能,改改算法等
改进。使得软件趋于完善
6.软件维护的适应性:如
数据格式变了,环境变了,需要修改软件
7.系统可维护指标:可理解、可测试、可修改

第七章 项目管理

软件工程是从技术的角度看项目,项目管理是从管理的角度看项目。
1.进度管理考的比较多。2-3分左右
2.范围管理:
- 范围是需求的边界,只做边界内的事情。
- 范围管理包括需求管理和变更管理。
- 5个过程:(记住顺序、5个工程是什么)
- 编制范围管理计划:纲领性文件,是界定、控制范围的计划。
- 定义范围:详细界定产品范围和项目范围(*),编制项目范围说明书。 注意:有输入:项目章程(启动文件)、编制范围管理计划、组织资产(如开发的模板)、已经批准的变更申请(CCB批准了的变更申请)。
- 工作分解结构:分解工作结构。把分解完的工作打包成一个个的工作包。(每个人要做什么讲清楚)
- 确认范围:验收成果
- 范围控制:看看有没有人做的事超出范围了
*:产品范围和项目范围(有考点)
- 产品范围:(就是产品到底要做什么,如具体软件)是项目范围的基础。
- 项目范围:(包含具体产品之外的,项目上的界定范围)如除了具体项目之外,还要界定如成本预算、人员调度等一系列项目上的范围要界定。判断项目范围时候完成,用范围基准衡量。
- 范围基准:由定义范围阶段的产出:项目范围说明书、WBS和WBS词典构成。
- WBS(工作分解结构):WBS将项目分解成工作包,可以具体到个人。为了确定边界
- 范围管理以工作包为最小单位

3.(重中之重:进度管理的计算)进度管理:
- 进度管理以活动为最小单位
- 活动是将工作包的再分解
- 6个步骤:

- (考点)cocomo模型:
- 用代码行计算工作量
- 这个模型分为三级:
- 基本cocomo模型:静态单变量模型:纯数代码行确定工作量
- 中间cocomo模型:除了代码行,还看别的因素
- 详细cocomo模型:更加细化,精确到每一步骤。
- cocomo2模型:也考虑除了代码行以外的多个因素
- 分为三个模型:但分别在三个不同的阶段
- 应用组装模型:需求分析阶段用,估算对象:对象点
- 早期设计阶段模型:设计阶段用,估算对象:功能点
- 体系结构阶段模型:开发阶段用,估算对象:代码行
- 分为三个模型:但分别在三个不同的阶段
- 进度安排常用图形:
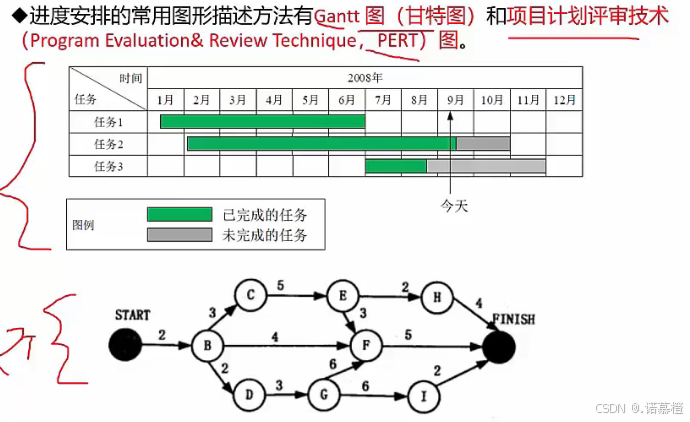
- 甘特图反应并行关系,不反应依赖关系
- RERT图不反应并行关系,但反应活动之间的依赖关系。
- PERT图里的圆圈是活动,箭头上的数字是时间。
- (重中之重)工具与技术——关键路径法
- 关键路径:指项目的最短工期,但是是从开始到结束最长的路径。
- 几个重要时间:也是考试会让你求的

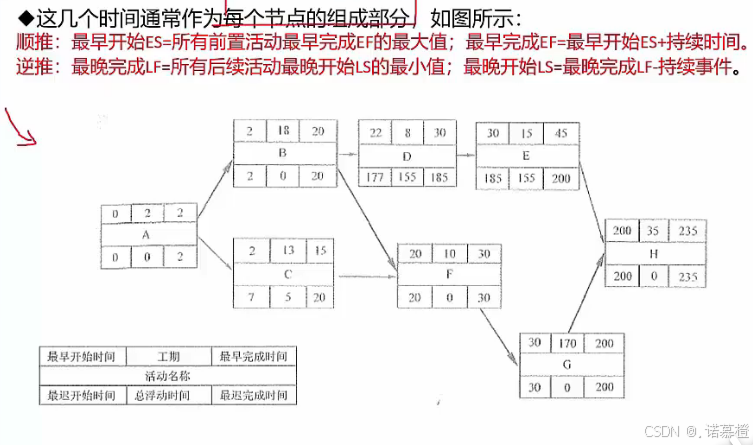
会让你求的东西:
1.项目工期=关键路径=最短工期=最长的那条路径
2.某个活动的最早开始时间(需要顺推):所有前置活动EF的最大值
3.某个活动的最晚结束时间(需要逆推):所有后续活动LS的最小值
4.某个活动的最早完成EF=ES+持续时间
5.某个活动的最晚开始LS=LF-持续时间
6.总浮动时间=不延误完工的可拖延的时间(关键路径上的活动的总浮动时间都是0)
7.某个活动的总浮动时间=LS-ES 或 LF-EF 或 关键路径(可以不包含某个活动)-非关键路径时长(包含某个活动的最长的那条)
4.成本管理
- 很重要,计算会考2-3分,下午题也会考
- 项目的成本管理包括:成本估算(要多少钱算一下)、成本预算(把要到的钱用掉)、成本控制(超了预算要控制)
- 成本的类型:
- 可变成本:随着工作量、工时的变化而变化,如材料
- 固定成本:不随工作量、工时的变化而变化,如房租
- 直接成本:(项目团队独有的)不需要分摊,(团队成员的)工资、物料设备
- 间接成本:(额外福利、税金、五险一金(因为一部分要公司出))要分摊的,如保洁费、额外福利、(总经理的工资、高管的工资应该由各部分分摊,是属于间接成本)
- 机会成本:如一块地,可以用来养猪或者种菜。如果养猪可以赚10万,养鸡赚8万,养羊赚12万。如果你放弃养羊选择养鸡,机会成本就是12万(所以机会成本就是:你放弃的里面最大的,不是已经有的)。如果实际收益>机会成本(你去养羊挣12万,机会成本就是10万)称为成功投资。
- 沉没成本:已经发生的成本,钱已经花了。
- 例题:答案AB

5.配置管理
- 配置管理:系统控制配置变更
- 配置项:可以量化的配置管理的对象,如代码、硬件、(已发布的,不是草稿)文档、说明书。文档需要配置,很有必要。比如经理拿到V2.0的版本,而开发人员还在V1.0,就会出问题。
- 配置项的状态:草稿、正式、修改
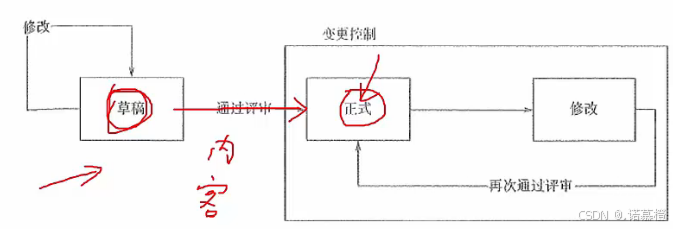
- 配置项版本号:草稿就是(V0.xx);发布(V1.x);修改(V1.1x)

- 版本管理(常考):
- 项目发布需要历经多次配置项的修改。
- 对配置项的任何修改都必须产生新的版本
- 新版本不一定就比旧版本好
- 所有的版本都会保存,旧的也不会丢弃

- 配置基线:(简称基线)
- 是一组配置项
- 这一组配置项构成了相对稳定的逻辑实体
- 是“冻结”的,不可随意更改,如需更改走变更流程(CCB审核)。
- 对应开发工程里的里程碑,一个产品有多个或一个基线
- 生命周期每个阶段结束都会定基线,定范围。比如设计阶段结束会定基线,对文档代码进行冻结,为的是不能随意修改随意推翻。
- 配置基线的分类:发给用户的(发行基线release,不含具体代码);内部开发的(构造基建buil
- d,含代码的版本)
- 配置基线的内容:基线的事件、配置项、程序、权限,每个基线都需要进行配置控制。
- 建立基线的好处:
- 方便开发(因为基线这个东西,它是一组配置项,配置项又包含代码。又因为公司有基线,公司团队也有基线。如某讯是公司,工作室某美是团队,公司的基线不能修改,团队的基线可以自己修改。团队可以拷贝公司的基线自己修改,意思就是可以把代码拷贝过来自己修改。这样大大降低开发时间)
- 别的不想写了...自己看

- 配置库:记录并且放置所有的受控的配置项(就是基线配置)
- 所有的demo、成品、各个版本都在里面方便管理员管理。
- 配置库的分类(常考):
- 开发库:也称动态库、程序员库、工作库。开发人员自己的库,自己管理,不需要配置控制。
- 受控库:也称主库。包含当前基线和变更基线。完全收到配置控制,不可随意更改,如需更改走变更流程。
- 产品库:也称静态库,发行库,软件仓库。包含已发布的各种基线、最终产品,不可随意修改
- 例题:答案ca

6.质量管理
考法:六大特性及其子特性
- 质量六大特性(常考):
- 功能性:功能是否齐全?完整吗?
- 可靠性:容错、成熟、可靠吗?
- 可用性:能不能用?好理解 好上手 好操作
- 效率(性能):1s要打开网页。
- 可维护性:能不能维护?
- 可移植性:安卓能不能移植到苹果?
- 质量保证的主要活动:软件评审
- 例题:答案BC

6.风险管理
- 风险:不能避开,无法消除。只能预期做工作减少风险带来的损失。
- 风险属性:随机性、相对性(投入越大风险越大)、可变性(可能会变化)
- 风险分类(常考的一种):项目风险(项目管理的风险,与技术没有关系)、技术风险(程序员,可能比较危险。会导致产品的质量)、商业风险
- 例题:答案CB

- 组织结构
- 看例题吧

第八章 结构化开发方法与面向对象开发方法
- 结构化开发方法(相当于面向过程开发方法)

- 系统分析与设计概述
- (名词回顾)信息系统生命周期的五个阶段:系统规划、系统分析、系统设计、系统实施、系统维护
- 系统分析阶段,结构化开发方法会(1)先根据已有的得出物理模型(2)再从物理模型中抽象出逻辑模型(3)优化逻辑模型建立新的逻辑模型(4)建立新物理模型(这一步在系统设计阶段)
- 系统分析基本原理:抽象、模块化、信息隐蔽、模块独立(衡量尺度:耦合性和内聚性)
- (必考2分)耦合性内聚性
- 模块之间要:低耦合,高内聚。
- 内聚是指模块内部各功能直接相互影响,耦合是指模块之间相互调用、输入输出
- 内聚的分类(必考)(内聚程度由低到高越高越好)
- 偶然内聚:巧合,无关系
- 逻辑内聚:如LED_on()和BEEP_on()都是逻辑相似,参数不同
- 时间内聚:模块内功能同时执行
- 过程内聚:模块内任务有先后顺序
- 通信内聚:有同种数据结构,相同输入输出
- 顺序内聚:必须顺序执行;前一个输出必须是下一个功能的输入
- 功能内聚:所有功能共同作用,缺一不可
- 耦合的分类(必考)(耦合程度由低到高越低越好)
- 无直接耦合:模块之间毫无关系
- 数据耦合:模块之间传递的数据值有调用关系
- 标记耦合:模块直接传递的是数据结构
- 控制耦合:A模块可以控制B模块某个功能
- 外部耦合:外部环境可耦合
- 公共耦合:公共数据结构
- 内容耦合:内容有关联,A模块可以跳转到B模块

- 系统总体结构设计
- 分概要设计和详细设计
- 原则:自顶向下、信息隐蔽、多扇入少扇出
- 例题。。。答案:AB(这块内容都是大白话,直接看例题就行)

- 结构化开发方法
- 结构化开发方法是面向数据流的适用于需求明确的开发。分为SASDSP三阶段
- 开发工具:C/C++
- 分析阶段产出:三大模型+数据词典。(三大模型:功能模型——数据流图;行为模型——状态转换图;数据模型——ER图)
- 数据流图DFD(大题第一题)
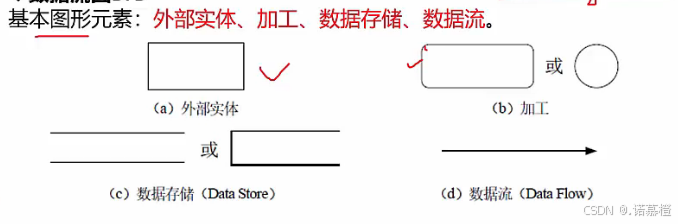
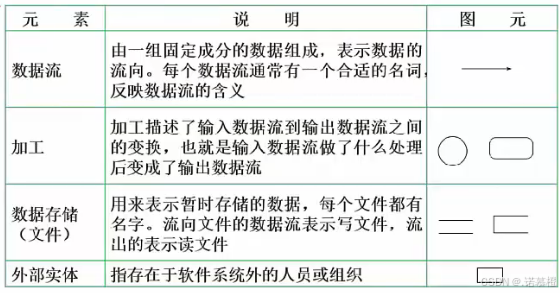
- 数据流的流向必须经过加工
- 加工:(必须有输入+输出)输入数据流到输出数据流之间的变换
- 加工有三种错误:奇迹(01 无输入有输出);黑洞(10 有输入无输出);灰洞(输入不足且无输出:给个客户地址经过加工就能输出客户账目表)大题里灰洞很难找到
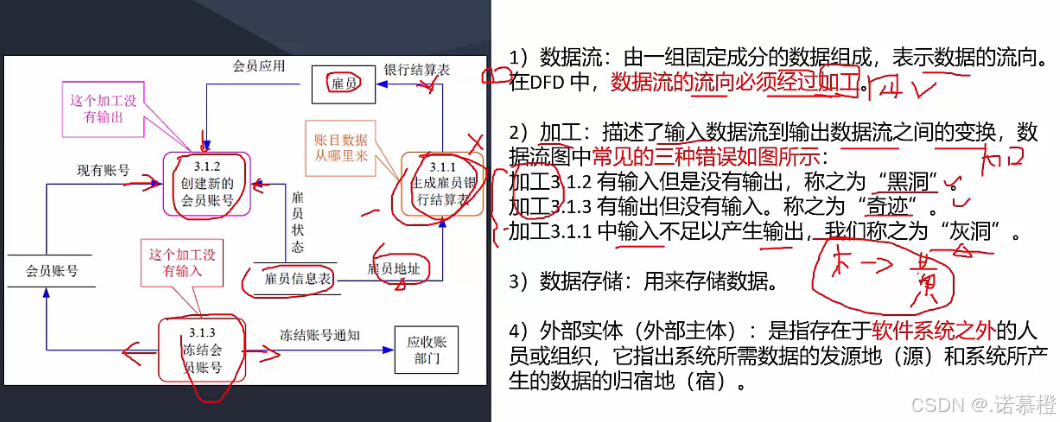
- 外部实体(选择题爱考):外面的实体
- 分层数据流图:数据流图可以分层的.顶层\0层\1层...\n层
- 后层的数据流图里的输入输出东西前面一定是有的
- 顶层图反应外部实体与系统之间的交互
- 0层图反应系统的扩展,扩展一些功能
- 1层就是对0层某个加工的细化(1层输入输出和0层一致)
- 一般来说考试只靠顶层和0层
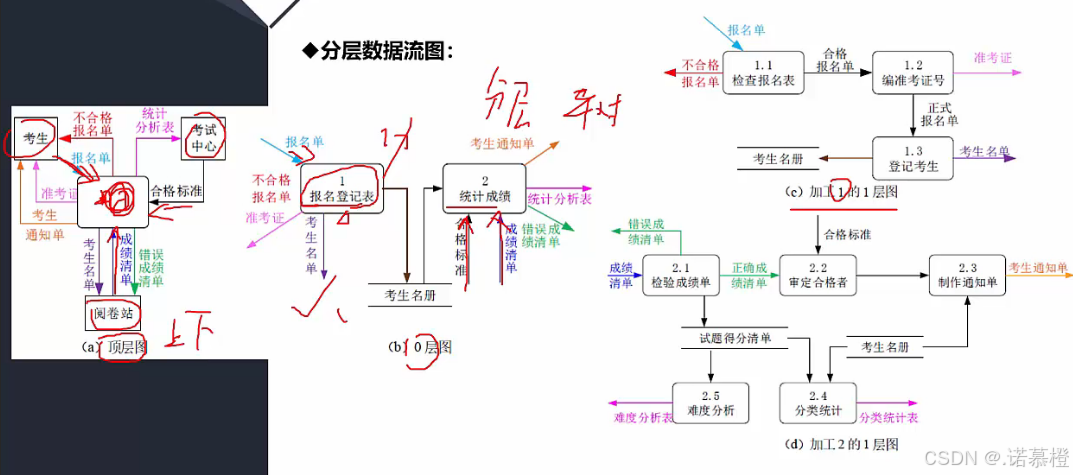
- 数据字典:因为数据流图只描述了加工与数据流走向,但没有对加工进行具体描述.所以数据字典就是对每个数据流、每个加工进行描述。
- 数据字典只描述4类(数据流、数据存储、基本加工、数据项)没有外部实体
- 加工逻辑:结构化语言、判定树、判定表
- 例题:答案BA

- 结构化设计阶段SD
- 结构化分析SA里最重要的就是ER图和数据流图
- SD阶段主要是将数据流图转换成系统结构图
- (常考)结构化设计主要包括
- 体系结构设计:架构设计
- 数据设计:与数据库相关、与ER图相关
- 接口设计:与数据流图有关
- 过程设计:与内部算法、内部结构等详细设计有关
- 例题:答案:AC

- WebAPP(从未考过)
- WebApp采用敏捷开发
- 略~~~
- 面向对象开发方法(考10分,但是考点固定)

- 对象:万物皆对象。生活中的万事万物都是对象。如医生。除了了解对象我们还应该了解对象的属性、对象的操作。如医生不仅是对象,他还有姓名、科室等属性;可以进行开刀、问诊等操作
- 类:类是对象的模板,对象是类的实例。意思就是说类是把几百个对象中所共有的共性抽象出来,称为类。分为实体类、(交互类、接口类)边界类、控制类三种。实体类:自然世界的实体;(交互类)边界类、接口类:二维码\显示屏这些;控制类:控制活动流,充当协调者.
- 封装:一种信息隐藏技术。把功能内部实现的代码封装起来,不让用户知道,只让用户通过接口调用这些功能。
- 继承:类之间的层次关系(子类和父类)。如父类是学生,子类就是高中生。子类继承父类的特性。
- 多态:不同对象收到同一消息出现不同结果.如A函数里有一个功能叫画图,可以画三角形.B函数中也有一个功能叫画图,可以画圆形.但是让AB画图,结果不同:一个画了三角一个画了圆.
- 多态的分类:
- 参数多态:不同类型多种结构类型
- 包含多态:父子类型关系
- 重载多态:函数同名但参数不一样
- 强制多态:强制类型转换
- 多态的分类:
- 接口:只说明操作是做什么的,不告诉你是怎么做出来的
- 覆盖:替换原来的函数
- 重载:同名函数不同参数
- 例题:答案C

往下笔记略......
下午题多做真题,多练练真题就会了。
编者水平有限,文章如有不足之处,请尽情指出,不吝赐教!
最后,祝各位顺利通过!
诺慕橙

















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









