




 本文介绍了感知机这一二类分类线性模型的基本概念及其学习策略。感知机旨在找到能够正确划分正负类实例的超平面,通过经验损失最小化策略进行训练。文章详细解释了如何使用随机梯度下降法来求解参数,并介绍了感知机的原始形式与对偶形式。
本文介绍了感知机这一二类分类线性模型的基本概念及其学习策略。感知机旨在找到能够正确划分正负类实例的超平面,通过经验损失最小化策略进行训练。文章详细解释了如何使用随机梯度下降法来求解参数,并介绍了感知机的原始形式与对偶形式。
感知机,这个名字真是一言难尽~
感知机是二类分类的线性分类模型,输入实例的特征向量,输出类别,正负1.感知机旨在求出将实例划分为正负两类的分离超平面。
模型:f(x)=sign(wx+b) 这里w和x都是向量
分离超平面就是,wx+b=0
怎么求出这个超平面?需要学习策略:这里用的是经验损失最小化。啥意思?就是,这个超平面分错的误差最小。
最直接想到的是,误分类的点数越少,就代表误差越小咯,但是,这个个数的函数并不是一个连续可导的,对w和b不好做优化。接下来就用到了,误分类点到平面的距离之和。
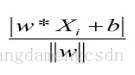 分母上是L2范数
分母上是L2范数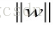 ,就是向量元素平方和再求根号。
,就是向量元素平方和再求根号。
误分类的点,(xi,yi),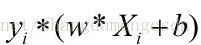 <0 那么距离就是
<0 那么距离就是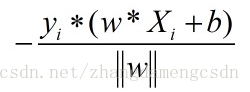
这里的分母可以不考虑,为啥?如果这个L2范数规定为1,就相当于对分离超平面这个方程进行了规范化,就好似3x+y=3,可以规范化为x+y/3-1=0,都是指的同一个平面,所以对要求的最小化没有影响。
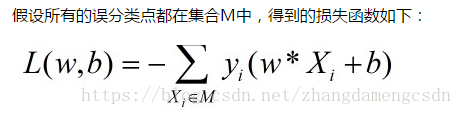
min L(w,b) 就是目标函数
接下来就是如何求解参数的问题啦,就是学习算法
这里用的是随机梯度下降法。
先给初值,然后随机选一个误分类点,进行w和b的更新,直到最后没有误分类点。
为啥用这么一个方法呢?

为啥叫原始形式,因为后面还会讲一个对偶形式。
课本上还证明了,这个算法是收敛的,啥意思?就是能通过有限次迭代,使得没有误分类的点,得到参数的解,当然了,给不同的初值,随机选择的误分类点不同,都会导致解的不同,也就是说,这个算法可以得到不止一个解。
SVM就是在感知机的基础上加了约束条件,使得最后的解只有一个。
接下来是对偶形式。
其实很简单,因为下降的步长一直不变,我用一个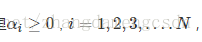 来记录样本点(xi,yi)被误分类的次数(当步长为1时,若不为1,就是次数乘步长)然后,
来记录样本点(xi,yi)被误分类的次数(当步长为1时,若不为1,就是次数乘步长)然后,
w和b,可以表示成
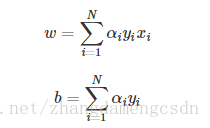 就是把迭代更新的每一步都加起来
就是把迭代更新的每一步都加起来

这个对偶形式,可以发现,只需要计算样本点特征向量的内积。可以预先用矩阵存储,Gram矩阵。
OK很简单。

















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









