







神经网络
感知器

f ( x ) = ∑ j = 0 p w j x j = ∑ j = 1 p w j x j + w 0 = w T x f(x)=\sum_{j=0}^pw_jx_j=\sum_{j=1}^pw_jx_j+w_0=\boldsymbol w^T\boldsymbol x f(x)=j=0∑pwjxj=j=1∑pwjxj+w0=wTx
用感知器分类
f ( x ) = s ( ∑ j = 1 p w j x j + w 0 ) = s ( w T x ) f(x)=s(\sum_{j=1}^pw_jx_j+w_0)=s(\boldsymbol w^T\boldsymbol x) f(x)=s(j=1∑pwjxj+w0)=s(wTx)
s s s 是一个阈值函数。分类: f ( x ) > 0 f(x)>0 f(x)>0 或 f ( x ) < 0 f(x)<0 f(x)<0。
如果不是简单的决定正负(+、-),那么可以构造:
f
(
x
)
=
σ
(
∑
j
=
1
p
w
j
x
j
+
w
0
)
=
σ
(
w
T
x
)
σ
(
u
)
=
1
1
+
exp
(
−
u
)
f(x)=\sigma(\sum_{j=1}^pw_jx_j+w_0)=\sigma(\boldsymbol w^T\boldsymbol x)\\\sigma(u)=\frac{1}{1+\exp(-u)}
f(x)=σ(j=1∑pwjxj+w0)=σ(wTx)σ(u)=1+exp(−u)1

一维的总结
回归:
f
(
x
)
=
∑
j
=
1
p
w
j
x
j
+
w
0
f(x)=\sum_{j=1}^pw_jx_j+w_0
f(x)=j=1∑pwjxj+w0
分类:
f
(
x
)
=
1
/
(
1
+
exp
[
−
(
∑
j
=
1
p
w
j
x
j
+
w
0
)
]
)
f(x)=1/(1+\exp[-(\sum_{j=1}^pw_jx_j+w_0)])
f(x)=1/(1+exp[−(j=1∑pwjxj+w0)])
多类分类

选择 C k : f k ( x ) = max l ∈ { 1 , ⋯ , K } f l ( x ) C_k:f_k(x)=\max_{l\in\{1,\cdots,K\}}f_l(x) Ck:fk(x)=maxl∈{1,⋯,K}fl(x)。
为得到概率,使用 softmax:
σ
(
u
)
=
1
1
+
e
−
u
=
e
u
1
+
e
u
f
k
(
x
)
=
exp
(
o
k
)
∑
l
=
1
K
exp
(
o
l
)
,
o
k
=
w
k
T
x
\sigma(u)=\frac{1}{1+e^{-u}}=\frac{e^u}{1+e^u}\\f_k(x)=\frac{\exp(o_k)}{\sum_{l=1}^K\exp(o_l)},o_k=\boldsymbol w^{kT}\boldsymbol x
σ(u)=1+e−u1=1+eueufk(x)=∑l=1Kexp(ol)exp(ok),ok=wkTx
如果一个类的输出足够大于其他类,则其softmax将接近1(否则为0)。
训练感知器
随机梯度下降:从随机权重开始,在每个点,调整权重以最小化误差。
通用的Update rule:
Δ
w
j
=
−
η
∂
E
r
r
o
r
(
f
(
x
i
)
,
y
i
)
∂
w
j
\Delta w_j=-\eta\frac{\partial Error(f(x^i),y^i)}{\partial w_j}
Δwj=−η∂wj∂Error(f(xi),yi)
在每个训练实例后,对于每个权重:
w
i
(
t
+
1
)
=
w
j
(
t
)
+
Δ
w
i
(
t
)
w
j
←
w
j
+
Δ
w
j
w_i^{(t+1)}=w_j^{(t)}+\Delta w_i^{(t)}\\w_j\leftarrow w_j+\Delta w_j
wi(t+1)=wj(t)+Δwi(t)wj←wj+Δwj
回归
E r r o r ( f ( x i ) , y i ) = 1 2 ( y i − f ( x i ) ) 2 = 1 2 ( y i − w T x i ) 2 Error(f(x^i),y^i)=\frac{1}{2}(y^i-f(x^i))^2=\frac{1}{2}(y^i-\boldsymbol w^T\boldsymbol x^i)^2 Error(f(xi),yi)=21(yi−f(xi))2=21(yi−wTxi)2
对于回归的Update rule为:
Δ
w
j
=
η
(
y
i
−
f
(
x
i
)
)
x
j
i
\Delta w_j=\eta(y^i-f(x^i))x^i_j
Δwj=η(yi−f(xi))xji
Sigmoid output:
f
(
x
i
)
=
σ
(
w
T
x
i
)
,
σ
(
u
)
=
1
1
+
e
−
u
,
σ
′
(
u
)
=
u
′
σ
(
u
)
(
1
−
σ
(
u
)
)
f(x^i)=\sigma(\boldsymbol w^T\boldsymbol x^i),\sigma(u)=\frac{1}{1+e^{-u}},\sigma'(u)=u'\sigma(u)(1-\sigma(u))
f(xi)=σ(wTxi),σ(u)=1+e−u1,σ′(u)=u′σ(u)(1−σ(u))
Cross-entropy error:
E
r
r
o
r
(
f
(
x
i
)
,
y
i
)
=
−
y
i
log
f
(
x
i
)
−
(
1
−
y
i
)
log
(
1
−
f
(
x
i
)
)
Error(f(x^i),y^i)=-y^i\log f(x^i)-(1-y^i)\log(1-f(x^i))
Error(f(xi),yi)=−yilogf(xi)−(1−yi)log(1−f(xi))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xm8tZLAA-1622796911073)(C:\Users\meixuchen\AppData\Roaming\Typora\typora-user-images\image-20210604114520083.png)]](https://img-blog.csdnimg.cn/20210604165941558.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzUyNzM3NTQ0,size_16,color_FFFFFF,t_70)
K类
K>2的 softmax输出:
f
k
(
x
i
)
=
exp
(
w
k
T
x
i
)
∑
l
=
1
K
exp
(
w
l
T
x
i
)
f_k(x^i)=\frac{\exp(\boldsymbol w^{kT}\boldsymbol x^i)}{\sum_{l=1}^K\exp(\boldsymbol w^{lT}\boldsymbol x^i)}
fk(xi)=∑l=1Kexp(wlTxi)exp(wkTxi)
Cross-entropy error:
E
r
r
o
r
(
f
(
x
i
)
,
y
i
)
=
−
∑
k
=
1
K
y
k
i
log
f
k
(
x
i
)
Error(f(x^i),y^i)=-\sum_{k=1}^Ky_k^i\log f_k(x^i)
Error(f(xi),yi)=−k=1∑Kykilogfk(xi)
Update rule
Δ
w
j
=
η
(
y
i
−
f
(
x
i
)
)
x
j
i
\Delta w_j=\eta(y^i-f(x^i))x^i_j
Δwj=η(yi−f(xi))xji

布尔函数
AND

f
(
x
)
=
s
(
w
0
+
w
1
x
1
+
w
2
x
2
)
f(x)=s(w_0+w_1x_1+w_2x_2)
f(x)=s(w0+w1x1+w2x2)
理想的分界线:

XOR
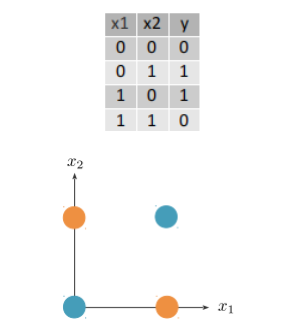
f ( x ) = s ( w 0 + w 1 x 1 + w 2 x 2 ) w 0 ≤ 0 w 0 + w 2 > 0 w 0 + w 1 > 0 w 0 + w 1 + w 2 ≤ 0 f(x)=s(w_0+w_1x_1+w_2x_2)\\w_0\leq0\\w_0+w_2>0\\w_0+w_1>0\\w_0+w_1+w_2\leq0 f(x)=s(w0+w1x1+w2x2)w0≤0w0+w2>0w0+w1>0w0+w1+w2≤0
多层感知器
隐藏层:

隐藏单元的输出:
z
h
=
1
1
+
e
−
w
h
T
x
z_h=\frac{1}{1+e^{-\boldsymbol w_h^T\boldsymbol x}}
zh=1+e−whTx1
神经网络输出:
f
(
x
)
=
v
T
z
=
v
0
+
∑
h
=
1
H
v
h
1
+
e
−
w
h
T
x
∂
E
∂
w
h
j
=
∂
E
∂
f
(
x
)
∂
f
(
x
)
∂
z
h
∂
z
h
∂
w
h
j
∂
f
(
x
)
∂
z
h
→
v
h
,
∂
z
h
∂
w
h
j
→
z
h
i
(
1
−
z
h
i
)
x
j
i
f(x)=\boldsymbol v^T\boldsymbol z=v_0+\sum_{h=1}^H\frac{v_h}{1+e^{-\boldsymbol w_h^T\boldsymbol x}}\\\frac{\partial E}{\partial w_{hj}}=\frac{\partial E}{\partial f(x)}\frac{\partial f(x)}{\partial z_h}\frac{\partial z_h}{\partial w_{hj}}\\\frac{\partial f(x)}{\partial z_h}\to v_h,\frac{\partial z_h}{\partial w_{hj}}\to z_h^i(1-z_h^i)x_j^i
f(x)=vTz=v0+h=1∑H1+e−whTxvh∂whj∂E=∂f(x)∂E∂zh∂f(x)∂whj∂zh∂zh∂f(x)→vh,∂whj∂zh→zhi(1−zhi)xji
回归
E r r o r ( f ( x i ) , y i ) = 1 2 ( y i − f ( x i ) ) 2 f ( x ) = v 0 + ∑ h = 1 H v h z h , z h = σ ( w h T x ) Δ v h = η 1 ( y i − f ( x i ) ) z h i Δ w h j = − η ∂ E i ∂ w h j = − η ∂ E i ∂ f ( x i ) ∂ f ( x i ) ∂ z h i ∂ z h i ∂ w h j = − η − ( y i − f ( x i ) ) v h z h i ( 1 − z h i ) x j i Error(f(x^i),y^i)=\frac{1}{2}(y^i-f(x^i))^2\\f(x)=v_0+\sum_{h=1}^Hv_hz_h,z_h=\sigma(\boldsymbol w_h^T\boldsymbol x)\\\Delta v_h=\eta_1(y^i-f(x^i))z_h^i\\\Delta w_{hj}=-\eta\frac{\partial E^i}{\partial w_{hj}}=-\eta\frac{\partial E^i}{\partial f(x^i)}\frac{\partial f(x^i)}{\partial z_h^i}\frac{\partial z_h^i}{\partial w_{hj}}\\=-\eta-(y^i-f(x^i))v_hz_h^i(1-z_h^i)x_j^i Error(f(xi),yi)=21(yi−f(xi))2f(x)=v0+h=1∑Hvhzh,zh=σ(whTx)Δvh=η1(yi−f(xi))zhiΔwhj=−η∂whj∂Ei=−η∂f(xi)∂Ei∂zhi∂f(xi)∂whj∂zhi=−η−(yi−f(xi))vhzhi(1−zhi)xji
初始化所有的
v
h
,
w
h
j
v_h,w_{hj}
vh,whj 到
(
−
0.01
,
0.01
)
(-0.01,0.01)
(−0.01,0.01)的随机数,重复,直到收敛:
f
o
r
i
=
1
,
⋯
,
n
f
o
r
h
=
1
,
⋯
,
H
z
h
i
=
σ
(
w
h
T
x
i
)
f
(
x
i
)
=
v
T
z
i
f
o
r
h
=
1
,
⋯
,
H
Δ
v
h
=
η
1
(
y
i
−
f
(
x
i
)
)
z
h
i
f
o
r
h
=
1
,
⋯
,
H
f
o
r
j
=
1
,
⋯
,
p
Δ
w
h
j
=
η
(
y
k
i
−
f
k
(
x
i
)
)
v
h
z
h
i
(
1
−
z
h
i
)
x
j
i
f
o
r
h
=
1
,
⋯
,
H
v
h
←
v
h
+
Δ
v
h
f
o
r
j
=
1
,
⋯
,
p
w
h
j
←
w
h
j
+
Δ
w
h
j
for\ i=1,\cdots,n\\for\ h=1,\cdots,H\\z_h^i=\sigma(\boldsymbol w_h^T\boldsymbol x^i)\\f(x^i)=\boldsymbol v^T\boldsymbol z^i\\for\ h=1,\cdots,H\\\Delta v_h=\eta_1(y^i-f(x^i))z_h^i\\for\ h=1,\cdots,H\\for\ j=1,\cdots,p\\\Delta w_{hj}=\eta(y_k^i-f_k(x^i))v_hz_h^i(1-z_h^i)x_j^i\\for\ h=1,\cdots,H\\v_h\leftarrow v_h+\Delta v_h\\for\ j=1,\cdots,p\\w_{hj}\leftarrow w_{hj}+\Delta w_{hj}
for i=1,⋯,nfor h=1,⋯,Hzhi=σ(whTxi)f(xi)=vTzifor h=1,⋯,HΔvh=η1(yi−f(xi))zhifor h=1,⋯,Hfor j=1,⋯,pΔwhj=η(yki−fk(xi))vhzhi(1−zhi)xjifor h=1,⋯,Hvh←vh+Δvhfor j=1,⋯,pwhj←whj+Δwhj
分类
z h = σ ( w h T x ) f ( x ) = σ ( v 0 + ∑ h = 1 H v h z h ) e r r o r = − ∑ i = 1 n y i log ( f ( x i ) ) + ( 1 − y i ) log ( 1 − f ( x i ) ) Δ v h = η 1 ∑ i = 1 n ( y i − f ( x i ) ) z h i Δ w h j = η ∑ i = 1 n ( y i − f ( x i ) ) v h z h i ( 1 − z h i ) x j i z_h=\sigma(\boldsymbol w_h^T\boldsymbol x)\\f(x)=\sigma(v_0+\sum_{h=1}^Hv_hz_h)\\error=-\sum_{i=1}^ny^i\log(f(x^i))+(1-y^i)\log(1-f(x^i))\\\Delta v_h=\eta_1\sum_{i=1}^n(y^i-f(x^i))z_h^i\\\Delta w_{hj}=\eta\sum_{i=1}^n(y^i-f(x^i))v_hz_h^i(1-z_h^i)x_j^i zh=σ(whTx)f(x)=σ(v0+h=1∑Hvhzh)error=−i=1∑nyilog(f(xi))+(1−yi)log(1−f(xi))Δvh=η1i=1∑n(yi−f(xi))zhiΔwhj=ηi=1∑n(yi−f(xi))vhzhi(1−zhi)xji
K类

o k i = v k 0 + ∑ h = 1 H v k h z h i f k ( x ) = exp ( o k i ) ∑ l = 1 K exp ( o l i ) e r r o r = − ∑ i = 1 n ∑ k = 1 K y k i log ( f k ( x i ) ) Δ v k h = η 1 ∑ i = 1 n ( y k i − f k ( x i ) ) z h i Δ w h j = η ∑ i = 1 n ( ∑ k = 1 K ( y k i − f k ( x i ) ) v k h ) z h i ( 1 − z h i ) x j i o_k^i=v_{k0}+\sum_{h=1}^Hv_{kh}z_h^i\\f_k(x)=\frac{\exp(o_k^i)}{\sum_{l=1}^K\exp(o_l^i)}\\error=-\sum_{i=1}^n\sum_{k=1}^Ky_k^i\log(f_k(x^i))\\\Delta v_{kh}=\eta_1\sum_{i=1}^n(y_k^i-f_k(x^i))z_h^i\\\Delta w_{hj}=\eta\sum_{i=1}^n(\sum_{k=1}^K(y_k^i-f_k(x^i))v_{kh})z_h^i(1-z_h^i)x_j^i oki=vk0+h=1∑Hvkhzhifk(x)=∑l=1Kexp(oli)exp(oki)error=−i=1∑nk=1∑Kykilog(fk(xi))Δvkh=η1i=1∑n(yki−fk(xi))zhiΔwhj=ηi=1∑n(k=1∑K(yki−fk(xi))vkh)zhi(1−zhi)xji
多个隐藏层
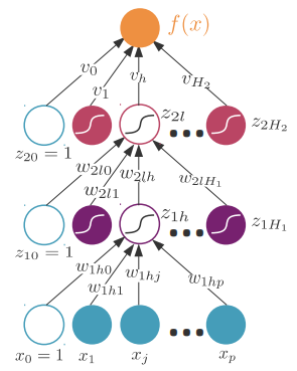
f ( x ) = v 0 + ∑ l = 1 H 2 v l z 2 l z 2 l = σ ( w 2 l T z 1 ) = σ ( w 2 l 0 + ∑ h = 1 H 1 w 2 l h z 1 h ) z 1 h = σ ( w 1 h T x ) = σ ( w 1 h 0 + ∑ j = 1 p w 1 h j x j ) f ( x ) = v 0 + ∑ l = 1 H 2 v l ⋅ σ ( w 2 l 0 + ∑ h = 1 H 1 w 2 l h ⋅ σ ( w 1 h 0 + ∑ j = 1 p w 1 h j x j ) ) f(x)=v_0+\sum_{l=1}^{H_2}v_lz_{2l}\\z_{2l}=\sigma(\boldsymbol w_{2l}^T\boldsymbol z_1)=\sigma(w_{2l0}+\sum_{h=1}^{H_1}w_{2lh}z_{1h})\\z_{1h}=\sigma(\boldsymbol w_{1h}^T\boldsymbol x)=\sigma(w_{1h0}+\sum_{j=1}^pw_{1hj}x_j)\\f(x)=v_0+\sum_{l=1}^{H_2}v_l·\sigma(w_{2l0}+\sum_{h=1}^{H_1}w_{2lh}·\sigma(w_{1h0}+\sum_{j=1}^pw_{1hj}x_j)) f(x)=v0+l=1∑H2vlz2lz2l=σ(w2lTz1)=σ(w2l0+h=1∑H1w2lhz1h)z1h=σ(w1hTx)=σ(w1h0+j=1∑pw1hjxj)f(x)=v0+l=1∑H2vl⋅σ(w2l0+h=1∑H1w2lh⋅σ(w1h0+j=1∑pw1hjxj))















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









