







Pandas 简介
Pandas是对数据进行处理的工具,通过该工具可以对数据进行快速的建模,机器学习中需要大量的对数据进行处理,因此在真正学习TensorFlow之前,我们先来了解一下Pandas。具体使用方法如下:
下载安装
安装方法很容易,只要 cd 到Python的安装目录下的Scripts,我这里安装在E盘下,所以cd E:\Python\Python35\Scripts
然后执行pip install pandas就可以下载安装Pandas了,如下图:
基本使用
引入Pandas并输出版本号
from __future__ import print_function
import pandas as pd
pd.__version__
结构
pandas 中的主要数据结构被实现为以下两类:
- DataFrame,您可以将它想象成一个关系型数据表格,其中包含多个行和已命名的列
- Series,它是单一列。DataFrame 中包含一个或多个 Series,每个 Series 均有一个名称
创建Series
pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
创建DataFrame
city_names = pd.Series(['San Francisco', 'San Jose', 'Sacramento'])
population = pd.Series([852469, 1015785, 485199])
#创建DataFrame
pd.DataFrame({ 'City name': city_names, 'Population': population })
通常情况下数据量会很多,所以我们不会手动创建DataFrame,这时候我们会导入数据文件,下面的代码是导入一个住房数据文件:
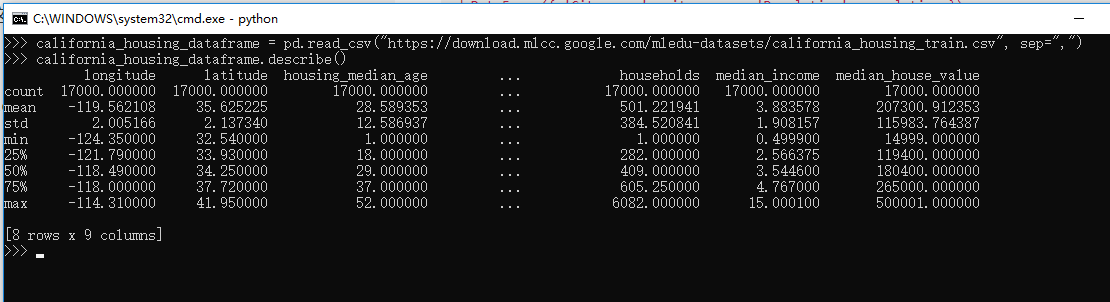
california_housing_dataframe = pd.read_csv("https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv", sep=",")
#显示DataFrame 有趣的统计信息
california_housing_dataframe.describe()
上面的代码执行结果是(需要翻墙):
除此之外您还可以输入一下代码来显示DataFrame的前几条数据:
california_housing_dataframe.head()
绘制图标:
california_housing_dataframe.hist('housing_median_age')
在绘图之前你需要安装matplotlib,步骤如图:
但一般情况下命令行是无法绘制出图标的,你会看到命令行执行的结果如下:

访问数据
输出所有的城市名:
cities = pd.DataFrame({ 'City name': city_names, 'Population': population })
print(type(cities['City name']))
cities['City name']
输出第一个:
print(type(cities['City name'][1]))
cities['City name'][1]
输出第一个到第三个:
print(type(cities[0:2]))
cities[0:2]
操控数据
对整列进行运算,例如可以将所有的population都除以1000:
population / 1000
向现有 DataFrame 添加 Series:
#增加列
cities['Area square miles'] = pd.Series([46.87, 176.53, 97.92])
#修改列的值
cities['Population density'] = cities['Population'] / cities['Area square miles']
本节到此结束/
欢迎大家加入Q群讨论:463255841
本节到此结束/

















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









