







用决策树算法预测森林植被
向量和特征
在根据今天的天气预测明天的气温事件中,“今天的天气”中某些“特征”却是能预测明天的气温,例如
- 今天的最高气温
- 今天的最低气温
- 今天的平均湿度
- 今天是多云、晴天还是下雨
- 今天有几家天气预报估计明天有寒流
这些特征有时被称作纬度、预测指标,以上每个特征都可以被量化。
比如气温高低可以用“摄氏度”度量,湿度可以用 0~1 范围内的小数来度量,天气类型可
以用“多云”“有雨”和“晴朗”来标示。天气预报的个数则是个整数。因此今天的天气
可以简化为一个值列表: 13.1, 19.0, 0.73, 多云 ,1 。将这五个特征值按顺序排序,即所谓的特征向量
Covtype数据集
Covtype数据集地址:Covtype数据集
该数据集记录了美国科罗拉多州不同地块的森林植被类型每个样本包含了描述每块土地的若干特征,包括海拔、坡度、到水源的距离、
遮阳情况和土壤类型,并且随同给出了地块的已知森林植被类型
第一棵决策树
如果是在本地运行,最好给spark分配6g以上内存空间,如果在集群运行,则可忽略该步骤
启动spark-shell并分配6g存储空间
spark-shell --driver-memory 6g
决策树的实现,以及Spark MLlib中其他几个实现,都必须要求使用Labeledpoint对象格式
import org.apache.spark.mllib.linalg._
import org.apache.spark.mllib.regression._
val rawData=sc.textFile("file:///media/hadoop/Ubuntu/data/covtype.data")
val data=rawData.map{ line=>
val values=line.split(',').map(_.toDouble)
val featureVector=Vectors.dense(values.init)
val label=values.last-1
LabeledPoint(label,featureVector)
}
设评价指标为精确度指标,数据分成完整的三部分:训练集,交叉检验集,测试及,其中训练集占80%,交叉检验集和测试集各占10%
val Array(trainData,cvData,testData)=data.randomSplit(Array(0.8,0.1,0.1))
trainData.cache()
cvData.cache()
testData.cache()
DecisionTree实现也有几个超参数,需要为他们选择值,训练集和CV集用于给这些超参数选择合适的值,测试集用于对基于选定超参数的模型期望准确度进行无偏估计
现在在训练集上构造一个DecisionTreeModel模型,采用默认参数,并用CV集来计算结果模型的指标
import org.apache.spark.mllib.evaluation._
import org.apache.spark.mllib.tree._
import org.apache.spark.mllib.tree.model._
import org.apache.spark.rdd._
def getMetrics(model: DecisionTreeModel,data: RDD[LabeledPoint]):MulticlassMetrics={
val predictionsAndLabels=data.map(example=>
(model.predict(example.features),example.label)
)
new MulticlassMetrics(predictionsAndLabels)
}
val model=DecisionTree.trainClassifier(trainData,7,Map[Int,Int](),"gini",4,100)
val metrics=getMetrics(model,cvData)
其中trainClassfier指示每个LabeledPoint的目标当作不同类别的标号,7为数据集中目标的取值个数,Map保存类别型特征的信息,最大深度4,最大桶数100
查看混淆矩阵
metrics.confusionMatrix
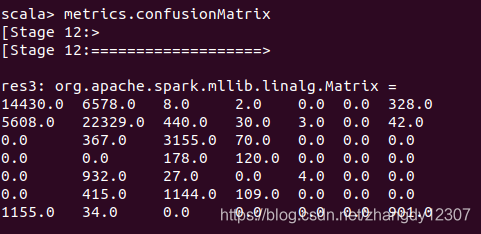
因为目标类别的取值有 7 个,所以混淆矩阵是一个 7×7 的矩阵,矩阵每一行对应一个实
际的正确类别值,矩阵每一列按序对应预测值。第 i 行第 j 列的元素代表一个正确类别为 i
的样本被预测为类别为 j 的次数
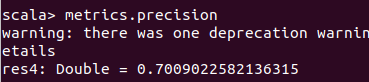
预测正确的样本数占整个样
本数的比例
metrics.precision
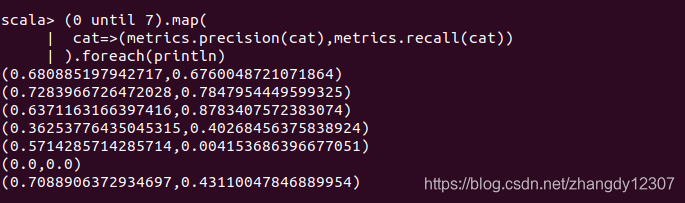
如果要计算每个类别相对其他类别的精确度
(0 until 7).map(
cat=>(metrics.precision(cat),metrics.recall(cat))
).foreach(println)
虽然 70% 的准确度听起来还不错,但我们还不能立马看出这个准确度是优秀还是糟糕。作为基准,一个朴素方法的准确度是多少呢?即使是一个坏了的时钟,每天也会有两次显示的时间是正确的。类似地,为每个样本随便猜一个类别,偶尔也能得到正确答案
构建一个“分类器”。每次分类的正确度将和一个类型在 CV 集中出现的次数成正比。比如,一个类别在训练集中占 20%,在CV 集中占 10%,那么该类别将贡献 10% 的 20%,即 2% 的总体准确度。通过按 20% 的时候将样本猜测为该类,CV 集样本中有 10% 的样本会被猜对。将所有类别在训练集和 CV集出现的概率相乘,然后把结果相加,就得到了一个对准确度的评估
def classProbabilities(data: RDD[LabeledPoint]): Array[Double] = {
val countsByCategory = data.map(_.label).countByValue()
val counts = countsByCategory.toArray.sortBy(_._1).map(_._2)
counts.map(_.toDouble / counts.sum)
}
val trainPriorProbabilities=classProbabilities(trainData)
val cvPriorProbabilities=classProbabilities(cvData)
trainPriorProbabilities.zip(cvPriorProbabilities).map{
case (trainProb,cvProb)=>trainProb*cvProb
}.sum
结果显示随即猜测准确率为37%,所以70%准确率不错
决策树调优
可以让 Spark 来尝试最大深度,桶的个数的许多组合并报告结果,判断那个结果更好
val evaluations =
for (impurity <- Array("gini", "entropy");
depth <- Array(1, 20);
bins <- Array(10, 300))
yield {
val model = DecisionTree.trainClassifier(
trainData, 7, Map[Int,Int](), impurity, depth, bins)
val predictionsAndLabels = cvData.map(example =>
(model.predict(example.features), example.label)
)
val accuracy = new MulticlassMetrics(predictionsAndLabels).precision
((impurity, depth, bins), accuracy)
}
evaluations.sortBy(_._2).reverse.foreach(println)

随机决策森林
如果在构建代码的过程中运行结果有不同,则是由于决策树构建过程中随机因素造成的,在决定采用什么数据和尝试哪些决策规则时都有这些随机因素的影响
基于上述考虑,最好树不只有一棵,而是应该有很多棵,每一棵都能对正确目标值给出合
理、独立且互不相同的估计。这些树的集体平均预测应该比任一个体预测更接近正确答
案。正是由于决策树构建过程中的随机性,才有了这种独立性,这就是随机决策森林的关
键所在。
通过 RandomForest ,Spark MLlib 可以构建随机决策森林。顾名思义,随机决策森林是由多个决策树独立构造而成。
val forest=RandomForest.trainClassifier(
trainData,7,Map(10->4,11->40),20,"auto","entropy",30,300)
与 DecisionTree.trainClassifier() 相比,这里出现了两个新参数。第一个代表要构建多
少棵树,这里是 20。由于要构造 20 棵决策树,而之前我们只构造了一棵决策树,因此这里模型构建过程耗时可能比之前长得多。
第二个新参数是特征决策树每层的评估特征选择策略,这里设为 “auto” (自动)。随机决策森林在实现过程中决策规则不会考虑全部特征,而只考虑全部特征的一个子集
进行预测
模拟一个输入值,使用训练好的模型进行预测
val input = "2709,125,28,67,23,3224,253,207,61,6094,0,29"
val vector = Vectors.dense(input.split(',').map(_.toDouble))
forest.predict(vector)














 1388
1388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









