







 本文介绍了如何在PaddleOCR中更换默认的轻量级模型为识别效果更好的重量级模型,包括理解模型类型、修改paddleocr源文件中的下载链接,并详细说明了查找pip安装库目录的方法。
本文介绍了如何在PaddleOCR中更换默认的轻量级模型为识别效果更好的重量级模型,包括理解模型类型、修改paddleocr源文件中的下载链接,并详细说明了查找pip安装库目录的方法。
一、前言
有关PaddleOCR环境的安装可以参考文章:《PaddleOCR mac 安装指南》
PaddleOCR的环境配置好之后,可以通过简单几行代码,便可识出来图片中的文字:
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
如上代码参见自官方文档: 《快速开始》

“通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。 ”
通过运行代码,验证结果。确实如此,我们在第一次运行时,它的确自动下载了三个模型:

二、已知 PP-OCR系列模型列表
官方文档中,已提供了PP-OCR的一系列模型供我们来使用。 模型列表如下:
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
paddleocr 总共需要三个模型: 检测模型、方向分类器、识别模型。每个模型又分为:推理模型、训练模型
这里有必要解释一下:
推理模型相当于训练完成的模型,直接拿来就可以进行predict;预训练模型属于半成品,用于进一步的训练,之后用自己的数据训练模型时需要用到预训练模型。
那么问题来了,paddleocr默认下载使用的是ppocr轻量级模型,我们怎么使用识别效果最好的那个重量级模型(中英文通用PP-OCR server模型(143.4M))呢?
三、修改 paddleocr 的默认模型
经过一番探索,终于找到一个非常方便的修改 paddleocr 默认模型的方法,就是找到 paddleocr库的 paddleocr.py 这个源文件,直接修改下载链接就行了:
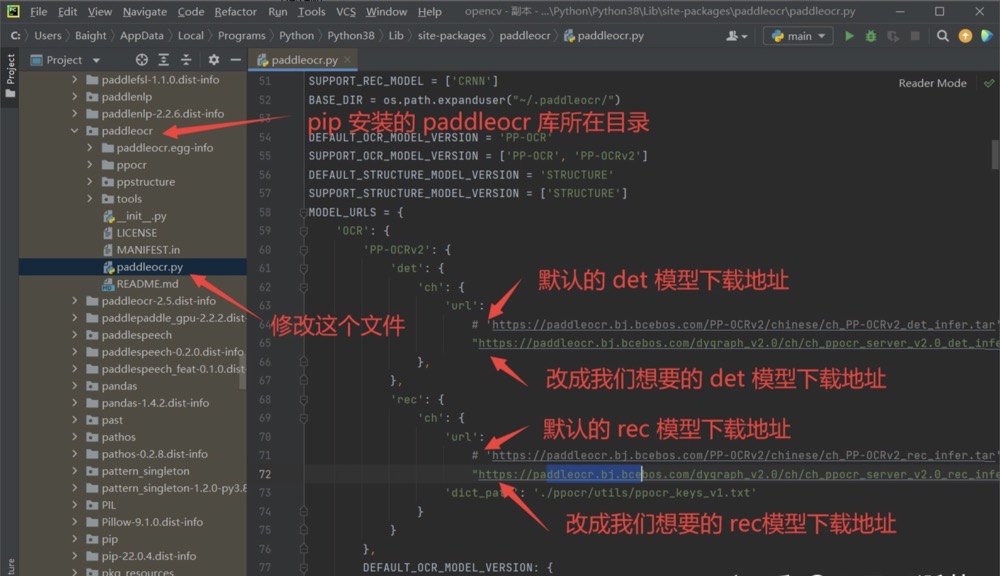
我们只需要修改 检测模型(det模型) 和 识别模型(rec模型)的下载地址就行了,所有方向分类器(cls模型)都是一样的。
然后我们什么都不需要做,再次运行我们的程序,我们就可以看到它重新下载我们指定的新模型了:
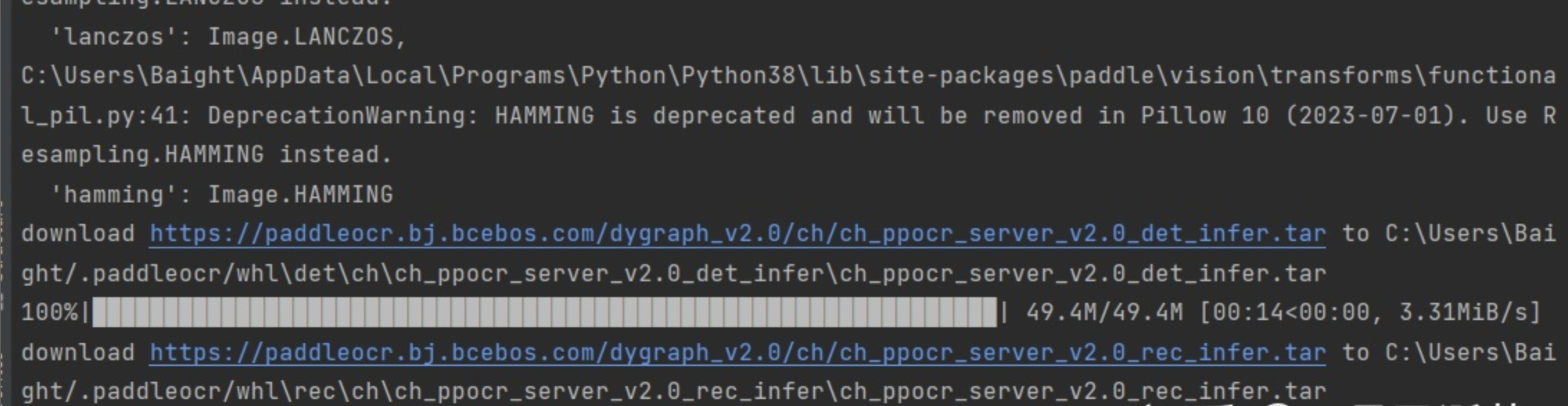
至此,更换模型完成。
四、相关问题
4.1 如何找到 pip 安装的 paddleocr库 所在目录(即寻找paddleocr.py源文件)
执行pip show paddleocr命令即可:



















 3046
3046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











