







一 Spark中Checkpoint是什么
假设一个应用程序特别复杂场景,从初始RDD开始到最后整个应用程序完成,有非常多的步骤,比如超过20个transformation操作,而且整个运行时间也比较长,比如1-5个小时。此时某一个步骤数据丢失了,尽管之前在之前可能已经持久化到了内存或者磁盘,但是依然丢失了,这是很有可能的。也就是说没有容错机制,那么有可能需要重新计算一次。而如果这个步骤很耗时和资源,那么有点悲剧。
对于一个复杂的RDD,我们如果担心某些关键的,会在后面反复使用的RDD,可能会因为节点的故障,导致持久化数据的丢失,就可以针对该RDD启动checkpoint机制,实现容错和高可用。
它的流程大致如下图所示:
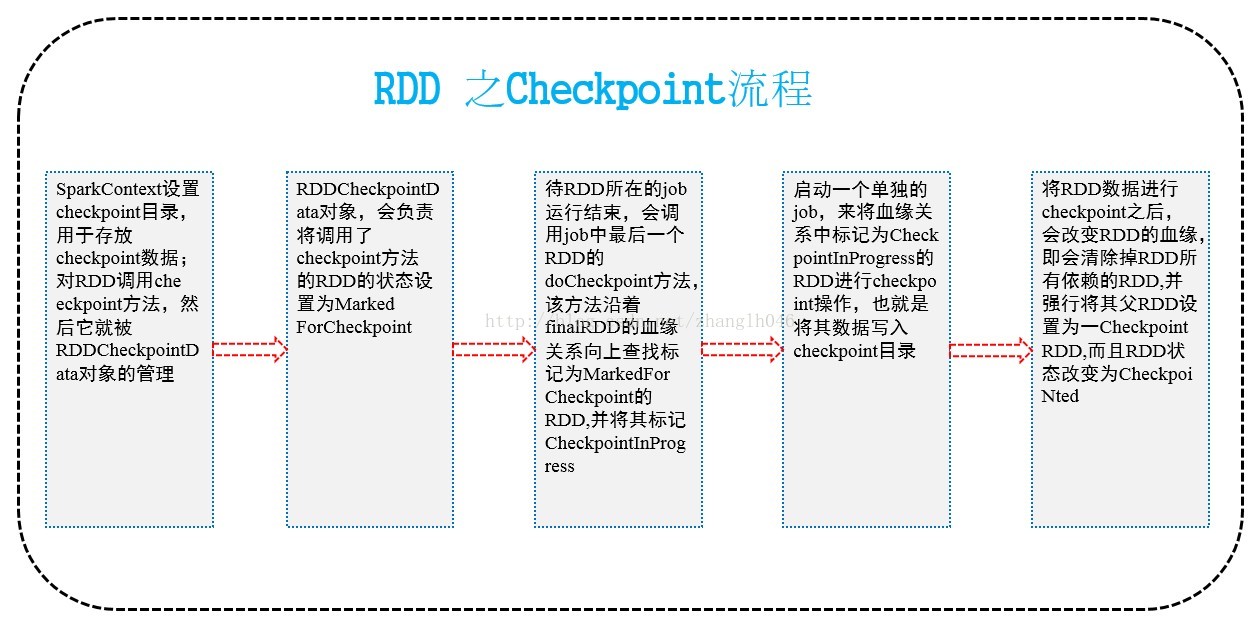
二 如何进行Checkpoint呢?
在SparkContext中需要调用setCheckpointDir方法,设置一个容错的文件系统的目录,比如HDFS。然后对RDD调用checkpoint方法,之后在RDD所处的job运行结束之后,会启动一个单独的job来将checkpoint过的RDD的数据写入之前设置的文件系统中。进行持久化操作。
那么此时,即使在后面使用RDD的时候,他的持久化数据不小心丢失了,但是还是可以从它的checkpoint文件中读取出该数据,而无需重新计算。
注意:
在进行checkpoint之前,最好先对RDD执行持久化操作,比如persist(StorageLevel.DISK_ONLY)如果持久化了,就不用再重新计算;否则如果没有持久化RDD,还设置了checkpoint,那么本来job都结束了,但是由于中间的RDD没有持久化,那么checkpointjob想要将RDD数据写入外部文件系统,还得从RDD之前的所有的RDD全部重新计算一次,再进行checkpoint。然后从持久化的RDD磁盘文件读取数据
三 Checkpoint与持久化的区别
3.1 lineage是否发生改变
持久化只是将数据保存在BlockManager中;但是RDD的lineage(血缘关系)是不会变化的
Checkpoint完毕之后,RDD已经没有之前的lineage(血缘关系),而只有一个强行为其设置的CheckpointRDD, 也就是说checkpoint之后,lineage发生了改变
3.2 丢失数据的可能性
持久化的数据丢失的可能性更大
Checkpoint的数据通常是保存在容错高可用的文件系统中,比如HDFS,所以checkpoint丢失数据的更能性更小
















 6081
6081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











