







本篇文章以STM32为硬件平台,使用GNU GCC作为开发工具,详细分析Compile 、Link 、Loader的过程以及Image(二进制程序)启动的详细分析。整个过程分析涉及到RW可读写段从Flash到Mem的Copy,BSS段的初始化,Stack和Heap的初始化,C库函数移植、利用Semihosting 实现基本的IO等内容。基本可以让你从更深刻的层面理解Source -> Compile -> link -> run的整个过程。理解了这些个之后,你就对那些从语言编程层面来说难于理解的问题自然领会了,比如:为什么C语言规范里会提到变量的作用域和生命周期?全局变量和局部变量的区别到底在哪?等等一些看起来是规定的东西,工科科学里一切不自然的概念都需要你用心去理解,去实践,达到自然的状态才有可能去解决实际遇到的问题,规则只是思想包袱,不会产生任何价值,大部分情况下会阻碍你解决问题。
裸机程序的整体说明
我们都熟悉有操作系统支持的应用程序开发,比如 Linux下C语言的开发。我们可以不用关心程序启动的细节,同时我们一般还可以使用各种方便的lib 库,比如基本的IO操作(printf scan),动态分配内存操作(malloc),文件操作(fopen fwrite fread)等。有操作系统支持的情况下,程序的编译、链接、启动都是有操作系统支持的,常用的编程库函数使用的是标准的C库。
那如果没有OS支持的情况下,想实现上面这些功能的话,该怎么做呐?这种情况就叫 Bare Metal (裸)程序开发。在嵌入式开发中是比较常见的情况,本blog 主要讲解基于Cortex-M3 的裸程序开发。本裸机程序实现了 基本IO,动态内存分配,基本函数库等功能。
主程序(main)验证了那些功能
主程序验证了基本的Startup,基本的IO功能,malloc功能,打印了全局变量和局部变量的地址(用于理解全局变量和局部变量的区别)。
其主程序代码如下:
#include <stdio.h>
#include <stdlib.h>
#include "diag/Trace.h"
int test = 10;
int main(int argc, char* argv[])
{
int local_test = 8;
int i;
float temp = 0.01;
int *arr_malloc = NULL;
arr_malloc = malloc(10*sizeof(int));
if(!arr_malloc)
{
trace_puts("malloc error!");
exit(1);
}
memcpy(arr_malloc,"123456789",9);
arr_malloc[9]=NULL;
trace_printf("Testing malloc \n");
trace_printf("the string =%s\n", arr_malloc);
// Send a greeting to the trace device (skipped on Release).
trace_puts("Hello ARM World by Linc Zhang!");
// At this stage the system clock should have already been configured
// at high speed.
trace_printf("System clock: %u Hz\n", SystemCoreClock);
trace_printf("the [test]=0x%x\n",test);
trace_printf("the [local_test]=0x%x\n",local_test);
trace_printf("the address[test]=0x%x\n",&test);
trace_printf("the address[local_test]=0x%x\n",&local_test);
trace_printf("the float type value temp =0x%f\n",temp);
timer_start();
blink_led_init();
uint32_t seconds = 0;
// Infinite loop
while (1)
{
}
// Infinite loop, never return.
}
如何实现的startup
还是和有OS支持的情况下来对比,有OS的情况下分析一个Project,一般会从3个方面来进行分析:一是看源代码的组织形式;一是看Compile && Link过程(即Makefile);三是看Run时的情况(一般看运行起来后几个Process,几个Thread,以及他们之间的关系)。分析完这3个方面后,整个project从静到动,以及动静之间的转换都包括了,也就掌握了整个的Project。
在没有OS的情况下,1 2 两个方面是一样的,只不过程序运行的基础环境不一样,裸机程序运行需要考虑的细节多一些。裸机程序需要考虑的基本问题有:
- 编译生成的可执行程序结构是什么样的?整个可执行程序的入口在哪?
- 需要将可执行程序下载到什么地方?程序运行前需要做哪些准备工作?
- C语言运行需要什么样的环境?
我们按照上面说的方法,从3各方面出发,分析我们的Project。
源代码:
顶层目录:
.
├── Debug
├── include
├── ldscripts
├── src
└── system其中src目录是Application层的主逻辑代码,其中main.c就在src目录中,是业务逻辑层的主代码。
include目录是Application层的interface 说明文件。
system 目录是和启动有关系的代码。
ldscripts目录是link 脚本,主要告诉ld(链接器)如何链接各个Objects文件为可执行程序.
Debug目录是个编译目录,里面包含各种Makefile。
更详细的项目目录结构:
.
├── Debug
│ ├── hello.elf
│ ├── hello.hex
│ ├── hello.map
│ ├── makefile
│ ├── objects.mk
│ ├── sources.mk
│ ├── src
│ │ ├── BlinkLed.d
│ │ ├── BlinkLed.o
│ │ ├── main.d
│ │ ├── main.o
│ │ ├── subdir.mk
│ │ ├── Timer.d
│ │ ├── Timer.o
│ │ ├── _write.d
│ │ └── _write.o
│ └── system
│ └── src
├── include
│ ├── BlinkLed.h
│ ├── stm32f10x_conf.h
│ └── Timer.h
├── ldscripts
│ ├── libs.ld
│ ├── mem.ld
│ └── sections.ld
├── src
│ ├── BlinkLed.c
│ ├── main.c
│ ├── Timer.c
│ └── _write.c
└── system
├── include
│ ├── arm
│ ├── cmsis
│ ├── cortexm
│ ├── diag
│ └── stm32f1-stdperiph
└── src
├── cmsis
├── cortexm
├── diag
├── newlib
└── stm32f1-stdperiph这里简单说明下system 目录,cmsis主要是soc相关的初始化代码,cortexm是Cortex-M3的启动相关代码,diag是使用Semihosting实现了基本的IO,newlib是newlib移植需要实现的函数,stm32f1-stdperiph 是soc片上的外设资源的Driver。
编译&&链接:
当然是直接 make 喽。
编译的模板,自己根据实际文件名进行修改
arm-none-eabi-gcc -mcpu=cortex-m3 -mthumb -Og -fmessage-length=0 -fsigned-char -ffunction-sections -fdata-sections -ffreestanding -fno-move-loop-invariants -Wall -Wextra -g3 -DDEBUG -DUSE_FULL_ASSERT -DTRACE -DOS_USE_TRACE_SEMIHOSTING_DEBUG -DSTM32F10X_MD -DUSE_STDPERIPH_DRIVER -DHSE_VALUE=8000000 -I"../include" -I"../system/include" -I"../system/include/cmsis" -I"../system/include/stm32f1-stdperiph" -std=gnu11编译说明:编译单个文件其实还是挺简单,只是添加了一些功能性的宏定义。
链接的模板,自己需要添加Objects文件
arm-none-eabi-g++ -mcpu=cortex-m3 -mthumb -Og -fmessage-length=0 -fsigned-char -ffunction-sections -fdata-sections -ffreestanding -fno-move-loop-invariants -Wall -Wextra -v --verbose -g3 -T mem.ld -T libs.ld -T sections.ld -nostartfiles -Xlinker --gc-sections -L"../ldscripts" -u _printf_float -Wl,-Map,"hello.map" --specs=nano.specs -o "hello.elf"链接说明:链接时使用了-nostartfiles,含义是不使用Crt0.o 提供的启动代码,库函数还是使用arm-linux-gcc提供的new-lib。
映像结构&&运行:
有操作系统的情况下,我们不需要关心可执行映像的具体结构,一个可执行程序文件从静态文件到动态运行这个过程叫Loader&&Run。这个过程是由OS来完成的,应用程序级别的开发是不需要关心这些细节的。对OS如何处理Link&&Loader这些细节感兴趣的,可以参考书籍:
1. 程序员的自我修养
2. Linkers and Loaders
我们这里处理的是裸程序的启动细节问题,首先我们要知道的是通过编译器和链接器之后得到的二进制可执行映像的结构。也就是说得出的那个 *.bin 文件里面长啥样?一图胜万言,上张图先。
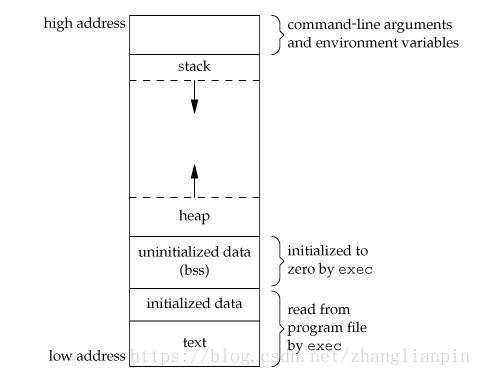
我们大家都知道冯.诺依曼架构的计算机,它的基本思想是把“做事情的步骤和所需要的资源都提前编写好,然后让计算机自己根据需要读取操作步骤和资源,实现部分的计算自动化”。计算机的设计思想可谓是精妙的,实现真正的计算自动化也是很多科学家和工程师的夙愿。上面所说的做事情的步骤在计算机领域叫指令,所需要的资源在计算机领域叫数据。从计算机体系结构角度去看可执行映像的话,其实也就分为指令和数据两个大的部分。指令部分还是比较单一的,把各个源文件中的指令部分最后都汇聚到一起,形成所谓的text段。从功能上分,代码段只是需要CPU去读取,不需要修改,因为可以将其放在RO存储器里。数据这个部分从功能上来看,它必须支持读写,也即数据段执行时必须位于RW存储器里。从功能细节上分数据段又分为BSS段,Data段,Stack段,Heap段。从计算机体系结构角度来一一分析,从数据的生存周期角度来看,有的数据的生存周期和程序的生存周期是一致的(全局变量),有的数据的生存周期是根据使用情况即时分配和释放的(局部变量、malloc动态分配的变量)。BSS段和Data段属于全生命周期的数据,在源程序里主要是那些在文件域定义的全局变量和使用static关键字定义的全生命周期变量,Data是那些在程序里定义变量时初始化为固定值的量,BSS段是那些在程序里定义变量时未初始化的变量,这些变量在映像真正执行前会自动初始化为0。对BSS段再多说一句,BSS段在映像文件里并不占用具体的空间,因为没有任何具体的信息,只需要在映像文件中提供BSS段的起始地址和大小信息即可。在映像文件实际执行前,把BSS段要求的Data区域在实际RAM中预留出来并把这些区域初始化为0。短生命周期的数据包括Heap和Stack,它们的特点是随用随申请,用完就释放,比较灵活。Heap是一段预留出来的大空间,可以根据需求随时申请和释放,就是我们常见的malloc free函数操作的空间就是Heap 空间,这部分空间在映像里是独立出来的一段空间,见上面的程序映像图。Stack也是独立预留出来的一段连续数据空间,它的作用还挺多,想更进一步了解的请看
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2268
2268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









