






一、有监督学习和无监督学习
1、有监督学习:
通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。就如有标准答案的练习题,然后再去考试,相比没有答案的练习题然后去考试准确率更高。又如我们小的时候不知道牛和鸟是否属于一类,但当我们随着长大各种知识不断输入,我们脑中的模型越来越准确,判断动物也越来越准确。
有监督学习可分为回归和分类。
回归:即给出一堆自变量X和因变量Y,拟合出一个函数,这些自变量X就是特征向量,因变量Y就是标签。 而且标签的值连续的,例LR。
分类:其数据集,由特征向量X和它们的标签Y组成,当你利用数据训练出模型后,给你一个只知道特征向量不知道标签的数据,让你求它的标签是哪一个?其输出结果是离散的。例如logistics、SVM、KNN等。
2、无监督学习:
我们事先没有任何训练样本,而需要直接对数据进行建模。比如我们去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别。无监督学习主要算法是聚类,聚类目的在于把相似的东西聚在一起,主要通过计算样本间和群体间距离得到,主要算法包括Kmeans、层次聚类、EM算法。
二、K-Means的工作原理
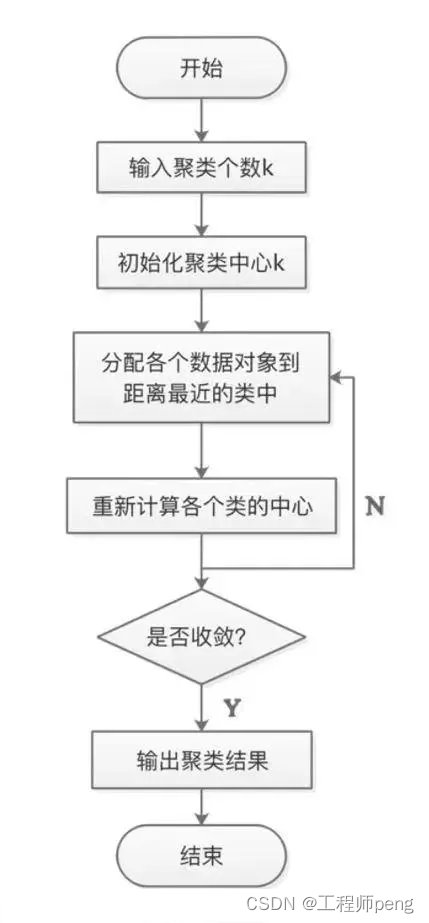
在K-Means算法中,簇的个数K是一个超参数,需要人为输入来确定。K-Means的核心任务就是根据设定好的K,找出K个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。具体过程可以总结如下:
a.首先随机选取样本中的K个点作为聚类中心;
b.分别算出样本中其他样本距离这K个聚类中心的距离,并把这些样本分别作为自己最近的那个聚类中心的类别;
c.对上述分类完的样本再进行每个类别求平均值,求解出新的聚类质心;
d.与前一次计算得到的K个聚类质心比较,如果聚类质心发生变化,转过程b,否则转过程e;
e.当质心不发生变化时(当我们找到一个质心,在每次迭代中被分配到这个质心上的样本都是一致的,即每次新生成的簇都是一致的,所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了),停止并输出聚类结果。
三、K-Means算法的时间复杂度
众所周知,算法的复杂度分为时间复杂度和空间复杂度,时间复杂度是指执行算法所需要的计算工作量,常用大O符号表述;而空间复杂度是指执行这个算法所需要的内存空间。如果一个算法的效果很好,但需要的时间复杂度和空间复杂度都很大,那将会在算法的效果和所需的计算成本之间进行权衡。
K-Means算法是一个计算成本很大的算法。K-Means算法的平均复杂度是O(k*n*T),其中k是超参数,即所需要输入的簇数,n是整个数据集中的样本量,T是所需要的迭代次数。在最坏的情况下,KMeans的复杂度可以写作O(n(k+2)/p),其中n是整个数据集中的样本量,p是特征总数。
四. K-Means算法的优缺点
1、K-Means算法的优点
原理比较简单,实现也是很容易,收敛速度快;
聚类效果较优,算法的可解释度比较强。
2、K-Means算法的缺点
K值的选取不好把握;
对于不是凸的数据集比较难收敛;
如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳;
采用迭代方法,得到的结果只是局部最优;
对噪音和异常点比较的敏感。
五、个人实现的算法demo介绍
1.通过命令行确定以下参数:
a.原始样本集文件;
b.K值,也就是期望的目标簇(cluster)
c.最多迭代次数;
d.保存聚类结果的文件;
2.程序运行的参数说明:
a.原始样本集一共有197个元素,序号从0到196。每个元素是10个维度,每个维度值都是整数(包含0和负数);
b.由于Kmeans算法十分简单易懂而且非常有效,但是合理的确定K值和K个初始类簇中心点对于聚类效果的好坏有很大的影响。
为了学习算法,可以暂定K=5。
c.有时候,当n_clusters选择不符合数据的自然分布,或者为了业务需求,必须要填入n_clusters数据提前让迭代停下来时,反而能够提升模型的表现。
本程序设置最大迭代次数为 3000。
d.以文本文件保存聚类结果即可
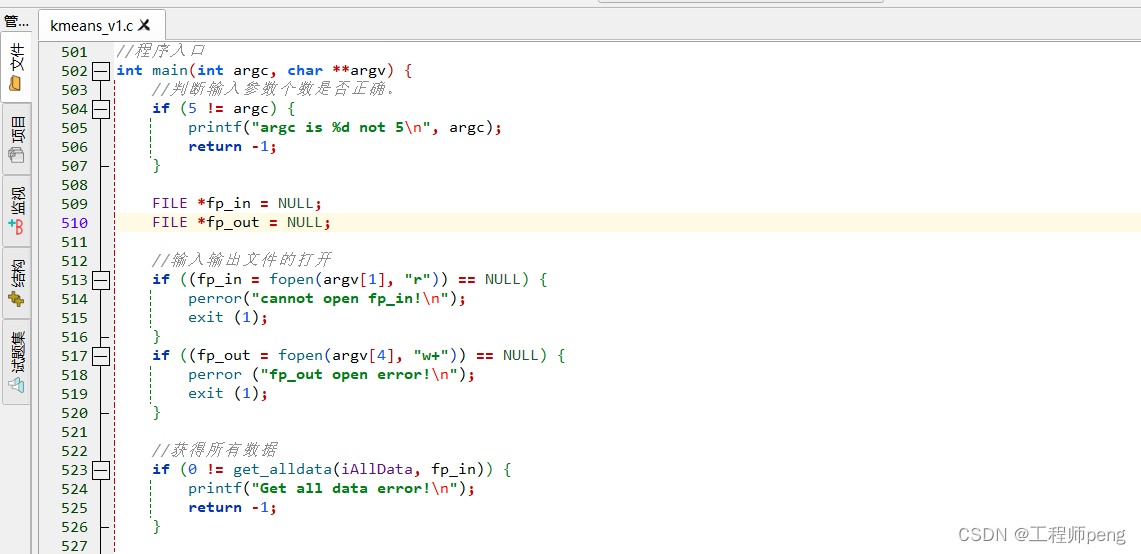
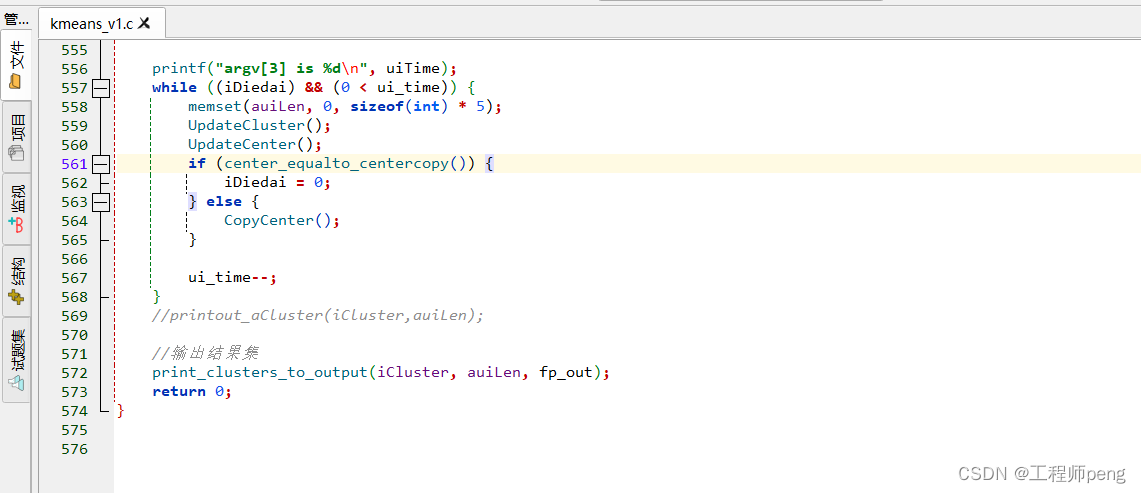
3.main函数:

4.运行过程(Windows环境)
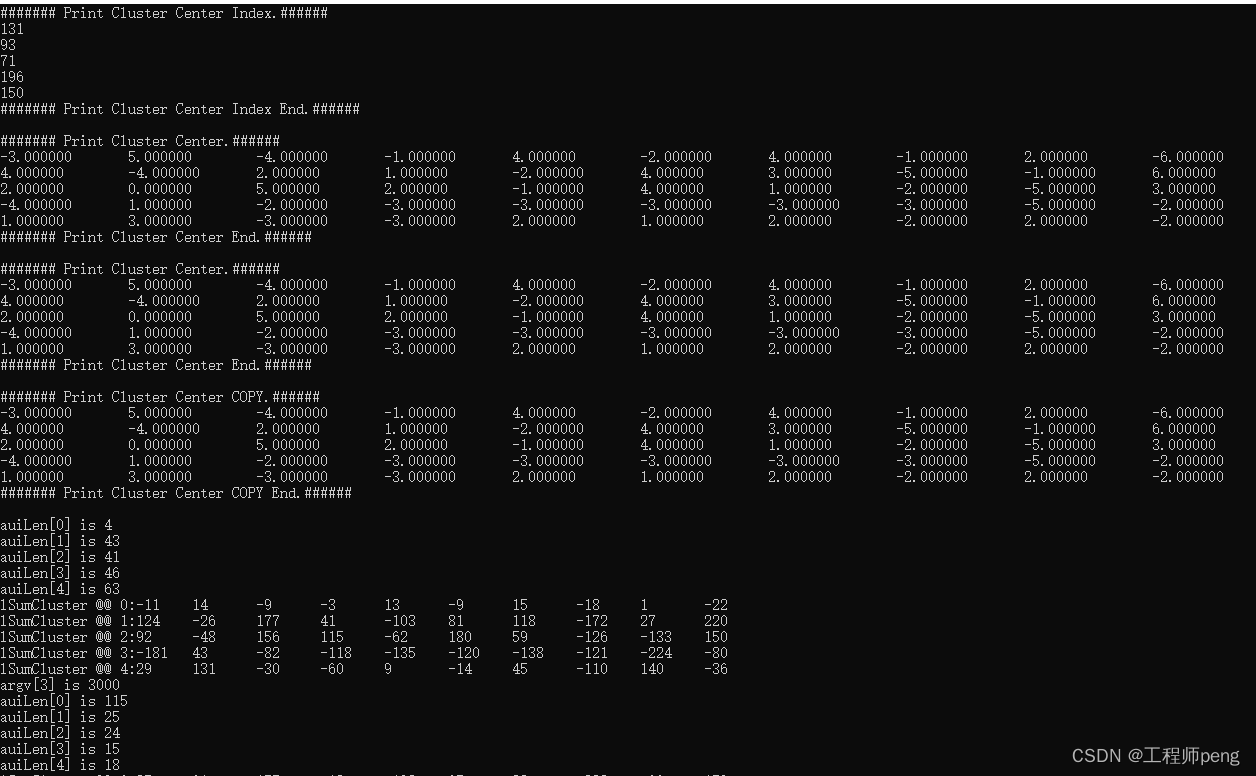
5.聚类结果文件:

鸣谢:特别感谢所有在CSDN等网站热爱技术、乐于分享的工程师们。
说明:本文只是个人学习之用。















 1151
1151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









