







 该博客介绍了如何使用Python对Strava运动路径数据进行清洗和处理。首先,通过pandas读取Excel文件,然后删除含有缺失值的行。接着,对'路线'列中的JSON数据进行解析,提取经纬度信息,并将它们转换为列表。最后,将清洗后的数据存储为字典列表,便于后续分析。
该博客介绍了如何使用Python对Strava运动路径数据进行清洗和处理。首先,通过pandas读取Excel文件,然后删除含有缺失值的行。接着,对'路线'列中的JSON数据进行解析,提取经纬度信息,并将它们转换为列表。最后,将清洗后的数据存储为字典列表,便于后续分析。
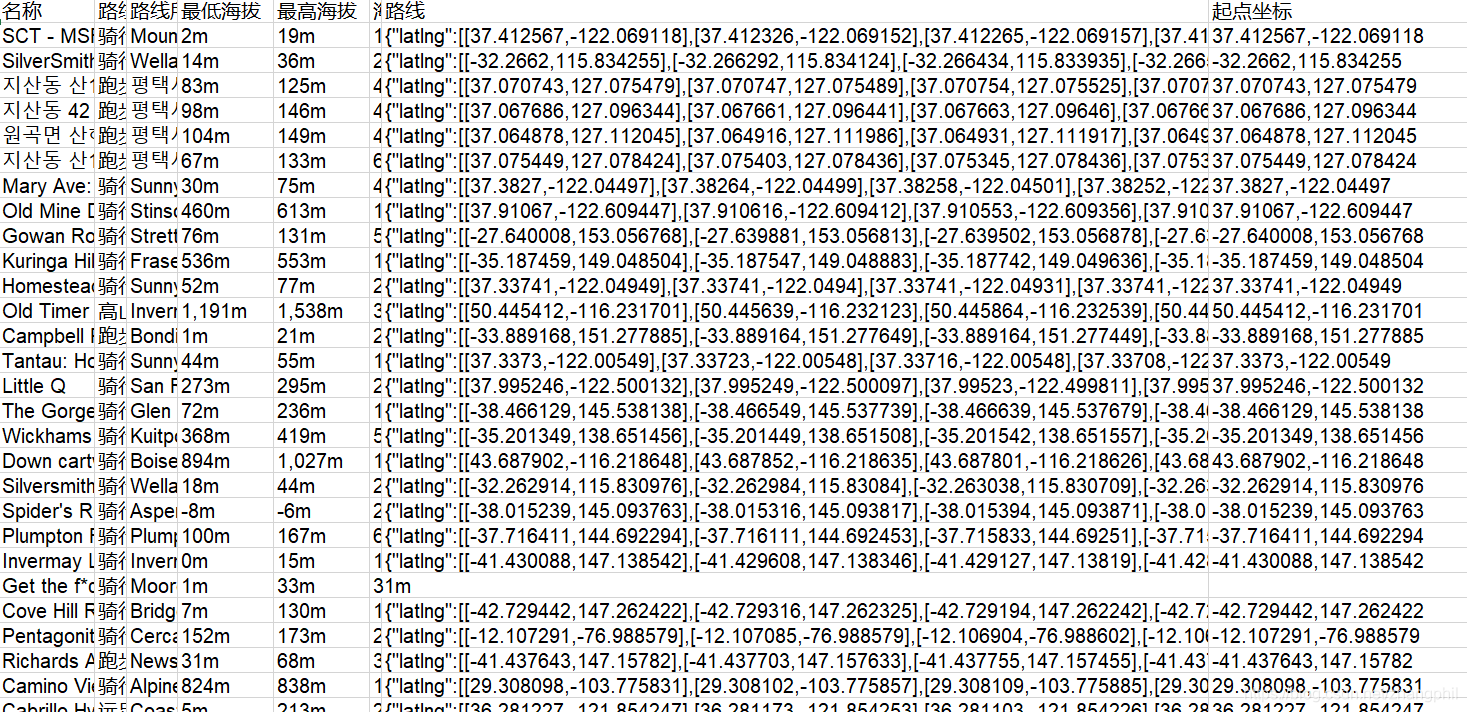
在这这个链接中(https://download.csdn.net/download/zhangphil/13614362),离线下载数据文件,这是strava一个在线的运动跑步和骑行路径路线经纬度散点序列数据,数据集中包含了路线中经过的经纬度点数据,如图:
对上面的数据文件strava_com_sample_utf8.xls进行清洗,python代码如下:
import pandas as pd
import json
from json import JSONDecodeError
KEYS = ['名称', '起点坐标', '终点坐标', '路线']
def opt_latlng(latlng):
newll = []
newll.append(abs(latlng[0]))
newll.append(abs(latlng[1]))
return newll
def get_raw_data():
df = pd.read_excel(io='strava_com_sample_utf8.xls', sheet_name='sheet1')
# print(df.columns.values)
data = df.loc[:, KEYS]
data = data.dropna(axis=0, subset=['起点坐标', '终点坐标', '路线']) # 丢弃'起点坐标', '终点坐标', '路线'这三列中有缺失值的行。
res = []
# 注意路线列中包含三项子内容:latlng,distance,altitude
for v in data.values:
try:
json.loads(v[3])
bundle = {}
for i in range(len(KEYS)):
bundle.setdefault(KEYS[i], v[i])
res.append(bundle)
except JSONDecodeError:
print('JSONDecodeError错误')
return res
def strToList(str_latlng):
lat, lng = str_latlng.split(',')
ll = list([abs(float(lat)), abs(float(lng))])
return ll
def get_data(raw_data):
data = []
for d in raw_data:
jd = json.loads(d['路线'])
latlng = jd['latlng']
latlngs = []
for ll in latlng:
latlngs.append(opt_latlng(ll))
bundle = {}
bundle.setdefault(KEYS[0], d[KEYS[0]])
bundle.setdefault(KEYS[1], strToList(d[KEYS[1]]))
bundle.setdefault(KEYS[2], strToList(d[KEYS[2]]))
bundle.setdefault(KEYS[3], latlngs)
data.append(bundle)
return data
if __name__ == '__main__':
data = get_data(get_raw_data())
print(data)


















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











