







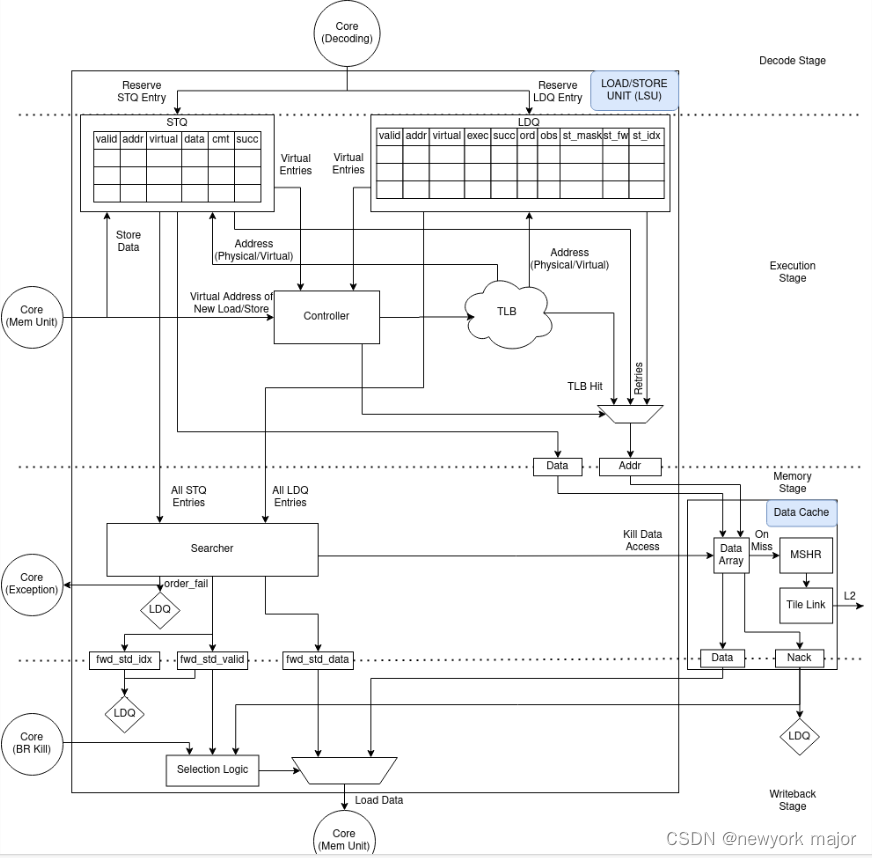
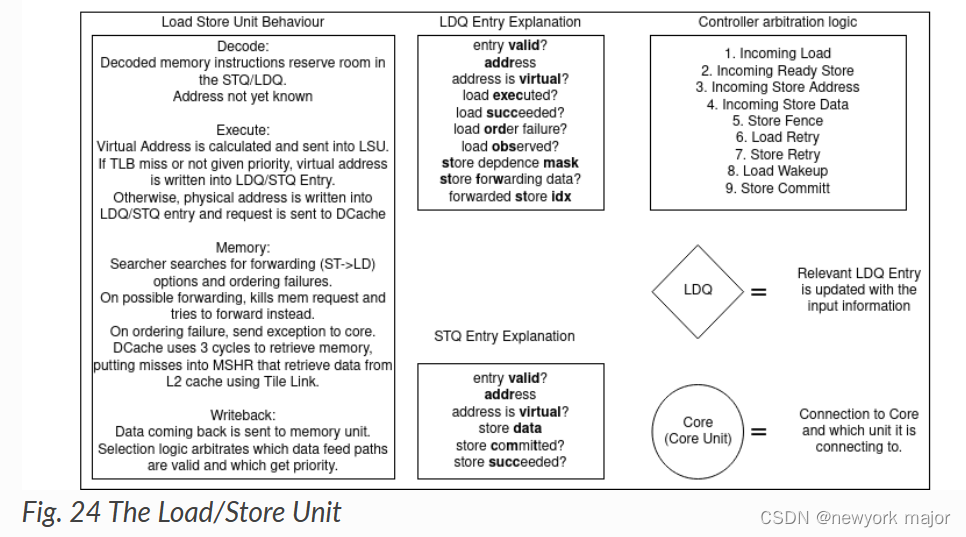
LSU(Load Store Unit)是一个专门的执行单元,负责执行所有的加载(load)和存储(store)指令等,生成load和store操作的虚拟地址,并从内存中加载数据或将数据从寄存器中存储回内存。LSU里一般包括L1 D-cache、D-TLB、AGU、load queue、store queue等模块。
下文以(Berkeley out-of-order machine(BOOM)为例子)
- 负责决定什么时候将memory operations送到memory system;
- load instruction产生uopLD, 会计算出将要访问的地址,并将结果存在LDQ中;
- store instruction会产生两个微指令,uopSTA(store addr generation)和uopSTD(store data generation)
- STA: 计算store的地址,同时将地址存放在STQ中;
- STD:将store data存入STQ中;
- uopLD/STA/STD都是乱序进行的;
Store Instructions
- 在decode stage, 会申请store queue entry; (stq[i].valid = 1);
- 每个valid bit对应两个其他的valid, 分别是
- valid addr(stq[i].bits.addr.valid);
- valid data(stq[i].bits.data.valid);
- 当store instruction提交了,则对应的store queue中的entry也被标记成commited, 可以在合适的时候,将其释放掉;
- store queue中的entry, 是按照PO的顺序,给到memory系统中;
Store Micro-Op
- store是作为一条单独的指令插入到issue window中;而不是被分解为单独的addr-gen和data-gen UOP);
- 这样做的好处是不会浪费昂贵的issue window entries, 也不会给送往LSU的issue ports带来额外的竞争问题;
- 两个操作数都准备好的store可以作为一个UOP发送给LSU, UOP同时向LSU提供地址和数据。
- 虽然这要求存储指令能够访问两个寄存器文件的读端口,但这样做是为了不让store-heavy code的性能降低一半。
- Sequences involving stores to the stack should operate at IPC=1!
- 然而,通常在store addr知晓之前,就知道store addr。
- store addr应该尽快放到STQ,可以使得后续进来的load, 能够进行冲突检查,以避免任何内存排序失败。
- 因此,issue windows会根据需要发出uopSTA或uopSTD UOP s,然后等待第二个操作数准备好。
Load Instructions
- 在decode stage申请LDQ entry;
- 在decode stage,每个load entry会带一个store mask信息,ldq[i].bits.st_dep_mask, 这个标志记录了当前这条load, 依赖于STQ中的哪些store instruction;
- 当store fired to memory,and leaves the Store Queue, 对应的mask标志被清除;
- 当load对应的地址被计算出来,放入LDQ后,ldq[i].addr.valid =1;
- load指令在LDQ中的执行过程:
- load inst到达LSU后,会尽快的送到memory system中;
- 这样的做法,对于乱序pipeline有巨大的好处;
- load指令,会和store queue中的entry, 进行地址比较,检查是否依赖于store addr;
- 如果match, 则memory request会被kill掉;
- 如果对应的store data已经存在,在store data会forwarded to load,load标记为完成;
- 如过对应的store data不存在,则load会sleep, 稍后会再次进行访问memory的申请;
The BOOM Memory Model
- 遵循RVWMO memory consistency model;
- Write -> Read constraint is relaxed (newer loads may execute before older stores).
- Read -> Read constraint is maintained (loads to the same address appear in order).
- A thread can read its own writes early.
- ordering loads to the same addr;
- RVWMO要求,loads to the same addr should be orded;
- 这就要求,每个load,需要和其他的load做检查,看是否有冲突的地址;
- 如果younger load在older load之前已经执行,则younger load将会被replay, 其后面的指令,也要在pipeline中被flush掉;
- 这种场景,出现在当memory coherence的snoop,能够探测到core‘s memory时,并将这种reorder暴露给其他的threads时,需要处理,否则,这种reoder也是ok的;
Memory Ordering Failures
考虑如下的场景:

- 如果X2和X4的物理地址相同,那么load实际上应该是依赖于之前的store; 如果load先执行,那么就会读到错误的数据,此时称之为发生了memory ordering failure;
- 一旦发生了memory ordering failure,则pipeline必须flush, RAT也要重置,这是相当expensive 的operation;

















 1716
1716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









