






背景
在进行数据建模时(有时也叫训练模型),我们需要先经过数据清洗、特征选择与特征构造等预处理步骤,然后构造一个模型进行训练,其中One-Hot编码属于数据清洗步骤里面。
One-Hot意义
在进行特征处理时,分类数据和顺序数据这种字符型变量,无法直接用于计算,那么就需要进行数值化处理。其中分类数据,比如一个特征包含红(R),绿(G),蓝(B)3个分类,那么怎么给这3个分类进行数值化处理呢,可以直接用1,2,3来表示吗,肯定不行,如果用1,2,3表示,那么3种颜色之间就会产生等级差异,本来他们之间应该是平等的,这时就需要进行one-hot编码(哑变量),如下图所示的转换
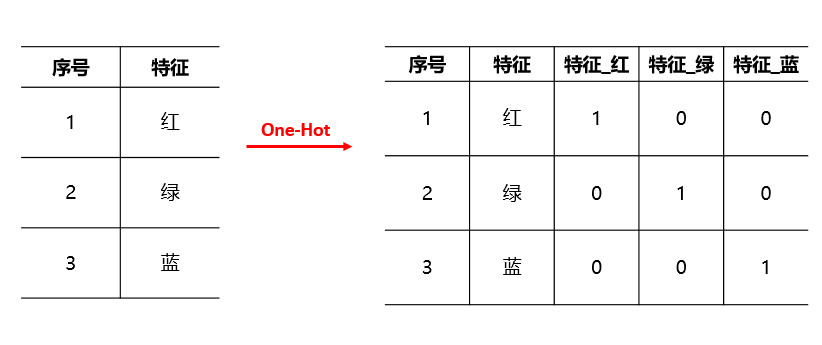
one-hot
实操数据
利用西瓜数据集(部分特征)为例进行实操,这个数据在网上都可下载到

西瓜数据集
读取西瓜数据到数据框里面
import pandas as pd
data = pd.read_excel('西瓜数据集.xlsx', sheet_name='西瓜')
data.head()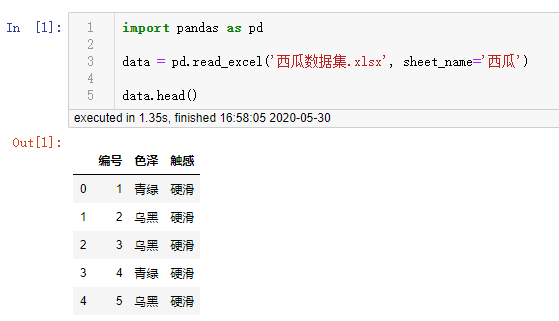
读取西瓜数据
常用方法
- pandas里面的get_dummies方法
这个方法是最简单,最直接的方法
#也可以用concat,join
data_onehot=data.merge(pd.get_dummies(data,columns=['色泽','触感']),on='编号')
data_onehot.head()
pd.get_dummies
- sklearn里面的One-HotEncoder方法
利用One-HotEncoder进行转换
from sklearn.preprocessing import OneHotEncoder
one_hot=OneHotEncoder()
data_temp=pd.DataFrame(one_hot.fit_transform(data[['色泽','触感']]).toarray(),
columns=one_hot.get_feature_names(['色泽','触感']),dtype='int32')
data_onehot=pd.concat((data,data_temp),axis=1) #也可以用merge,join
data_onehot.head()
OneHotEncoder
- 自定义函数方法
def OneHot(df,columns):
df_new=df.copy()
for column in columns:
value_sets=df_new[column].unique()
for value_unique in value_sets:
col_name_new=column+'_'+value_unique
df_new[col_name_new]=(df_new[column]==value_unique)
df_new[col_name_new]=df_new[col_name_new].astype('int32')
return df_new
data_onehot_def=OneHot(data,columns=['色泽','触感'])
data_onehot_def.head()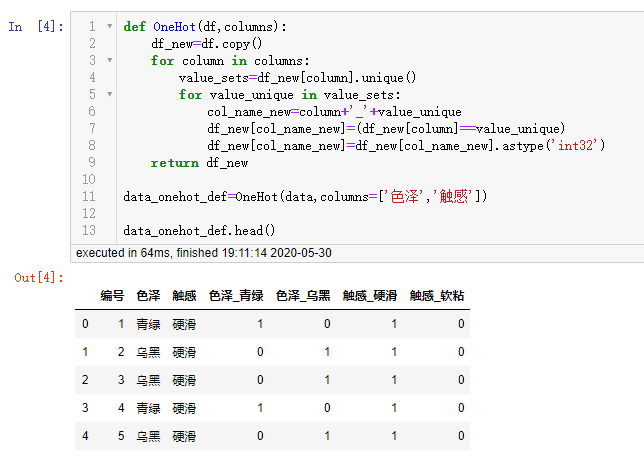
OneHot_def















 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











