






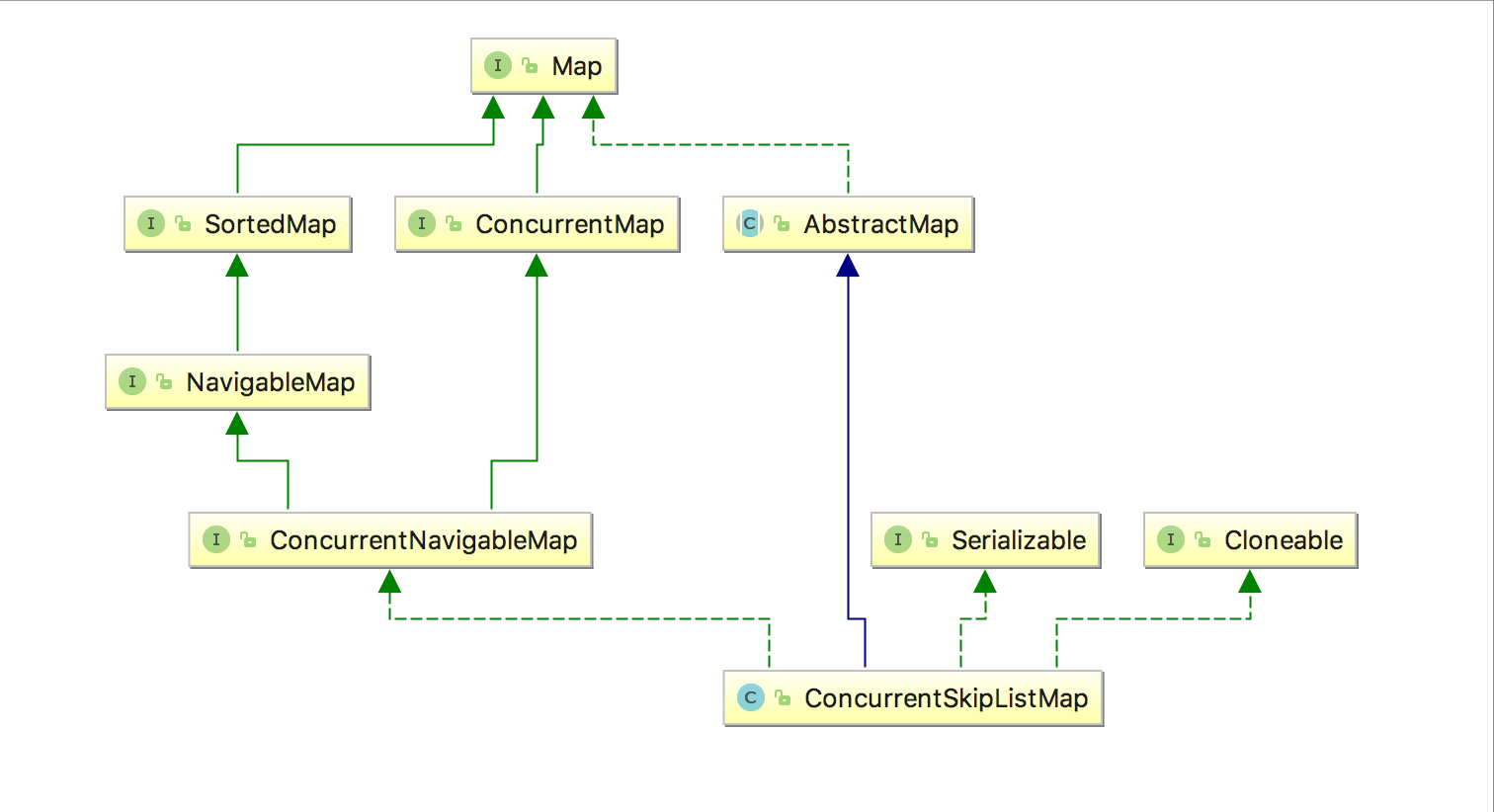
看一下跳跃表的示意图,途中蓝色的为头节点,头节点指向的是普通索引节点
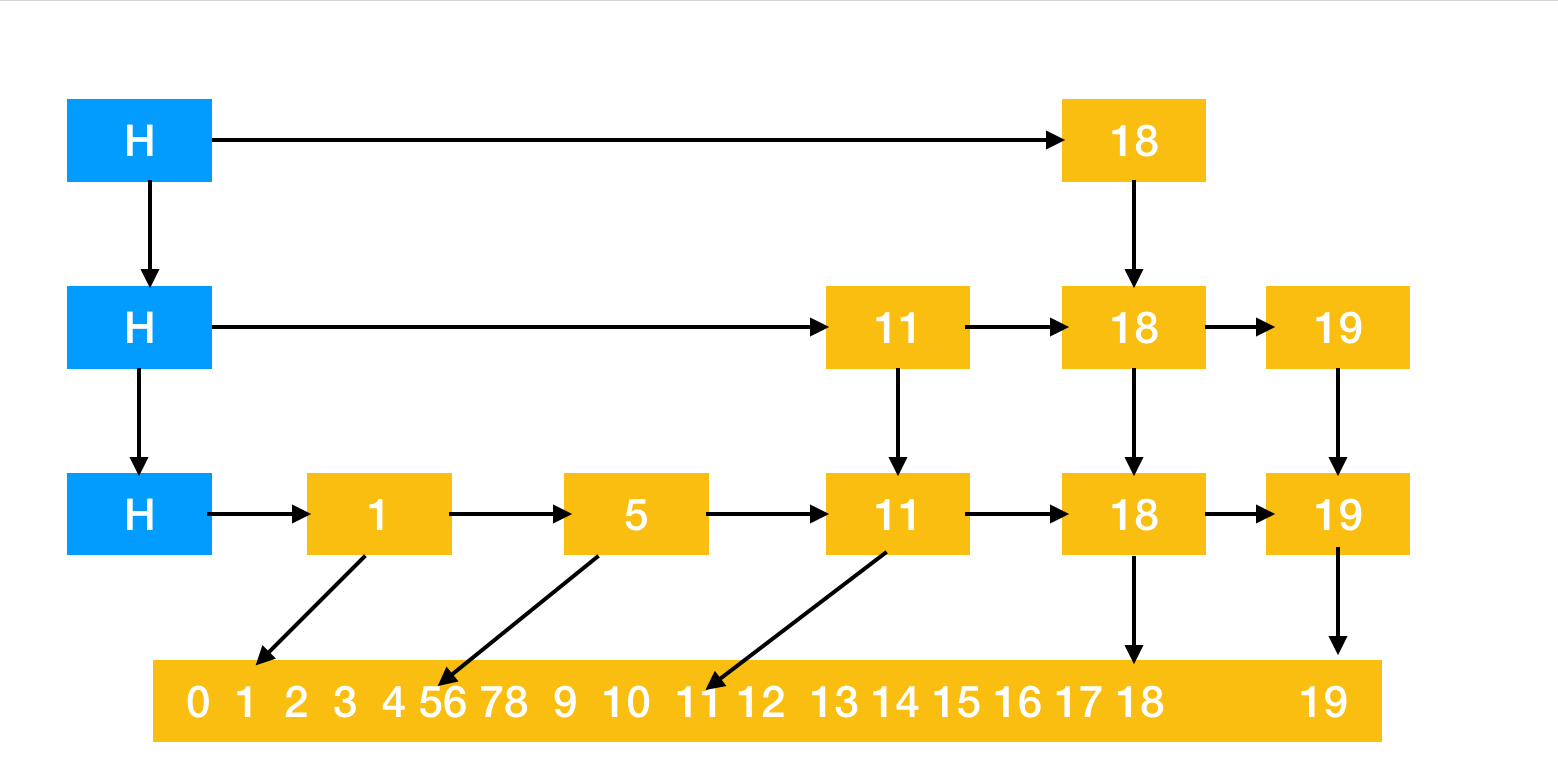
通过上图可以看到跳跃表的基本结构,下面分析一下普通索引节点和头节点的源码,可以发现头节点和普通索引节点的区别就是头节点有level的概念,而普通索引节点没有
static class Index<K,V> {
//索引持有的数据节点
final Node<K,V> node;
//下一层索引
final Index<K,V> down;
//右侧索引
volatile Index<K,V> right;
//对指定数据节点,下一层索引以及右侧索引创建一个新索引
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
//CAS更新右侧索引
final boolean casRight(Index<K,V> cmp, Index<K,V> val) {
return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val);
}
//判断当前节点是否是删除节点
final boolean indexesDeletedNode() {
return node.value == null;
}
//将newSucc节点插入到当前节点与succ节点之间
final boolean link(Index<K,V> succ, Index<K,V> newSucc) {
Node<K,V> n = node;
//新索引节点的右侧索引指向succ
newSucc.right = succ;
//如果当前节点不是删除节点,则cas更新右侧索引指向newSucc
return n.value != null && casRight(succ, newSucc);
}
//删除succ
final boolean unlink(Index<K,V> succ) {
return node.value != null && casRight(succ, succ.right);
}
private static final sun.misc.Unsafe UNSAFE;
private static final long rightOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Index.class;
rightOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("right"));
} catch (Exception e) {
throw new Error(e);
}
}
}
//头节点,只有头节点才有层级概念
static final class HeadIndex<K,V> extends Index<K,V> {
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
public V put(K key, V value) {
//如果value为null则抛出空指针异常
if (value == null)
throw new NullPointerException();
//添加数据
return doPut(key, value, false);
}
private V doPut(K key, V value, boolean onlyIfAbsent) {
//声明一个需要添加到节点
Node<K,V> z;
//如果key为null则抛出一个NPE
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
//对当前key找到前驱
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
//如果b的后继不为null
if (n != null) {
Object v; int c;
//n的后继节点
Node<K,V> f = n.next;
//再次判断n是不是b的后继,如果不是则跳出循环(一致性读)
if (n != b.next)
break;
//如果n节点已经被删除则跳出循环
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
//如果b节点被删除则跳出循环
if (b.value == null || v == n)
break;
//如果key大于n节点的key则继续向后找
if ((c = cpr(cmp, key, n.key)) > 0) {
b = n;
n = f;
continue;
}
//如果找到了key相等的节点
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
break; //CAS竞争失败则继续
}
// else c < 0; fall through
}
//如果后继节点为null则可以直接添加
z = new Node<K,V>(key, value, n);
//CAS设置失败则跳出内层循环,继续执行
if (!b.casNext(n, z))
break;
//CAS成功则跳出外层循环
break outer;
}
}
int rnd = ThreadLocalRandom.nextSecondarySeed();
//与10000000000000000000000000000001按位与的结果为0,表示最高位和最低位不为1
if ((rnd & 0x80000001) == 0) {
int level = 1, max;
//随机数从左到右连续有几个1,则level自增几次
while (((rnd >>>= 1) & 1) != 0)
++level;
Index<K,V> idx = null;
HeadIndex<K,V> h = head;
//如果level小于等于head节点的层级,则逐层创建索引且down之前idx
if (level <= (max = h.level)) {
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null);
}
else { //如果level大于head的层级
//将level设置为max+1,即head的层级+1
level = max + 1;
//创建新的索引数组
Index<K,V>[] idxs =
(Index<K,V>[])new Index<?,?>[level+1];
//对索引数组进行赋值,0不使用,并将down指向前一个节点
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
for (;;) {
h = head;
int oldLevel = h.level;
if (level <= oldLevel) //如果当前level小于oldLevel则跳出
break;
HeadIndex<K,V> newh = h;
Node<K,V> oldbase = h.node;
//对新增的层级生产头节点
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
//cas赋值头节点
if (casHead(h, newh)) {
//将最新头节点赋值给h
h = newh;
//idx为之前的头节点
idx = idxs[level = oldLevel];
break;
}
}
}
// 找到插入点,并插入数据
splice: for (int insertionLevel = level;;) {
//level为之前头节点的层级,j为新头节点的层级
int j = h.level;
for (Index<K,V> q = h, r = q.right, t = idx;;) {
//如果新头节点,或者老头节点为null则跳出外层循环
if (q == null || t == null)
break splice;
//r为新头节点的右节点,如果不为null
if (r != null) {
//r索引持有的节点
Node<K,V> n = r.node;
//当前key和r索引持有的key进行比较
int c = cpr(cmp, key, n.key);
//如果n的值为null,则删除该节点,如果删除失败则重新循环
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
//如果key>n.key 则继续向后查找
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
// 表示r为null,即找到该层的最后
//如果是需要插入的层级
if (j == insertionLevel) {
//将t插入到q,r之间失败则重新开始
if (!q.link(r, t))
break;
//插入成功,如果t的值为null,则需要删除
if (t.node.value == null) {
findNode(key);
break splice;
}
//如果到最低层则跳出外层循环
if (--insertionLevel == 0)
break splice;
}
//如果 --j 大于等于insertLevel则继续处理下一层
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
//如果key为null则抛出NPE
if (key == null)
throw new NullPointerException(); // don't postpone errors
for (;;) {
// q初始化为头索引节点,r为索引节点右侧索引节点
for (Index<K,V> q = head, r = q.right, d;;) {
//如果r不为nul
if (r != null) {
//r索引节点持有的数据节点
Node<K,V> n = r.node;
//该数据节点的key
K k = n.key;
//如果n的值为nul则表示该索引节点需要删除
if (n.value == null) {
//删除索引节点,删除失败则重新开始
if (!q.unlink(r))
break;
//删除成功后r为q的新右侧索引节点
r = q.right;
continue;
}
//r节点不是删除节点则比较key大小,r索引持有的key小于新插入的key则继续向右移
if (cpr(cmp, key, k) > 0) {
q = r;
r = r.right;
continue;
}
}
//表示r为null或者r节点持有的数据key大于新插入数据的key
//如果q下一层为null则直接返回q持有的数据节点
if ((d = q.down) == null)
return q.node;
//如果q.down不为null,则向下一层查找
q = d;
r = d.right;
}
}
}
public V get(Object key) {
return doGet(key);
}
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
//b根据key找到的前驱节点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
//如果b的后继为null则跳出外层循环返回null
if (n == null)
break outer;
//f为n的后继节点
Node<K,V> f = n.next;
//如果n不是b的后继则跳出循环重新开始
if (n != b.next)
break;
//如果n节点是需要删除节点则删除重新开始
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
//如果b节点是删除节点重新开始
if (b.value == null || v == n)
break;
//和n节点的key对比,如果相等则返回值
if ((c = cpr(cmp, key, n.key)) == 0) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
//如果小于n节点的key则返回null( 因为key>p.key)
if (c < 0)
break outer;
//否则继续向后查询
b = n;
n = f;
}
}
return null;
}















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











