






目录
1 主要内容
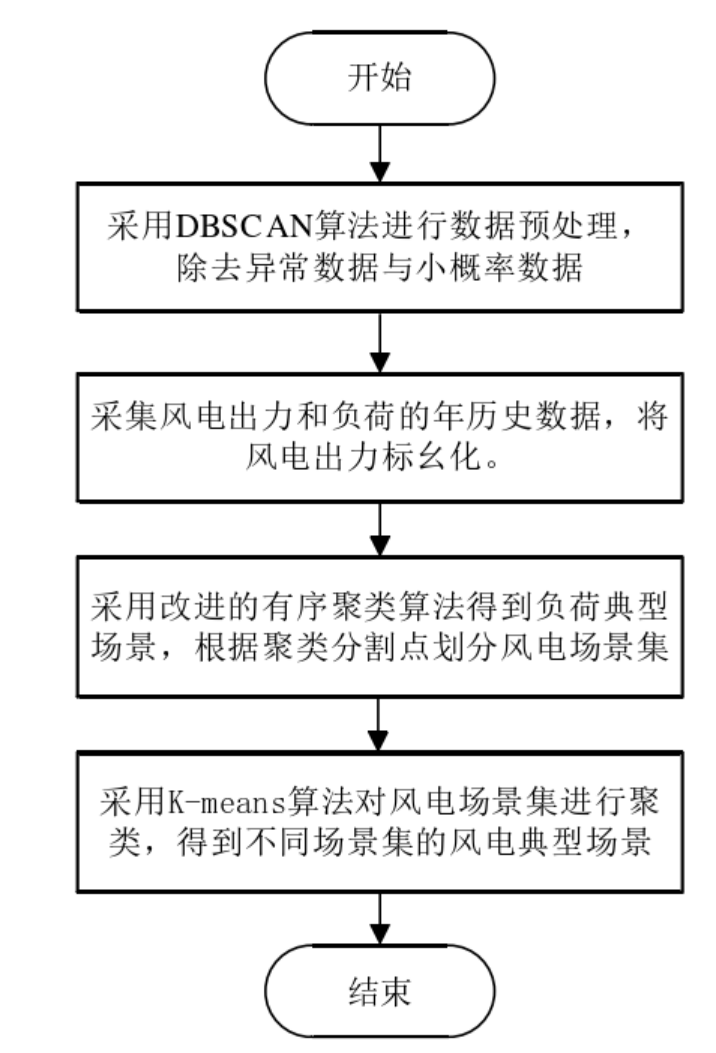
该程序复现文章《氢能支撑的风-燃气耦合低碳微网容量优化配置研究》第三章内容,实现的是基于DBSCAN密度聚类的风电-负荷场景生成与削减模型,首先,采集风电、电负荷历史数据。然后,通过采用 DBSCAN 密度聚类的数据预处理消除异常或小概率电负荷、风电数据。之后,针对风电波动性与电负荷时序性、周期性特点,将场景提取分为电负荷场景提取和风电场景提取。该方法较传统聚类和场景削减方法有更好的数据预处理过程,这样就能消除异常数据,得到更准确的聚类结果。

基于密度聚类的数据预处理:
DBSCAN是基于一组邻域来描述样本集的紧密程度的算法。DBSCAN需要二个参 数值,扫描半径(E)和最小包含点数(MinPts),用来描述邻域的样本分布紧密程度。其中,E描述了某一样本的邻域距离阈值,给定对象以E为半径的区域被称为该对象的 E邻域。MinPts描述了某一样本的距离为E的邻域中样本个数的阈值。如果给定对象E 邻域内的样本点数大于等于MinPts,则称该对象为核心对象。不属于核心对象及核心对 象E邻域内的点为噪声点。
场景提取:
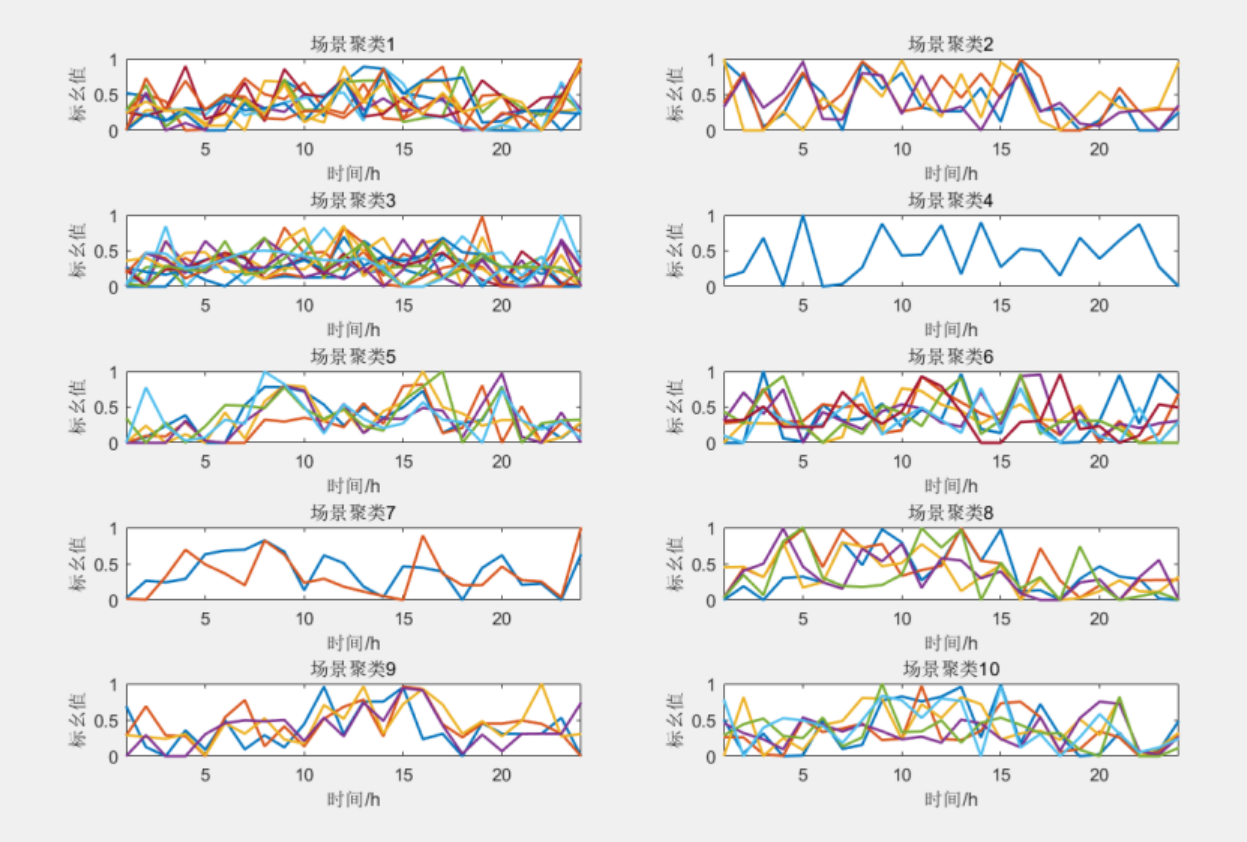
1.负荷采用改进有序聚类方法进行提取。
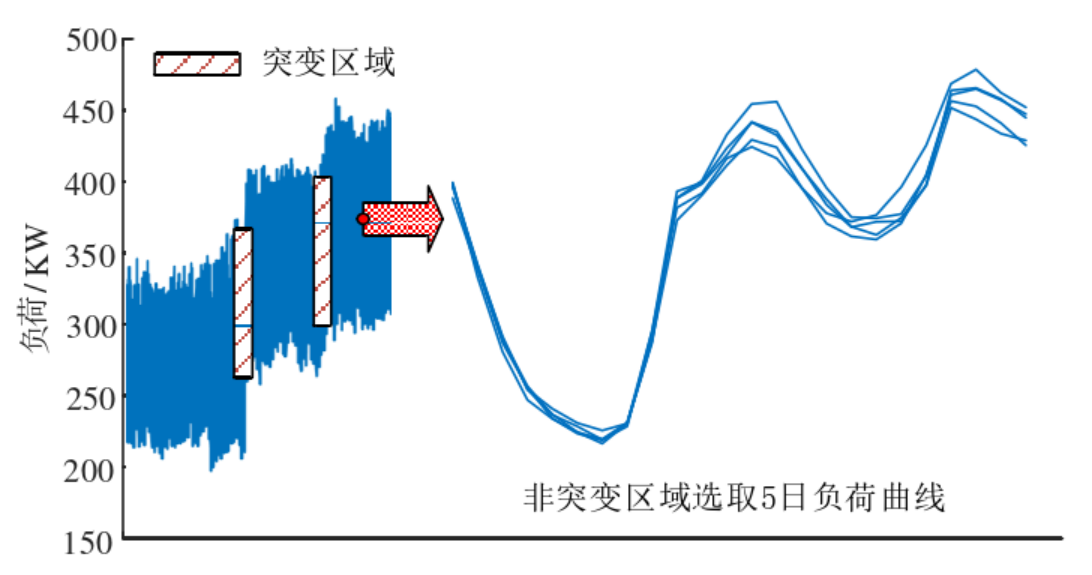
以天为单位的电负荷场景在时间上存在连续性,而连续的电负荷场景从向量的角度 分析又具有相似性,直到出现某一个突变点,电负荷数据大小会发生大幅度变化,然后 电负荷数据变化又会开始稳定。电负荷数据的这种周期性波动与变化适 合通过有序聚类进行分类。
2.风电采用K-means聚类方法进行提取。

算法流程:
2 部分程序
clc
clear all
%% 导入数据
X=xlsread('风电');
x0=X;
y=xlsread('负荷数据');
figure;
subplot(2,1,1);
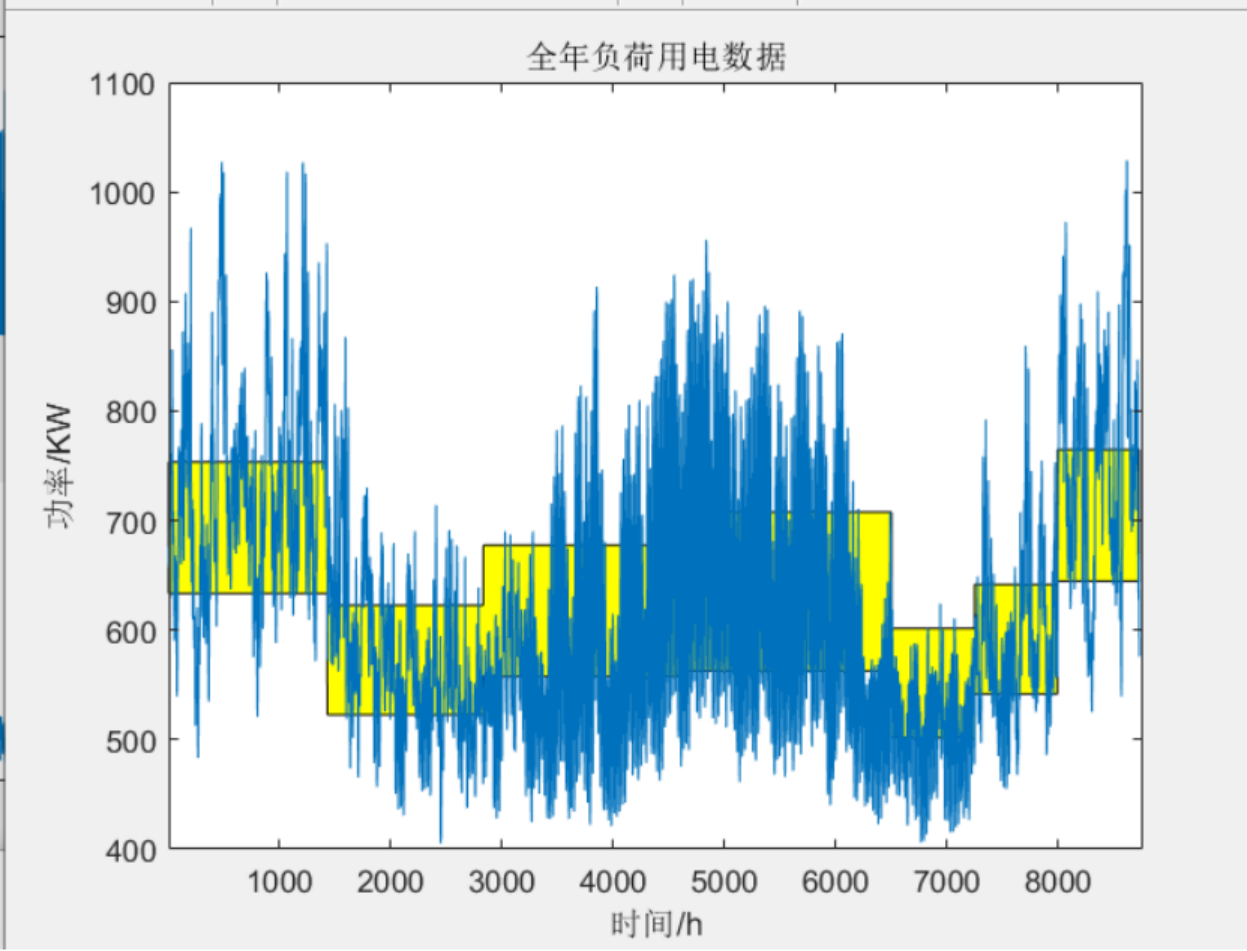
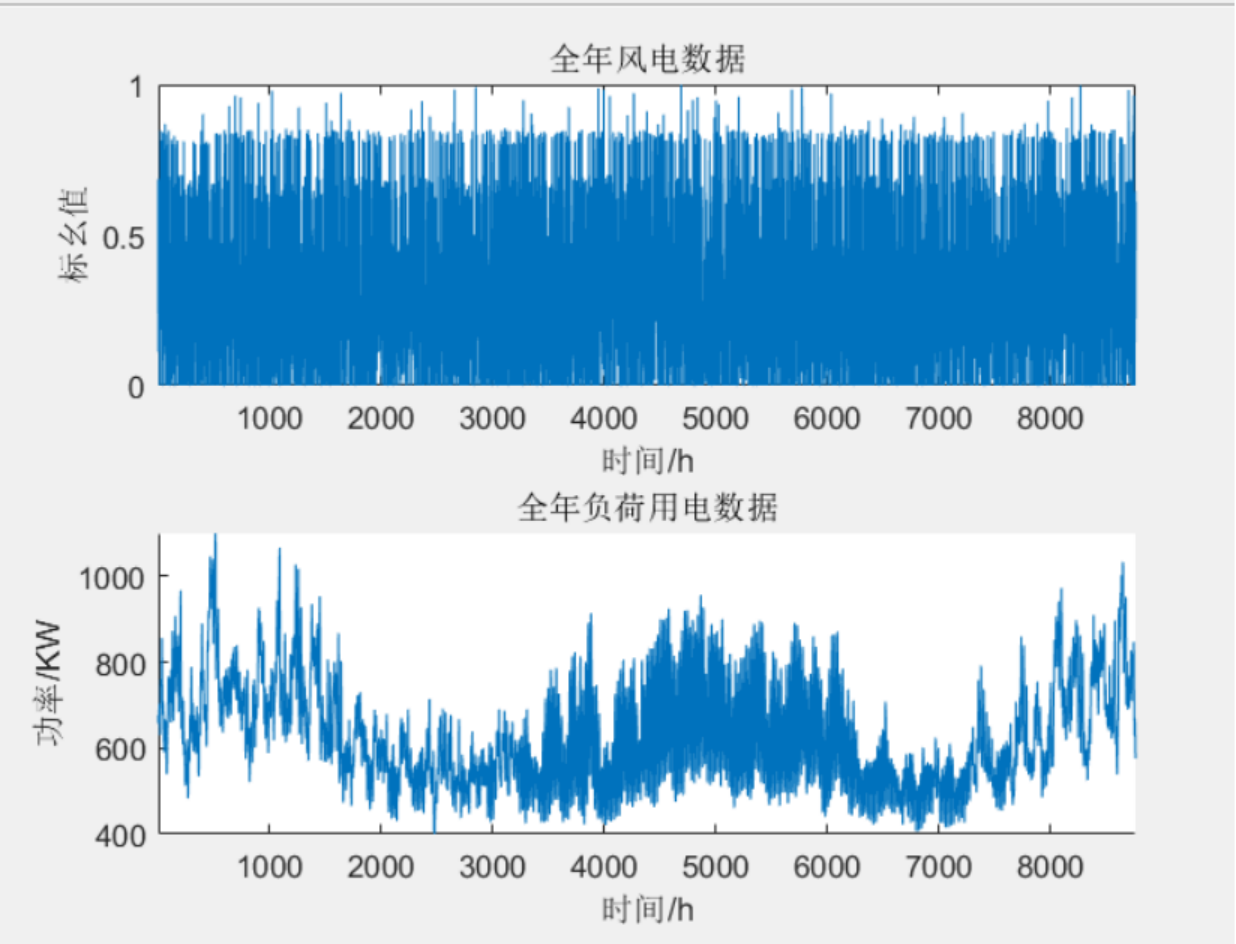
plot(X);xlabel('时间/h');ylabel('标幺值');title('全年风电数据');axis([1 8761 0 1])
subplot(2,1,2);hold on
plot(y);xlabel('时间/h');ylabel('功率/KW');title('全年负荷用电数据');axis([1 8761 400 1100]);
%% 变量设定
k = 3;
Eps = 2;
data = [X,y];Ti=1:8761;
%% 准备变量,输出原始结果
[m,n] = size(data);
data=[(1:m)',data]; %%增加一列表示序号
n = n + 1; %%增加后列数+1
type = zeros(1,m);
cluster_No = 1;
visited = zeros(m,1);
class = zeros(1,m)-2;
figure(2);
subplot(2,1,1);
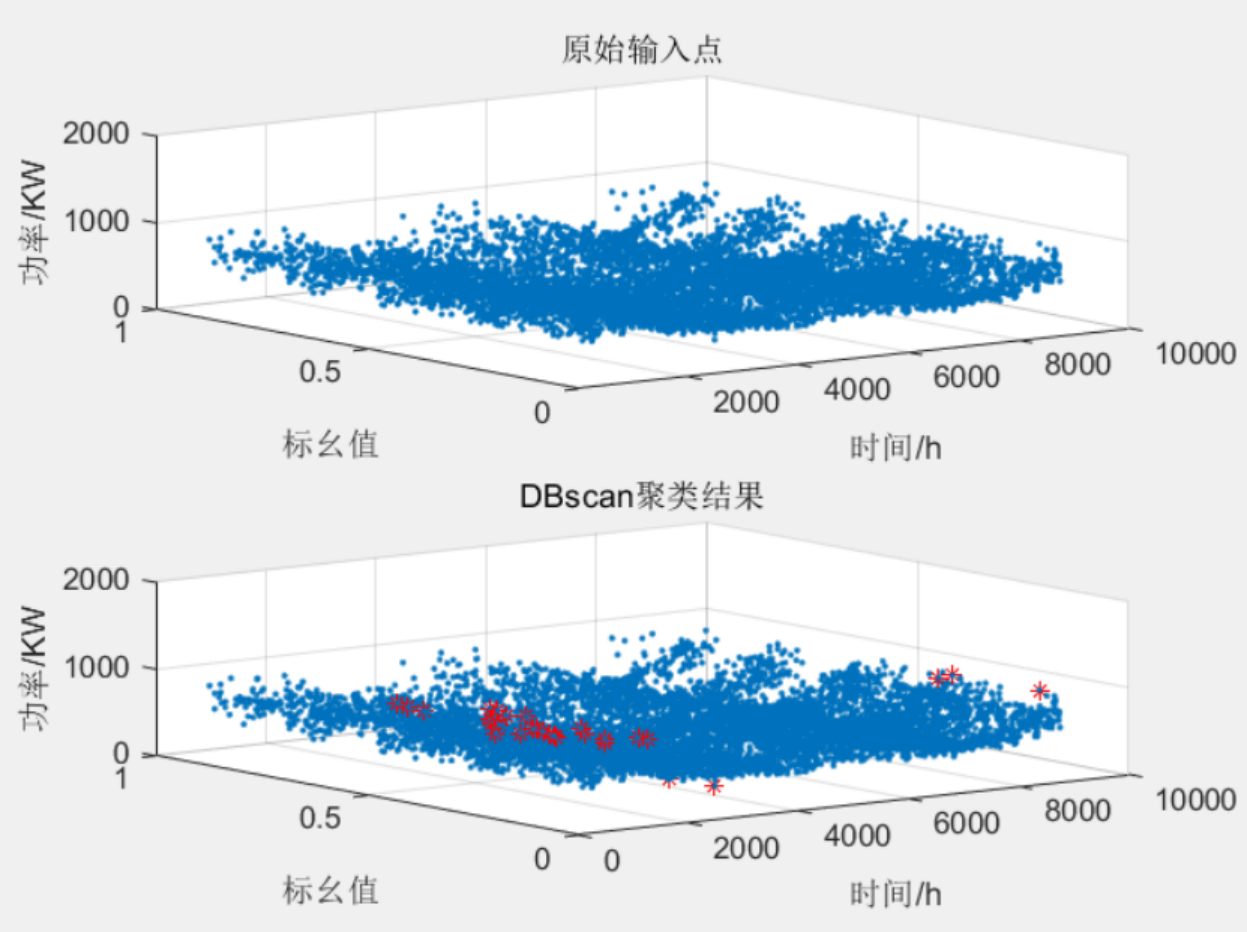
plot3(Ti,data(:,2),data(:,3),'.');axis([1,10000,0,1,0,2000]); xlabel('时间/h');ylabel('标幺值');zlabel('功率/KW');%%绘制时间-风电-负荷的三维图
grid on
%daspect([1 1 1]);
%xlabel('x');ylabel('y');
title('原始输入点');
hold on;
%% 运行DBSCAN算法
Kdtree = KDTreeSearcher(data(:,2:3)); %%使用训练数据(data)的m×n数字矩阵来生长默认的Kd树(Mdl)
for i = 1:m
% 抽取一个未访问点
if visited(i)==0
% 标为访问
visited(i) = 1;
point_now = data(i,:);
Idx_range = rangesearch(Kdtree, point_now(2:3), Eps); %%使用rangesearch进行半径搜索来搜索存储的树以找到查询数据的所有相邻点
index = Idx_range{1};
if length(index) > k
class(i) = cluster_No;
while index
if visited(index(1)) == 0
visited(index(1)) = 1; %% 标为访问
if class(index(1)) <= 0
class(index(1)) = cluster_No;
end
point_now = data(index(1),:);
Idx_range = rangesearch(Kdtree, point_now(2:3), Eps);
index_temp = Idx_range{1};
index(1) = [];
if length(index_temp) > k
index = [index, index_temp];
end
else
index(1) = [];
end
end
cluster_No = cluster_No + 1;
end
end
end
%% DBSCAN聚类结果
3 程序结果

















 2035
2035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











