







递归的形式大概如下:
public int GetResult(int n){
if(n==0){ //递归退出条件
return 0; //这里返回的是当n=0的时候得到的值,而不是所有值的和
}
for( i...){ //遍历每一种可能
GetResult(n-i);
}
return s1+s2+s3; //这里返回的是所有可能相加得到的值的和
}
遍历的形式如下:
public int GetResult(int n){
while(true){
if(){
break; //跳出循环
}
for( i...){ //如果这里有多个可能性,那么要for遍历下各种可能性
....
n=n-i;
}
}
}
动态规划:
和分治法相似,分治法是将问题划分成互不相交的子问题求解,递归求解子问题,再将解组合起来,动态规划是子问题有重叠的情况,两个不同的子问题下面有求同一个小问题,动态规划把重叠的小问题只求解一次保存在表格中,
贪心算法:
它在每一步做出当时看上去最优的解,通过做出局部最优解来得到全局最优解
对于实时的排队系统,虽然用数组也可以,但是考虑溢出问题和增加删除后的数据移动,很不方便
因此数组的长度是分配后不变的,线性表的长度是动态的
数据的存储形式分为顺序存储和链式存储。
int count=1;
while(count<n)
{
count=count*2;
}
这里由于2的x次幂=n所以x=log2(n)因此时间复杂度为O(logn)
一个线性表插入元素的时候,从最后一位到当前插入点遍历,i减减,每个元素向后移动一位,如果是i++;那么向后移动的话会把后面的元素覆盖掉,所以从后向前移动
数组和链表的区别:

对于插入和删除一个元素时,数组找到第i个元素只需一步,但是插入和删除需要把后面的全部移动一位,所以时间复杂度为O(n)
链表找到第i个元素必须从第一个元素开始向后找,所以时间复杂度为O(n)找到后插入删除操作只需一步
但是插入删除频繁时链表的优势就明显了
因此对于读取查找频繁操作,用数组这种顺序存储结构,对于插入删除频繁,用链表
对一个排序过的二叉树,进行中序遍历可以得到有序的序列,我们叫做二叉排序树
二分查找:传入数组长度,找到起点和终点,计算中点,如果目标值比中点的值大,把中点设为起点,递归后半段,否则把中点设为终点递归前半段。
缺点:必须是排序过的数组才能进行二分查找,对于频繁插入和删除需要继续排序,所以麻烦
插值查找:关键字分布比较均匀,插值查找比折半好一些。
冒泡排序:假设数组大小为9,比较9和8的值,把小的放到8号上,比较8和7的值,把小的放到7号上,循环到2和1上,这样第一次循环把最小的数放到了1号为,第二遍遍历,继续比较9和8的值。。。直到比较3和2的值,把倒数第二小的数放到2号位,这样一直遍历
for(int i=0;i<length;i++){
for(int j=length;j>=i;j++){
if(str[j]<str[j-1]){
change(j,j-1);
}
} }
2层for循环,所以时间复杂度O(n2)
简单选择排序:不像冒泡只要小于就交换,它是在第一层for循环里面设了一个最小值,取出第二层遍历的最小值,交换
希尔排序:

将待排序数组按照步长gap进行分组,然后将每组的元素利用直接插入排序的方法进行排序;每次将gap折半减小,循环上述操作;当gap=1时,利用直接插入,完成排序。
时间复杂度O(n2/3)不稳定
堆排序:任意的叶子节点小于(或大于)它所有的父节点。对此,又分为大顶堆和小顶堆,大顶堆要求节点的元素都要大于其孩子,小顶堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求。
构造大/小顶堆:有n个数,那么有n/2个根节点,让根节点大/小于左右孩子节点,最上面节点当然是最大/小的
重建堆:构建好后,把最顶端的节点移除,把序号最后的节点放到最顶端的节点,重新构造大/小顶堆
时间复杂度O(nlogn)
归并排序:
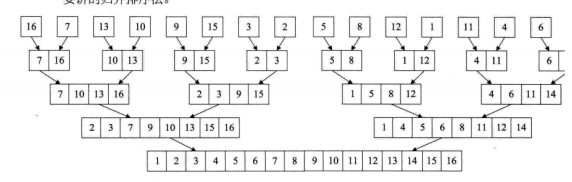
归并排序分为拆分和合并,拆分把序列一直对半拆,拆到只剩1个元素为止,合并是把两个对半序列合成排序后的序列,合并的时候这样合:比较左序列第一个和右序列第一个(假如左边的小),把左边第一个放到另一个数组的第一位,继续比较左序列第二个和右序列第一个,把小的放到另一个数组第二位。。这样循环
时间复杂度O(nlogn)
快速排序:
- 从序列当中选择一个基准数(pivot)
在这里我们选择序列当中第一个数最为基准数 - 将序列当中的所有数依次遍历,比基准数大的位于其右侧,比基准数小的位于其左侧
- 重复步骤1.2,直到所有子集当中只有一个元素为止
//快速排序的思想:取出第一个数,比该数小放左边,比该数大放右边,分成左右两个序列,递归 static List<int> GetResult(List<int> list) { //终止条件,list只有1个数的时候推出循环 if (list.Count==1) { return list; } List<int> list3 = new List<int>(); List<int> list4 = new List<int>(); List<int> list5 = new List<int>(); List<int> list6 = new List<int>(); List<int> list7 = new List<int>(); int fistNum = list[0]; //小于第一个元素放左边的list,大于放右边的序列 for (int i = 1; i < list.Count; i++) { if (list[i] < fistNum) { list3.Add(list[i]); } else { list4.Add(list[i]); } } //这里主要是保证不能让最终得到的左边或右边序列为空序列,因为如果为空序列, //递归时候return回去会发现左边序列或右边序列一直是一个空序列无限递归 if (list3.Count==0) { list3.Add(fistNum); }else if (list4.Count == 0) { list4.Add(fistNum); } else { list3.Add(fistNum); } //25, 15, 84, 65, 24, 74, 25, 15, 56, 28, 74, 55 list5 = GetResult(list3); list6 = GetResult(list4); for (int i = 0; i < list6.Count; i++) { list5.Add(list6[i]); } return list5; }
发现这样的代码不好,因为new了许多的list,那么排序数多的话,这么多的list比较消耗资源。我们可以把参数加上起始位置和终止位置,那么一直操作一个序列,在起始位置和终止位置中互换元素
//快速排序的思想:取出第一个数,比该数小放左边,比该数大放右边,分成左右两个序列,递归
static void GetResult(List<int> list,int start,int end)
{
//终止条件,退出循环
if (start==end)
{
return;
}
//
int first = list[start];
int firstIndex = start;
for (int i=start+1;i<=end;i++)
{
if (list[i]<first)
{
//如果第i个数更小,,把firstIndex到第i-1个数向后移动一位,第i个数移动到firstIndex位置,firstIndex设为第firstIndex+1个位置
//这里犯错是第一如果小于,不应该交换两个数而是移动它们,第二firstIndex设为第firstIndex+1个位置,而不是firstIndex和i进行交换
int num = list[i]; //这里很重要,从后向前移动数,那么最后一位要拿变量保存起来
for (int j=i-1;j>=firstIndex;j--)
{
list[j + 1] = list[j];
}
list[firstIndex] = num;
firstIndex ++;
}
}
//25, 15, 84, 65, 24, 74, 25, 15, 56, 28, 74, 55
GetResult(list, start, firstIndex);
//要对后半段进行递归,那么firstIndex + 1是否超过list长度要做判断
if (firstIndex == end)
{
}
else
{
GetResult(list, firstIndex + 1, end);
}
}Paitition算法:
我这里应该把快速排序算法弄错了,把小于第一个数的元素放前面,大于第一个数的所有元素放后面,使用这样的方法,叫做partition算法,上面的代码我是通过把数组移动的方式实现互换的,实际上partition算法没有移动元素而是直接交换的。
partition算法不仅用于快速排序,还用于在无序数组中寻找第K大的值
下面的图片和内容摘自:http://blog.jobbole.com/105219/
第一种paritition算法:
它的思想是取第一个数为目标数,用pos记录比目标数大的元素起始位置(刚开始为1),从第二个数开始遍历,找比目标数小的数,找到,pos++,互换比目标数大的起始位置的数和比目标数小的数。
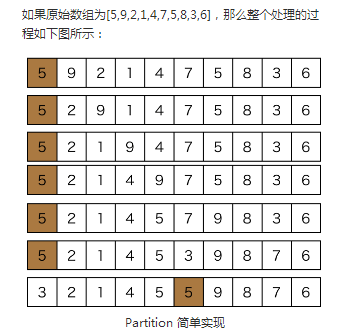
int partition(vector<int>&arr, int begin, int end){
int pivot = arr[begin];
// Last position where puts the no_larger element.
int pos = begin;
for(int i=begin+1; i!=end; i++){
if(arr[i] <= pivot){
pos++;
if(i!=pos){
swap(arr[pos], arr[i]);
}
}
}
swap(arr[begin], arr[pos]);
return pos;
}这种实现思路比较直观,但是其实并不高效。从直观上来分析一下,每个小于pivot的值基本上(除非到现在为止还没有遇见大于pivot的值)都需要一次交换,大于pivot的值(例如上图中的数字9)有可能需要被交换多次才能到达最终的位置。
如果我们考虑用 Two Pointers 的思想,保持头尾两个指针向中间扫描,每次在头部找到大于pivot的值,同时在尾部找到小于pivot的值,然后将它们做一个交换,就可以一次把这两个数字放到最终的位置。一种比较明智的写法如下:
第二种partition算法:
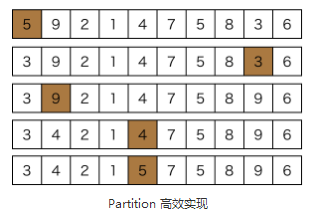
使用变量i和j和target保存从左向右和从右向左的移动坐标和目标数,从右向左找比第一个数小的,有就把第i个数设为该数,i++,再从左向右找比第一个数大的,有就把第j个数设为该数,最后退出循环把第i个数设为target
这段代码也即快速排序采用的代码,也即第二种partition算法,比第一种高效。直观上来看,赋值操作的次数不多,比前面单向扫描的swap次数都少,效率应该会更高
static void quick_sort(int[] arr, int left, int right)
{
if (left < right)
{
int i = left, j = right, target = arr[left];
while (i < j)
{
while (i < j && arr[j] > target)
j--;
if (i < j)
arr[i++] = arr[j];
while (i < j && arr[i] < target)
i++;
if (i < j)
arr[j--] = arr[i];
}
arr[i] = target;
quick_sort(arr, left, i - 1);
quick_sort(arr, i + 1, right);
}
}该算法的时间复杂度O(nlogn)















 2228
2228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









